pytorch中Dropout与L1和L2正则化
Dropout原理
- 算法概述
我们知道如果要训练一个大型的网络,训练数据很少的话,那么很容易引起过拟合(也就是在测试集上的精度很低),可能我们会想到用L2正则化、或者减小网络规模。然而深度学习领域大神Hinton,在2012年文献:《Improving neural networks by preventing co-adaptation of feature detectors》提出了,在每次训练的时候,让一半的特征检测器停过工作,这样可以提高网络的泛化能力,Hinton又把它称之为dropout。
Hinton认为过拟合,可以通过阻止某些特征的协同作用来缓解。在每次训练的时候,每个神经元有百分之50的几率被移除,这样可以让一个神经元的出现不应该依赖于另外一个神经元。
另外,我们可以把dropout理解为 模型平均。 假设我们要实现一个图片分类任务,我们设计出了100000个网络,这100000个网络,我们可以设计得各不相同,然后我们对这100000个网络进行训练,训练完后我们采用平均的方法,进行预测,这样肯定可以提高网络的泛化能力,或者说可以防止过拟合,因为这100000个网络,它们各不相同,可以提高网络的稳定性。而所谓的dropout我们可以这么理解,这n个网络,它们权值共享,并且具有相同的网络层数(这样可以大大减小计算量)。我们每次dropout后,网络模型都可以看成是整个网络的子网络。(需要注意的是如果采用dropout,训练时间大大延长,但是对测试阶段没影响)。
啰嗦了这么多,那么到底是怎么实现的?Dropout说的简单一点就是我们让在前向传导的时候,让某个神经元的激活值以一定的概率p,让其停止工作,示意图如下:

左边是原来的神经网络,右边是采用Dropout后的网络。这个说是这么说,但是具体代码层面是怎么实现的?怎么让某个神经元以一定的概率停止工作?这个我想很多人还不是很了解,代码层面的实现方法,下面就讲解一下其代码层面的实现。以前我们网络的计算公式是:
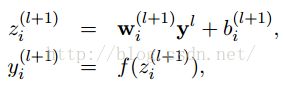
采用dropout后计算公式就变成了:
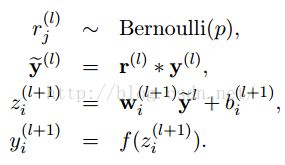
上面公式中Bernoulli函数,是为了以概率p,随机生成一个0、1的向量。
- pytorch实现dropout
import torch
from torch.autograd import Variable
import matplotlib.pyplot as plt
torch.manual_seed(1)
DATA_SIZE = 10
# training set
x = torch.unsqueeze(torch.linspace(-1, 1, DATA_SIZE), dim=1) # sieze (20,1)
# print(x.shape)
y = x + 0.3*torch.normal(torch.zeros(DATA_SIZE, 1), torch.ones(DATA_SIZE, 1))
# print(y.shape)
x, y = Variable(x), Variable(y)
# test set
test_x = torch.unsqueeze(torch.linspace(-1, 1, DATA_SIZE), dim=1)
test_y = test_x + 0.3*torch.normal(torch.zeros(DATA_SIZE,1), torch.ones(DATA_SIZE,1))
test_x, test_y = Variable(test_x), Variable(test_y)
# scatter
plt.scatter(x.data.numpy(), y.data.numpy(), label='train')
plt.scatter(test_x.data.numpy(), test_y.data.numpy(), label='test')
plt.legend(loc='upper left')
plt.ylim((-2.5, 2.5))
plt.show()
N_HIDDEN = 300
# quick build NN by using Sequential
net_dropout = torch.nn.Sequential(
torch.nn.Linear(1, N_HIDDEN), # first hidden layer
torch.nn.Dropout(0.5), # drop 50% neurons
torch.nn.ReLU(), # activation func for first hidden layer
torch.nn.Linear(N_HIDDEN, N_HIDDEN), # second hidden layer
torch.nn.Dropout(0.5),
torch.nn.ReLU(), # activation func for second hidden layer
torch.nn.Linear(N_HIDDEN, 1)
)
print('\n net_dropout: \n', net_dropout)
# net_dropout:
# Sequential(
# (0): Linear(in_features=1, out_features=300, bias=True)
# (1): Dropout(p=0.5)
# (2): ReLU()
# (3): Linear(in_features=300, out_features=300, bias=True)
# (4): Dropout(p=0.5)
# (5): ReLU()
# (6): Linear(in_features=300, out_features=1, bias=True)
# )
optimizer_dropout = torch.optim.Adam(net_dropout.parameters(), lr=0.01)
loss_func = torch.nn.MSELoss()
for t in range(1000):
# train the NN by training set
prediction_dropout = net_dropout(x)
loss_dropout = loss_func(prediction_dropout, y)
optimizer_dropout.zero_grad()
loss_dropout.backward()
optimizer_dropout.step()
# test the NN by test set
net_dropout.eval() # test time differ from train time, NOT Dropout as test time
test_prediction_dropout = net_dropout(test_y)
# scatter
# plt.scatter(x.data.numpy(), y.data.numpy(), label='train')
plt.scatter(test_x.data.numpy(), test_y.data.numpy(), label='test')
# plot
plt.plot(test_x.data.numpy(), test_prediction_dropout.data.numpy(), 'b--', label='dropout')
plt.text(0, -1.5, 'dropout loss=%.4f' % loss_func(test_prediction_dropout, test_y).item(), fontdict={'size': 20, 'color': 'blue'})
plt.legend(loc='upper left')
plt.ylim((-2.5, 2.5))
plt.show()
- 所得图像的结果

