MobilenNet模型
MobilenNet模型
- 深度可分离卷积
- MobileNet的结构
- 1、主干模型
- 2、Unet解码部分
深度可分离卷积
MobilenNet模型是一种轻量级的网络,核心思想便是深度可分离卷积(depthwise separable convolution)
正常卷积:卷积参数的总数=属性的总数x卷积核的大小。
深度可分离卷积:深度可分离卷积的方法有所不同。正常卷积核是对3个通道同时做卷积。也就是说,3个通道,在一次卷积后,输出一个数。
深度可分离卷积分为两步:
1、第一步用三个卷积对三个通道分别做卷积,这样在一次卷积后,输出3个数。这输出的三个数,再通过一个1x1x3的卷积核(pointwise核),得到一个数。所以深度可分离卷积其实是通过两次卷积实现的。第一步,对三个通道分别做卷积,输出三个通道的属性。

2、第二步,用卷积核1x1x3对三个通道再次做卷积,这个时候的输出就和正常卷积一样,是8x8x1。(用来调整通道数)
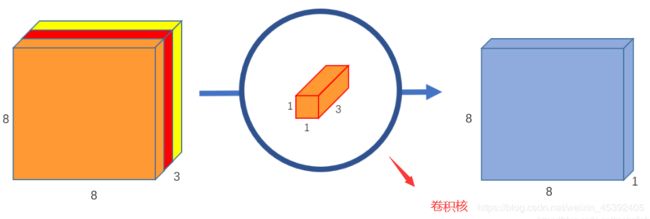
如果要提取更多的属性,则需要设计更多的1x1x3卷积核心就可以,感觉应该将8x8x256那个立方体绘制成256个8x8x1,因为他们不是一体的,代表了256个属性。

可以看到,如果仅仅是提取一个属性,深度可分离卷积的方法,不如正常卷积。随着要提取的属性越来越多,深度可分离卷积就能够节省更多的参数。
对于一个卷积点而言:
假设有一个3×3大小的卷积层,其输入通道为16、输出通道为32。具体为,32个3×3大小的卷积核会遍历16个通道中的每个数据,最后可得到所需的32个输出通道,所需参数为16×32×3×3=4608个。
应用深度可分离卷积,用16个3×3大小的卷积核分别遍历16通道的数据,得到了16个特征图谱。在融合操作之前,接着用32个1×1大小的卷积核遍历这16个特征图谱,所需参数为16×3×3+16×32×1×1=656个。
可以看出来depthwise separable convolution可以减少模型的参数。
在建立模型的时候,可以使用Keras中的DepthwiseConv2D层实现深度可分离卷积,然后再利用1x1卷积调整channels数。
通俗地理解就是3x3的卷积核厚度只有一层,然后在输入张量上一层一层地滑动,每一次卷积完生成一个输出通道,当卷积完成后,在利用1x1的卷积调整厚度。
MobileNet的结构
Conv dw就是分层卷积,在其之后都会接一个1x1的卷积进行通道处理

