人脸检测与对齐MTCNN
论文:Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks
论文链接:https://arxiv.org/abs/1604.02878
推荐代码实现mxnet:https://github.com/pangyupo/mxnet_mtcnn_face_detection
最近突然对人脸检测非常感兴趣。根据网上的总结,发现MTCNN的效果应该还蛮不错的,所以仔细研读了这篇论文,在这里总结一下,如果有错误还请批评指正。其中有参考博客https://blog.csdn.net/u014380165/article/details/78906898,里面针对mxnet代码实现部分讲解的非常详细。
1.介绍
MTCNN是一种Multi-task的人脸检测模型,同时进行人脸检测和人脸对齐(即人脸特征点检测)。模型采用了三个CNN级联的方式,并且提出了online hard sample mining方法进行训练。该算法有三个阶段组成:第一阶段,浅层的CNN快速产生候选框;第二阶段,通过更复杂的CNN精炼候选框,丢弃大量的重叠候选框;第三阶段,使用更加强大的CNN,实现候选框去留,同时显示五个面部关键点定位。是一种由粗到细的检测方式。
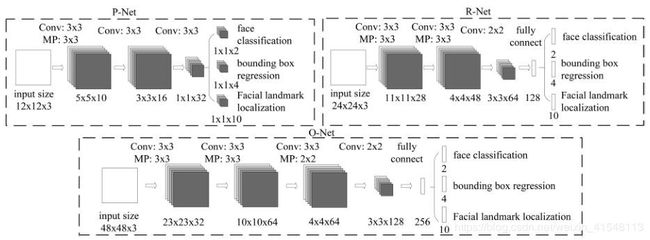
2.网络结构
算法整体流程如下:

起初:先对图像做了multi scale的resize,构成了图像金字塔,然后这些不同scale的图像作为stage1的输入进行训练,目的是为了可以检测不同scale的人脸。
stage1)Proposal Network (P-Net):主要是用来生成候选框(bounding boxes),采用全卷积神经网络,获得候选框和边界回归向量。同时,候选框根据边界框进行校准。然后,利用NMS方法去除重叠窗体。
stage2)Refine Network (R-Net):主要用来去除大量的非人脸框。这一步的输入是前面P-Net生成的bounding box,通过resize操作调整每个bounding box的大小都是24*24。同样在测试的时候这一步的输出只有M个bounding box的4个坐标信息和score,继续使用Bounding box regression和NMS合并,由于比P-Net多了一个全连接层,所以可以更好的去掉那些false-positive区域。
stage3)Output Network (O-Net):该层在R-Net的基础上多了一层卷积层,所以处理的结果会更加精细。作用和R-Net层作用一样。输入的是R-net输出的bounding box,大小调整为48*48,输出包含P个bounding box的4个坐标信息、score和关键点(landmark)信息。
详细的网络结构如下:
3.模型训练
在网络结构中,可以看出,模型训练分为三部分,分别为人脸分类训练,bbox坐标回归训练,landmark定位训练。
1)人脸分类
是一个二分类任务,采用交叉熵损失函数,其yi表示预测值,yi_det表示真实值。

2)bbox坐标回归训练
通过欧式距离来计算回归损失,其中y为一个(左上角x,左上角y,长,宽)组成的四元组,y_hat表示网络预测值,y表示真实边框的坐标。

3)landmark定位训练
和边框坐标回归一样,计算网络预测的特征点位置和实际真实特征点位置的欧式距离,并最小化该距离。其中y_hat为通过网络预测得到,y为实际的真实的特征点坐标。一个有五个特征点,所以y属于十元组。

4)多任务训练
可想而知,并不是每个输入都要经历上述三次损失训练,比如只含有背景的bbox只需要经历交叉熵损失训练结课,不需要经历其他损失。所以引入了下面的公式来针对不同的输入计算不同的损失。

 表示任务的重要性,
表示任务的重要性, 表示样本标签(在于标记非人脸的输入,只需要计算分类损失)。可见在P-Net和R-Net中,关键点的损失权重(α)要小于O-Net部分,这是因为前两个极端重点在于过滤掉非人脸的bbox。
表示样本标签(在于标记非人脸的输入,只需要计算分类损失)。可见在P-Net和R-Net中,关键点的损失权重(α)要小于O-Net部分,这是因为前两个极端重点在于过滤掉非人脸的bbox。
5)online hard sample mining
本文采用online hard sample mining的方法。具体的方法是在每个mini-batch中,取loss最大的70%样本进行反向传播,忽略那些简单的样本。重点针对那些很难被分类的样本,使得每次传播的数据都是非常有效的。
4.实验部分
论文使用三个数据集进行训练:FDDB,Wider Face,AFLW
为了更好地进行上述三种训练,本文将数据分成4种:
Negative:非人脸
Positive:人脸
Part faces:部分人脸
Landmark face:标记好特征点的人脸
Negative和Positive用于人脸分类,positive和part faces用于bounding box regression,landmark face用于特征点定位。
5.总结
本文的人脸检测和人脸特征点定位的效果都非常好。关键是这个算法速度很快,在2.6GHZ的CPU上达到16fps,在Nvidia Titan达到99fps。
本文使用一种级联的结构进行人脸检测和特征点检测,而且提出了一种有效的训练方法online hard sample mining,运行速度较快,可以考虑在移动设备上使用。