P站(pixiv)爬虫小试——作者插画篇
上一次我爬到了一堆画师的ID,这次我准备进入这些画师的个人主页,按画师分类爬取他们的插画。
作者为在校本科生,刚接触爬虫不久,如有错误请批评指教。
首先是事前准备,需要引入的包有:
import re,requests,time,os
from urllib.parse import urlencode
登录P站的函数代码我之前已经写好了,代码如下:
def login(username, password): # 登录
# 模拟一下浏览器
head = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0',
'Referer': 'https://www.pixiv.net/member_illust.php?mode=medium&illust_id=64503210'
}
# 用requests的session模块记录登录的cookie
session = requests.session()
# 首先进入登录页获取post_key,我用的是正则表达式
response = session.get('https://accounts.pixiv.net/login?lang=zh')
post_key = re.findall('',
response.text)[0]
post_key = re.findall('value=".*?"', post_key)[0]
post_key = re.sub('value="', '', post_key)
post_key = re.sub('"', '', post_key)
# 将传入的参数用字典的形式表示出来,return_to可以去掉
data = {
'pixiv_id': username,
'password': password,
'return_to': 'https://www.pixiv.net/',
'post_key': post_key,
}
# 将data post给登录页面,完成登录
session.post("https://accounts.pixiv.net/login?lang=zh", data=data, headers=head)
return session
具体的解释请看我的上一篇:https://blog.csdn.net/weixin_44027604/article/details/97782600
OK,事前准备完毕,进入正题。
我们先进入一个画师的主页,并查看他的插画页面,分析网页。打开开发者工具后我们发现有一个名为“all”的json文件,里面已经包含了该画师的全部插画ID,甚至都不需要我们进行翻页操作。幸福来得太突然。

不过蹊跷的是这个json文件的头文件里并没有"Query String Parameters",也就是说这一次我们不能通过它来构造Request URL。但是我们再观察一下这个文件的Request URL,发现它其实非常有规律。这个“all”文件的Request URL其实就是“https://www.pixiv.net/ajax/user/画师ID/profile/all”。 果然幸福来得太突然。
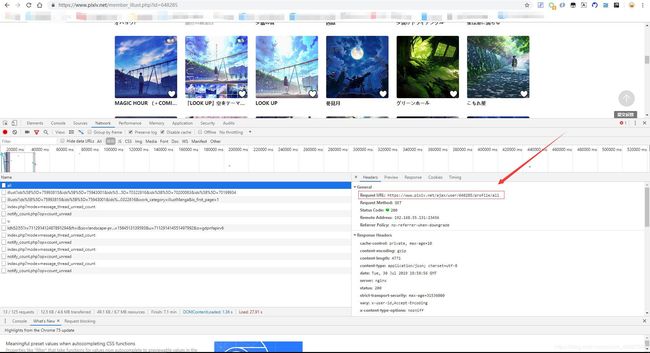
那么接下来就好办了,我们直接构造一个URL然后请求它就可以了。
def get_author_img_dic(author_id,username,password):#获取作者的全部作品字典
#登录用户
session = login(username, password)
response = session.get('https://www.pixiv.net/ajax/user/'+ author_id +'/profile/all')
# 不加以下这些会报错,似乎是因为eval()不能处理布尔型数据
global false, null, true
false = 'False'
null = 'None'
true = 'True'
author_img_dic = eval(response.content)['body']
print(author_img_dic)
return author_img_dic
返回的字典大概长这样
{'illusts': {'75993815': 'None', '75943001': 'None', '75688660': 'None', '75656233': 'None', '74650454': 'None', '74636051': 'None', '74563380': 'None', '74433171': 'None', '74099987': 'None', '74046731': 'None', '73960040': 'None', '73425674': 'None', '73315112': 'None', '73298277': 'None', '73134462': 'None', '73059317': 'None', '72765225': 'None', '72685264': 'None', '72612611': 'None', '72582412': 'None', '72337337': 'None', '72319075': 'None', '72253946': 'None', '72203811': 'None', '72190726': 'None', '72177032': 'None', '72131027': 'None', '72012267': 'None', '71998174': 'None', '71890716': 'None', '71818698': 'None', '71410837': 'None', '71360830': 'None', '71347774': 'None', '71334405': 'None', '71245340': 'None', '71153020': 'None', '71026673': 'None', '70977604': 'None', '70805413': 'None', '70588869': 'None', '70337807': 'None', '70322616': 'None', '70200063': 'None', '70199934': 'None', '70133000': 'None', '70116129': 'None', '70078815': 'None', '70078595': 'None', '70023635': 'None', '70023109': 'None', '70022790': 'None', '69974193': 'None', '69972787': 'None', '69941255': 'None', '69906686': 'None', '69817346': 'None', '69541377': 'None', '69247823': 'None', '69109533': 'None', '69015583': 'None', '68406253': 'None', '68405854': 'None', '68296699': 'None', '68268633': 'None', '68189098': 'None', '68049871': 'None', '67691929': 'None', '67673198': 'None', '67149445': 'None', '67070249': 'None', '67029211': 'None', '66952137': 'None', '66847530': 'None', '66731832': 