L1和L2正则化
-
正则化
机器学学习中的正则化相关的内容可以参见李航的书:统计学习方法。参阅者可以先了解有关的内容。正则化是用来降低overfitting(过拟合)的,减少过拟合的的其他方法有:增加训练集数量,等等。对于数据集梳理有限的情况下,防止过拟合的另外一种方式就是降低模型的复杂度,怎么降低?一种方式就是在cost函数中加入正则化项,正则化项可以理解为复杂度,cost越小越好,但cost加上正则项之后,为了使cost小,就不能让正则项变大,也就是不能让模型更复杂,这样就降低了模型复杂度,也就降低了过拟合。这就是正则化。正则化也有很多种,常见为两种L2和L1。 -
L2 Regularization
下面先定义Regularization cross-entropy 函数:

相比于cross-entropy函数,这里多了最后一项,也就是正则化项。该项就是神经网络中的权重之和,其中λ>0为Regularization参数,n为训练集包含的实例个数。L2正则化项这里是指最后一项的w的平方项。
而对于二次cost,也可以加上正则化项:
Regularization quadratic cost:

概括上面两种函数为:

可以看出来,Regularization的cost偏向于让神经网络学习比较小的权重w,否则第一项的C0明显减小。
λ:调整两项的相对重要程度,较小的λ偏向于让第一项C0最小化,较大的λ倾向于最小化增大的项:权重值和。
对上面公式求导得:

相比于没有正则项时,对w的偏导多了一项λw/n,而对偏向b不变。
对于随机梯度算法来说,权重w和偏向b的更新法则变为:
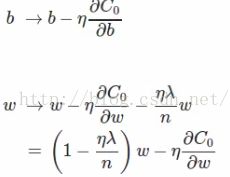
对于随机梯度下降算法变为:

其中m为mini_batch_size的大小。下面简单分析Regularization能降低overfitting的原因:
在神经网络中,正则化网络更倾向于小的权重,在权重小的情况下,数据x随机的变化不会对神经网络的模型造成太大的影响,所以可能性更小的受到数据局部噪音的影响。而未加入正则化的神经网络,权重大,容易通过较大的模型改变来适应数据,更容易学习到局部的噪音。 -
L1正则化
先介绍L1 Regularization cost函数为:

对C关于w求偏导得:
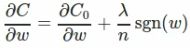
sgn(w)表示为符号函数,w为正,结果为1,w为负结果为-1。权重的更新法则为:
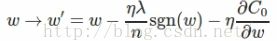
与L2 Regularization对比: 两者都是减小权重,但方式不同:
L1减少一个常量(η,λ,n根据输入都是固定的,sgn(w)为1或-1,故为常量),而L2减少的是权重的一个固定的比例;如果权重本身很大的话,L2减少的比L1减少的多,若权重小,则L1减少的更多。多以L1倾向于集中在少部分重要的连接上(w小)。这里要注意的是:sgn(w)在w=0时不可导,故要事先令sgn(w)在w=0时的导数为0。
*通过L1正则化和L2正则化后的代码
import torch
import torch.nn as nn
import torch.nn.functional as F
#读取数据集
# Pima-Indians-Diabetes数据集
import pandas as pd
import numpy as np
xy=pd.read_csv('/home/infisa/wjht/project/pytorch_practice/diabetes.csv',delimiter=',',dtype= np.float32)
#print(xy.head())
# print(type(xy))
xy_numpy = np.array(xy) #pandas转为numpy 为了后面numpy转tensor
# print(type(xy_numpy))
x=xy_numpy[:,0:-1] #x为768*8
y=xy_numpy[:,-1].reshape(-1,1) #为了让其shape为768*1
#将numpy 转为tensor
x_data=torch.Tensor(torch.from_numpy(x))
y_data=torch.Tensor(torch.from_numpy(y))
#查看维度
print(x_data.shape) # torch.Size([768, 8])
print(y_data.shape) # torch.Size([768, 1])
class Model(nn.Module):
def __init__(self):
super(Model,self).__init__()
#定义多层神经网络
self.fc1=torch.nn.Linear(8,6)
self.fc2=torch.nn.Linear(6,4)
self.fc3=torch.nn.Linear(4,1)
def forward(self, x):
x=F.relu(self.fc1(x)) #8->6 第一层
x=F.dropout(x,p=0.5) #dropout 1
x=F.relu(self.fc2(x)) # 6->4 第二层
x=F.dropout(x,p=0.5) #dropout 2
y_pred=torch.sigmoid(self.fc3(x)) #4->1 ->sigmoid 第三层sigmoid层
return y_pred
#自定义权重初始化函数
def weight_init(m):
classname=m.__class__.__name__
if classname.find('Linear')!=-1:
print('hi')
m.weight.data=torch.randn(m.weight.data.size()[0],m.weight.data.size()[1])
m.bias.data=torch.randn(m.bias.size())[0]
#定义损失函数及优化器
model=Model()
model.apply(weight_init)
criterion=torch.nn.BCELoss() #定义损失函数 binary crosstripy
optimizer=torch.optim.SGD(model.parameters(),lr=0.01,weight_decay=0) #学习率设为0.01 weight_decay 表示使用L2正则化
Loss=[]
print('x',x.shape)
#训练
for epoch in range(2000):
y_pred = model(x_data)
#计算误差
loss = criterion(y_pred,y_data)
l1_regularization, l2_regularization = torch.tensor([0], dtype=torch.float32), torch.tensor([0],
dtype=torch.float32) # 定义L1及L2正则化损失
# 注意 此处for循环 当上面定义了weight_decay时候,应注释掉
for param in model.parameters():
l1_regularization += torch.norm(param, 1) # L1正则化
l2_regularization += torch.norm(param, 2) # L2 正则化
#
# prin(loss.item())
loss = loss + l1_regularization #L1 正则化
# loss = loss + l2_regularization # L2 正则化
#prin(loss.item())
Loss.append(loss.item())
#每迭代1000次打印Lost并记录
if epoch%100 == 0:
print('[%d, %5d] loss: %.3f' %
(epoch + 1, 2000, loss.item()))
#梯度清零
optimizer.zero_grad()
#反向传播
loss.backward()
#更新梯度
optimizer.step()
#由于预测的是概率 所以需要将y_pred的值转化为和y_data一致类型的。
# y_data 为1或0(浮点数) 对于二分类,sigmoid函数值大于0.5时为1, 小于0.5时为0。
for i in range(len(y_pred)):
if(y_pred[i]>0.5):
y_pred[i] = 1.0
else:
y_pred[i] = 0.0
#print(y_pred)
print((y_pred == y_data).sum().item()/len(y_data)) # torch.Tensor.sum()函数
- 结果
0.3489583333333333
参考文章
https://blog.csdn.net/wehung/article/details/89283583#11_Drop_3 task5:Pytorch实现dropout及L1,L2正则化
https://blog.csdn.net/u014532743/article/details/78453990 PyTorch笔记8-Dropout
http://www.cs.toronto.edu/~rsalakhu/papers/srivastava14a.pdf Dropout: A Simple Way to Prevent Neural Networks from
Overfitting