'None', '66510799': 'None', '66475764': 'None', '66475317': 'None', '66399093': 'None', '66349124': 'None', '66337051': 'None', '66189889': 'None', '66177621': 'None', '66095083': 'None', '66070626': 'None', '65810524': 'None', '65621672': 'None', '65621619': 'None', '65596679': 'None', '65570382': 'None', '65555522': 'None', '65480793': 'None', '65394490': 'None', '65138347': 'None', '65047918': 'None', '64724388': 'None', '64634513': 'None', '64495529': 'None', '64476688': 'None', '64419747': 'None', '64323891': 'None', '64285180': 'None', '64245137': 'None', '64226279': 'None', '64191457': 'None', '64156931': 'None', '64083424': 'None', '64051606': 'None', '64019196': 'None', '63981975': 'None', '63966688': 'None', '63823726': 'None', '63723851': 'None', '63625393': 'None', '63436443': 'None', '63402383': 'None', '63177041': 'None', '63026901': 'None', '62947442': 'None', '62922314': 'None', '62867346': 'None', '62740716': 'None', '62722497': 'None', '62607887': 'None', '62578868': 'None', '62470954': 'None', '62356410': 'None', '62323924': 'None', '62303212': 'None', '62288977': 'None', '62259692': 'None', '62112251': 'None', '61671754': 'None', '61352102': 'None', '61319861': 'None', '61198649': 'None', '61082907': 'None', '61029746': 'None', '60772041': 'None', '60711418': 'None', '60600042': 'None', '60581318': 'None', '60494614': 'None', '60480856': 'None', '60453048': 'None', '60405476': 'None', '60367055': 'None', '60282363': 'None', '60268713': 'None', '60186040': 'None', '59980531': 'None', '59968424': 'None', '59888947': 'None', '59665005': 'None', '59651829': 'None', '59638857': 'None', '59625563': 'None', '59612101': 'None', '59593278': 'None', '59575434': 'None', '59548189': 'None', '59534677': 'None', '59507436': 'None', '59444815': 'None', '59417248': 'None', '59360632': 'None', '59152381': 'None', '59134218': 'None', '59088807': 'None', '59016989': 'None', '58869408': 'None', '58854668': 'None', '58769465': 'None', '58631983': 'None', '58522782': 'None', '58486776': 'None', '58486121': 'None', '58466965': 'None', '58255799': 'None', '58224017': 'None', '58221582': 'None', '58089176': 'None', '58024485': 'None', '58008753': 'None', '57994042': 'None', '57892933': 'None', '57877623': 'None', '57862790': 'None', '57745130': 'None', '57670818': 'None', '57535539': 'None', '57452467': 'None', '57420240': 'None', '57220061': 'None', '57151474': 'None', '56866981': 'None', '56838218': 'None', '56690454': 'None', '56601458': 'None', '56464922': 'None', '56464401': 'None', '56437143': 'None', '56421591': 'None', '56386138': 'None', '56385860': 'None', '56356476': 'None', '56342770': 'None', '56260009': 'None', '56244680': 'None', '55652917': 'None', '55577042': 'None', '55560247': 'None', '55414962': 'None', '55242942': 'None', '55226246': 'None', '54985455': 'None', '54977563': 'None', '54966022': 'None', '54943763': 'None', '54943652': 'None', '54927365': 'None', '54789438': 'None', '54718206': 'None', '54703214': 'None', '54322008': 'None', '54260273': 'None', '54216457': 'None', '54214253': 'None', '54157294': 'None', '54148598': 'None', '54060848': 'None', '54045756': 'None', '53962897': 'None', '53757246': 'None', '53747522': 'None', '53671052': 'None', '53495759': 'None', '53473931': 'None', '53473372': 'None', '53402985': 'None', '53355518': 'None', '53340151': 'None', '53256689': 'None', '53244028': 'None', '53149418': 'None', '53134970': 'None', '53121718': 'None', '53054611': 'None', '53054045': 'None', '52770205': 'None', '52549638': 'None', '52225474': 'None', '52225002': 'None', '52189708': 'None', '52172412': 'None', '52096729': 'None', '51981339': 'None', '51943873': 'None', '51943827': 'None', '51678343': 'None', '51450292': 'None', '51450173': 'None', '51335763': 'None', '51193008': 'None', '51160261': 'None', '50726712': 'None', '50678905': 'None', '50577874': 'None', '50563843': 'None', '50333462': 'None', '50136659': 'None', '50079939': 'None', '50079359': 'None', '49992696': 'None', '49963690': 'None', '49908632': 'None', '49860699': 'None', '49845728': 'None', '49526205': 'None', '49457446': 'None', '49441232': 'None', '49384169': 'None', '49295658': 'None', '49257858': 'None', '48965836': 'None', '48657428': 'None', '48561810': 'None', '48411768': 'None', '48319784': 'None', '48285499': 'None', '48269838': 'None', '48210539': 'None', '48053995': 'None', '47952820': 'None', '47809538': 'None', '47485018': 'None', '47484823': 'None', '47362468': 'None', '47264085': 'None', '47166481': 'None', '46920811': 'None', '46768131': 'None', '46732586': 'None', '46714223': 'None', '46713751': 'None', '46572820': 'None', '46401905': 'None', '46298786': 'None', '46222029': 'None', '46041073': 'None', '46008128': 'None', '45854318': 'None', '45806150': 'None', '45772170': 'None', '45629252': 'None', '45157273': 'None', '44769738': 'None', '44697372': 'None', '44595681': 'None', '44376213': 'None', '44231704': 'None', '44055175': 'None', '43933758': 'None', '43916142': 'None', '43668650': 'None', '43603576': 'None', '43588790': 'None', '43085181': 'None', '42698412': 'None', '42265521': 'None', '42004536': 'None', '41983276': 'None', '41853531': 'None', '41764898': 'None', '41560746': 'None', '41400597': 'None', '41380730': 'None', '41227454': 'None', '41226193': 'None', '41053126': 'None', '40971496': 'None', '40506240': 'None', '40103089': 'None', '40087438': 'None', '39995213': 'None', '39948230': 'None', '39851020': 'None', '39759232': 'None', '39575040': 'None', '39418529': 'None', '39244898': 'None', '39180086': 'None', '39060949': 'None', '38898689': 'None', '38779367': 'None', '38711879': 'None', '38585474': 'None', '38488230': 'None', '38412112': 'None', '38321337': 'None', '38283357': 'None', '37736449': 'None', '37637017': 'None', '37561039': 'None', '37534310': 'None', '37304371': 'None', '37274999': 'None', '37041376': 'None', '36998079': 'None', '36837556': 'None', '35312799': 'None', '34914131': 'None', '34874691': 'None', '33984980': 'None', '33824627': 'None', '33661213': 'None', '33000361': 'None', '32619076': 'None', '32566600': 'None', '32373276': 'None', '32113344': 'None', '31883364': 'None', '31122855': 'None', '30688325': 'None', '30540069': 'None', '30403453': 'None', '30170695': 'None', '29955948': 'None', '29431606': 'None', '29049807': 'None', '29005119': 'None', '28815718': 'None', '28217957': 'None', '28142987': 'None', '27505469': 'None', '27281561': 'None', '27146816': 'None', '27098517': 'None', '26811116': 'None', '26772258': 'None', '26602823': 'None', '26569694': 'None', '26386624': 'None', '25888476': 'None', '25721234': 'None', '25563060': 'None', '25481962': 'None', '25460416': 'None', '24607080': 'None', '24418130': 'None', '24362740': 'None', '24073941': 'None', '24004376': 'None', '23962669': 'None', '23829911': 'None', '23794944': 'None', '23567029': 'None', '23183509': 'None', '22981225': 'None', '22577264': 'None', '22576754': 'None', '22576489': 'None', '22576131': 'None', '22271290': 'None', '21202004': 'None', '21099822': 'None', '19643658': 'None', '19643273': 'None', '19643082': 'None', '18037406': 'None', '17999846': 'None', '16528502': 'None', '16246664': 'None', '15916048': 'None', '15884781': 'None', '15881675': 'None', '15881266': 'None', '15871307': 'None', '13900466': 'None', '13878051': 'None', '13657721': 'None', '12911206': 'None', '5670436': 'None', '4519520': 'None'}, 'manga': {'46073937': 'None', '41459185': 'None', '40738388': 'None', '40536505': 'None', '39608013': 'None', '38161569': 'None', '37177256': 'None', '28421956': 'None', '25024463': 'None', '19643473': 'None', '17999839': 'None'}, 'novels': [], 'mangaSeries': [], 'novelSeries': [], 'pickup': [{'type': 'comikeWebCatalog', 'deletable': 'False', 'draggable': 'False', 'title': 'コミックマーケット 96', 'contentUrl': 'https:\\/\\/webcatalog.circle.ms\\/Perma\\/Circle\\/10288961', 'description': '', 'imageUrl': 'https:\\/\\/s.pximg.net\\/common\\/images\\/circle_ms-no-image.svg', 'imageUrlMobile': 'https:\\/\\/s.pximg.net\\/common\\/images\\/circle_ms-no-image.svg'}, {'type': 'fanbox', 'deletable': 'False', 'draggable': 'True', 'userName': 'mocha@3日目西-O01a', 'userImageUrl': 'https:\\/\\/i.pximg.net\\/user-profile\\/img\\/2016\\/11\\/28\\/18\\/38\\/41\\/11807428_38b7d5ff662fd4b00c25ed608332a0e9_170.jpg', 'contentUrl': 'https:\\/\\/www.pixiv.net\\/fanbox\\/creator\\/648285?utm_campaign=www_profile&utm_medium=site_flow&utm_source=pixiv', 'description': '背景イラストレーターのmochaです。\r\n普段はゲームやアニメの背景や、書籍の装画などを描かせていただいております。\r\nこのFANBOXでは背景のメイキングを中心にQ&Aやイラスト添削を行うなど、みなさまとの交流をメインにいろいろ行っていきたいと思っています。\r\n【重要】FANBOXのバックナンバー機能がなくなったので、いままで毎月お届けしていた【描画動画付き背景メイキング】【イラストのGIF制作過程】【イラスト原寸DL】はその月が終わると同時に非表示に致します。その為、それ以降もお楽しみいただけるよう描画動画付き背景メイキングやGIF制作過程はDL形式になるかもしれませんのであらかじめご了承ください。尚、添削やQ&Aなど特殊な記事は全て閲覧できます。', 'imageUrl': 'https:\\/\\/pixiv.pximg.net\\/c\\/520x280_90_a2_g5\\/fanbox\\/public\\/images\\/creator\\/648285\\/cover\\/b9LaoBsS1MFYznByTZj8I582.jpeg', 'imageUrlMobile': 'https:\\/\\/pixiv.pximg.net\\/c\\/520x280_90_a2_g5\\/fanbox\\/public\\/images\\/creator\\/648285\\/cover\\/b9LaoBsS1MFYznByTZj8I582.jpeg', 'hasAdultContent': 'False'}, {'id': '71818698', 'title': '遥か', 'illustType': 0, 'xRestrict': 0, 'restrict': 0, 'sl': 2, 'description': '遥か遠くを夢見る\u3000大人になってもきっとずっと
C95の新刊風景イラスト集「Faraway」の表紙用イラストです。
通販ページにて本の詳細を更新していきます
◆BOOTH(https:\\/\\/mocha.booth.pm\\/items\\/1067784<\\/a>)', 'url': 'https:\\/\\/i.pximg.net\\/c\\/288x288_80_a2\\/img-master\\/img\\/2018\\/11\\/25\\/00\\/45\\/25\\/71818698_p0_square1200.jpg', 'tags': ['風景', '背景', 'オリジナル', '空', 'C95', '風車', '入道雲', '風景10000users入り', 'オリジナル10000users入り'], 'userId': '648285', 'userName': 'mocha@3日目西-O01a', 'width': 1433, 'height': 1021, 'pageCount': 1, 'isBookmarkable': 'None', 'bookmarkData': 'None', 'type': 'illust', 'deletable': 'True', 'draggable': 'True', 'contentUrl': 'https:\\/\\/www.pixiv.net\\/member_illust.php?mode=medium&illust_id=71818698'}, {'id': '68296699', 'title': '17:30', 'illustType': 0, 'xRestrict': 0, 'restrict': 0, 'sl': 2, 'description': '夕方、いつものチャイムが聞こえる。
一緒に、夕食のいいにおいも漂ってくる。
◆COMITIA124の新刊、空をテーマにしたイラスト集『365』のイラストです。スペースは【A29b】です!
通販・詳細はこちら→(https:\\/\\/mocha.booth.pm\\/items\\/819412<\\/a>)', 'url': 'https:\\/\\/i.pximg.net\\/c\\/288x288_80_a2\\/img-master\\/img\\/2018\\/04\\/19\\/01\\/31\\/33\\/68296699_p0_square1200.jpg', 'tags': ['オリジナル', '風景', '背景', 'COMITIA124', '夕方', 'カーブミラー', '空', '映り込み', '夕暮れ', 'オリジナル100000users入り'], 'userId': '648285', 'userName': 'mocha@3日目西-O01a', 'width': 1200, 'height': 848, 'pageCount': 1, 'isBookmarkable': 'None', 'bookmarkData': 'None', 'type': 'illust', 'deletable': 'True', 'draggable': 'True', 'contentUrl': 'https:\\/\\/www.pixiv.net\\/member_illust.php?mode=medium&illust_id=68296699'}, {'id': '70133000', 'title': '桜花爛漫', 'illustType': 0, 'xRestrict': 0, 'restrict': 0, 'sl': 2, 'description': '桜で満たされた空間
■このイラストは廃墟をテーマにしたイラスト集「廃想」に入っています。
COMITIA125【け32a】でも頒布致します!(https:\\/\\/mocha.booth.pm\\/items\\/923669<\\/a>)
■アーティスリンクさまに版画化していただきました!ハイライト部分などがラメでキラキラ光ったりしていてとても豪華です…!(http:\\/\\/www.artislink.com\\/?pid=134115008<\\/a>)', 'url': 'https:\\/\\/i.pximg.net\\/c\\/288x288_80_a2\\/img-master\\/img\\/2018\\/08\\/11\\/00\\/41\\/29\\/70133000_p0_square1200.jpg', 'tags': ['オリジナル', '風景', '背景', '廃墟', '桜', 'C94', 'COMITIA125', '風景10000users入り', 'オリジナル30000users入り', 'ふつくしい'], 'userId': '648285', 'userName': 'mocha@3日目西-O01a', 'width': 1500, 'height': 859, 'pageCount': 1, 'isBookmarkable': 'None', 'bookmarkData': 'None', 'type': 'illust', 'deletable': 'True', 'draggable': 'True', 'contentUrl': 'https:\\/\\/www.pixiv.net\\/member_illust.php?mode=medium&illust_id=70133000'}], 'bookmarkCount': {'public': {'illust': 1, 'novel': 0}, 'private': {'illust': 0, 'novel': 0}}, 'externalSiteWorksStatus': {'booth': 'True', 'sketch': 'True', 'vroidHub': 'False'}}
可以看出,这个字典里动图和插画ID拥有同一个键,漫画与漫画系列则各成一派,因此从这个字典里提取出ID列表时我们可以写三个函数,分别提取动图/插画ID、漫画ID、漫画系列ID。代码很简单,就不多解释了:
def get_author_illusts(author_img_dic): #从author_img_dic中获取作者的插画与动图ID
author_illusts_dic = author_img_dic['illusts']
illusts_list = [ key for key,value in author_illusts_dic.items() ]
return illusts_list
def get_author_manga(author_img_dic): #从author_img_dic中获取作者的漫画ID
author_manga_dic = author_img_dic['manga']
manga_list = [ key for key,value in author_manga_dic.items() ]
return manga_list
def get_author_mangaSeries(author_img_dic): #从author_img_dic中获取作者的漫画系列ID
author_mangaSeries_dic = author_img_dic['mangaSeries']
mangaSeries_list = [ key for key,value in author_mangaSeries_dic.items() ]
return mangaSeries_list
拿到插画的ID后我们就可以去插画的页面爬图片了。为什么不直接在画师的主页里爬图片?因为包含图片url的json文件一页需要传入几十个参数,写起来太费劲了,不如直接拿图片ID去图片的页面爬东西。

那么接下来我们随意点开一张插画,依旧是观察它的json文件。我们很轻松地就发现了一个json文件里带有了我们想要的几乎所有信息。无论是画师ID、插画ID、图片地址等等信息都可以在这里找到。(这个文件可能得多刷新几次才可以找到)

不过别高兴地太早,经过对比后我们可以发现这个json文件里只有一张插画的地址,对于那些有好几张插画的网页(比如图中这个)来说这个url就是第一张图的。如果我们想获取所有的图片,必须要用其他的json文件。不过我们很快也能找到这个文件,如下图所示。
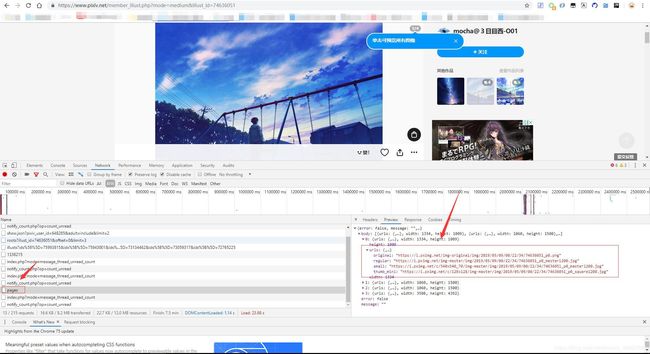
那么我们再来分别观察一下这两个文件的Request URL,也发现了很明显的规律。这两个文件的Request URL分别是“https://www.pixiv.net/ajax/illust/图片ID”以及前者加上“pages”


那么接下来的事情就很简单了,我们只要把图片的ID当作参数传入函数,拿到这两个文件然后处理一下就可以了。代码如下:
def get_img_dic(img_id,username, password):#传入图片ID,返回该图片ID下的信息,具体信息见注释
'''
img_dic = {
'illustID' : 插画ID
'illustTitle' : 插画标题
'illustDescription' : 插画简介
'createDate' : 插画创建时间
'uploadDate' : 插画更新时间
'tags' : 插画tag,值为列表
'authorID' : 作者ID
'authorName' : 作者昵称
'imgUrl' : 插画原始大小url,值为列表
}
'''
img_dic ={}
# 登录用户
session = login(username, password)
#获取第一个文件的信息,把除了图片url以外的东西先拿到
url_1 = 'https://www.pixiv.net/ajax/illust/' + img_id
response_1 = session.get(url_1)
# 不加以下这些会报错,似乎是因为eval()不能处理布尔型数据
global false, null, true
false = 'False'
null = 'None'
true = 'True'
response_1 = eval(response_1.content)['body']
img_dic['illustID'] = response_1['illustId'] #图片ID
img_dic['illustTitle'] = response_1['illustTitle'] #图片标题
img_dic['illustDescription'] = response_1['illustComment'] #图片简介
img_dic['createDate'] = response_1['createDate'] #创建时间
img_dic['uploadDate'] = response_1['uploadDate'] #更新时间
img_dic['tags'] = [] #因为有多个tag,所以'tags'的值用列表形式保存
for tag in response_1['tags']['tags']:
img_dic['tags'].append(tag['tag'])
img_dic['authorID'] = response_1['tags']['tags'][0]['userId']
img_dic['authorName'] = response_1['tags']['tags'][0]['userName']
#获取第二个文件的信息,把图片url拿到
url_2 = 'https://www.pixiv.net/ajax/illust/' + img_id + '/pages'
response_2 = session.get(url_2)
response_2 = eval(response_2.content)['body']
img_dic['imgUrl'] = [] #因为存在好几个插画在同一页面的情况,所以'imgUrl'的值用列表形式保存
for img_url in response_2:
img_dic['imgUrl'].append(img_url['urls']['original'].replace('\\', ''))
return img_dic
返回的字典大概长这样:
{'illustID': '75947252', 'illustTitle': '思春期の話', 'illustDescription': '夏ですね', 'createDate': '2019-07-28T00:47:16+00:00', 'uploadDate': '2019-07-28T00:47:16+00:00', 'tags': ['漫画', '青春がもう一度始まる話(願望)', 'なにこれ切ない', 'そして時(青春)は動き出す', 'あるある', 'ねーよ!', '学生時代のほろ苦い恋の話', '前へ進む限り後悔は残る', 'One', 'オリジナル5000users入り'], 'authorID': '10509347', 'authorName': 'しろまんた', 'imgUrl': ['https://i.pximg.net/img-original/img/2019/07/28/09/47/16/75947252_p0.png', 'https://i.pximg.net/img-original/img/2019/07/28/09/47/16/75947252_p1.png', 'https://i.pximg.net/img-original/img/2019/07/28/09/47/16/75947252_p2.png', 'https://i.pximg.net/img-original/img/2019/07/28/09/47/16/75947252_p3.png']}
不论你想要什么信息,从字典里取就可以了。因为本篇是准备爬图片,那就再写一个提取图片url、图片ID和图片标题的函数。图片url自然不必多说,至于为何要图片ID,接下来就会解释。而图片标题只是为了解决最后的文件命名问题。
def get_img_imformation(img_dic): #从img_dic里提取下载所需的信息
img_imformation = {}
img_imformation['img_url'] = img_dic['imgUrl']
img_imformation['img_id'] = img_dic['illustID']
img_imformation['img_title'] = img_dic['illustTitle']
return img_imformation
最后一个函数,就是利用图片url下载图片了。
在写代码之前,我们先直接在浏览器里复制粘贴一个图片url看看,然后出现了403 Forbidden。好在已经有前人解决了这个问题,请参考https://blog.csdn.net/qq_28148007/article/details/91352688

简单而言就是,在通过图片url请求图片时需要在请求头文件里加上图片所在页面的网址,否则就会403。
最终得到的下载函数代码如下,不过多解释:
def download(img_imformation,address): #下载图片,以图片标题命名
n = 0
head = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0',
'Referer' : 'https://www.pixiv.net/member_illust.php?mode=medium&illust_id=' + img_imformation['img_id']
}
for img_url in img_imformation['img_url']:
img_response = requests.get(img_url,headers=head)
image = img_response.content
try:
if n == 0:
with open(address+ '/' + img_imformation['img_title']
+ '.jpg', 'wb') as jpg:
jpg.write(image)
else:
with open(address+ '/' + img_imformation['img_title']
+ '(' + str(n) + ')' + '.jpg', 'wb') as jpg:
jpg.write(image)
except IOError:
print("IO Error\n")
finally:
jpg.close
n = n + 1
最后的最后,就是实现函数啦。我们回过头来再次确认我们的目标“进入画师的个人主页,按画师分类爬取他们的插画”。那么实现函数的思路就很明确了:
得到画师ID ----> 利用画师ID获得图片ID ----> 利用图片ID获得图片下载所需信息 ----> 下载图片
以下是代码
if __name__ == '__main__':
#打开作者ID的txt文件,一个ID为一行
file = open(r'作者ID的txt文件',encoding='utf-8')
while True:
#去除换行符
author_id = file.readline().replace('\n','')
#根据作者ID得到插画ID
author_img_dic = get_author_img_dic(author_id,'你的用户名','你的密码')
illusts_list = get_author_illusts(author_img_dic)
#根据作者ID得到下载信息
for img_id in illusts_list:
img_dic = get_img_dic(img_id,'你的用户名','你的密码')
address = '存放路径' + img_dic['authorName']
#创建以画师为名的文件夹作为图片存放路径
#try语句是为了去除重复创建文件夹带来的异常
try:
os.mkdir(address)
except:
img_imformation = get_img_imformation(img_dic)
# 根据下载信息下载
download(img_imformation, address)
else:
img_imformation = get_img_imformation(img_dic)
#根据下载信息下载
download(img_imformation, address)
if author_id == '':
break
file.close()
只要将所有代码块里代码粘贴到一个py文件中,并事先准备好作者ID的txt文件,然后将函数实现部分的中文部分进行更改,应该就可以顺利运行。
以上代码目前有以下不足:
1.可能会被封IP,导致报错
原因:没做IP池和cookie池
2.爬取速度慢
原因:没开多线程。稍微改改应该就能开多线程了。
代码已上传至github:https://github.com/fandaosi/PIXIV_spider。