下面我做了这个网络的图

1、主干模型
该部分用于特征提取,实际上就是常规的mobilenet结构
from keras.models import *
from keras.layers import *
import keras.backend as K
import keras
IMAGE_ORDERING = 'channels_last'
def relu6(x):
return K.relu(x, max_value=6)
def _conv_block(inputs, filters, alpha, kernel=(3, 3), strides=(1, 1)):
channel_axis = 1 if IMAGE_ORDERING == 'channels_first' else -1
filters = int(filters * alpha)
x = ZeroPadding2D(padding=(1, 1), name='conv1_pad', data_format=IMAGE_ORDERING )(inputs)
x = Conv2D(filters, kernel , data_format=IMAGE_ORDERING ,
padding='valid',
use_bias=False,
strides=strides,
name='conv1')(x)
x = BatchNormalization(axis=channel_axis, name='conv1_bn')(x)
return Activation(relu6, name='conv1_relu')(x)
def _depthwise_conv_block(inputs, pointwise_conv_filters, alpha,
depth_multiplier=1, strides=(1, 1), block_id=1):
channel_axis = 1 if IMAGE_ORDERING == 'channels_first' else -1
pointwise_conv_filters = int(pointwise_conv_filters * alpha)
x = ZeroPadding2D((1, 1) , data_format=IMAGE_ORDERING , name='conv_pad_%d' % block_id)(inputs)
x = DepthwiseConv2D((3, 3) , data_format=IMAGE_ORDERING ,
padding='valid',
depth_multiplier=depth_multiplier,
strides=strides,
use_bias=False,
name='conv_dw_%d' % block_id)(x)
x = BatchNormalization(
axis=channel_axis, name='conv_dw_%d_bn' % block_id)(x)
x = Activation(relu6, name='conv_dw_%d_relu' % block_id)(x)
x = Conv2D(pointwise_conv_filters, (1, 1), data_format=IMAGE_ORDERING ,
padding='same',
use_bias=False,
strides=(1, 1),
name='conv_pw_%d' % block_id)(x)
x = BatchNormalization(axis=channel_axis,
name='conv_pw_%d_bn' % block_id)(x)
return Activation(relu6, name='conv_pw_%d_relu' % block_id)(x)
def get_mobilenet_encoder( input_height=224 , input_width=224 , pretrained='imagenet' ):
alpha=1.0
depth_multiplier=1
dropout=1e-3
img_input = Input(shape=(input_height,input_width , 3 ))
x = _conv_block(img_input, 32, alpha, strides=(2, 2))
x = _depthwise_conv_block(x, 64, alpha, depth_multiplier, block_id=1)
f1 = x
x = _depthwise_conv_block(x, 128, alpha, depth_multiplier,
strides=(2, 2), block_id=2)
x = _depthwise_conv_block(x, 128, alpha, depth_multiplier, block_id=3)
f2 = x
x = _depthwise_conv_block(x, 256, alpha, depth_multiplier,
strides=(2, 2), block_id=4)
x = _depthwise_conv_block(x, 256, alpha, depth_multiplier, block_id=5)
f3 = x
x = _depthwise_conv_block(x, 512, alpha, depth_multiplier,
strides=(2, 2), block_id=6)
x = _depthwise_conv_block(x, 512, alpha, depth_multiplier, block_id=7)
x = _depthwise_conv_block(x, 512, alpha, depth_multiplier, block_id=8)
x = _depthwise_conv_block(x, 512, alpha, depth_multiplier, block_id=9)
x = _depthwise_conv_block(x, 512, alpha, depth_multiplier, block_id=10)
x = _depthwise_conv_block(x, 512, alpha, depth_multiplier, block_id=11)
f4 = x
x = _depthwise_conv_block(x, 1024, alpha, depth_multiplier,
strides=(2, 2), block_id=12)
x = _depthwise_conv_block(x, 1024, alpha, depth_multiplier, block_id=13)
f5 = x
return img_input , [f1 , f2 , f3 , f4 , f5 ]
2、Unet解码部分
把获得的特征重新映射到比较大的图中的每一个像素点,用于每一个像素点的分类
from keras.models import *
from keras.layers import *
from nets.mobilenet import get_mobilenet_encoder
import tensorflow as tf
IMAGE_ORDERING = 'channels_last'
MERGE_AXIS = -1
def _unet( n_classes , encoder , l1_skip_conn=False, input_height=416, input_width=608 ):
img_input , levels = encoder( input_height=input_height , input_width=input_width )
[f1 , f2 , f3 , f4 , f5 ] = levels
o = f4 #压缩四次
# 26,26,512
o = ( ZeroPadding2D( (1,1) , data_format=IMAGE_ORDERING ))(o)
o = ( Conv2D(512, (3, 3), padding='valid', data_format=IMAGE_ORDERING))(o)
o = ( BatchNormalization())(o)
# 52,52,512
o = ( UpSampling2D( (2,2), data_format=IMAGE_ORDERING))(o)
#upsmapling之后就会跟f3进行堆叠
# 52,52,768
o = ( concatenate([ o ,f3],axis=MERGE_AXIS ) )
o = ( ZeroPadding2D( (1,1), data_format=IMAGE_ORDERING))(o)
# 52,52,256
o = ( Conv2D( 256, (3, 3), padding='valid', data_format=IMAGE_ORDERING))(o)
o = ( BatchNormalization())(o)
# 104,104,256
o = ( UpSampling2D( (2,2), data_format=IMAGE_ORDERING))(o)
# 104,104,384
o = ( concatenate([o,f2],axis=MERGE_AXIS ) )
o = ( ZeroPadding2D((1,1) , data_format=IMAGE_ORDERING ))(o)
# 104,104,128
o = ( Conv2D( 128 , (3, 3), padding='valid' , data_format=IMAGE_ORDERING ) )(o)
o = ( BatchNormalization())(o)
# 208,208,128
o = ( UpSampling2D( (2,2), data_format=IMAGE_ORDERING))(o)
if l1_skip_conn:
o = ( concatenate([o,f1],axis=MERGE_AXIS ) )
# 210, 210, 128
o = ( ZeroPadding2D((1,1) , data_format=IMAGE_ORDERING ))(o)
# 208, 208, 64
o = ( Conv2D( 64 , (3, 3), padding='valid' , data_format=IMAGE_ORDERING ))(o)
o = ( BatchNormalization())(o)
# 208, 208, 2
o = Conv2D( n_classes , (3, 3) , padding='same', data_format=IMAGE_ORDERING )( o )
# 将结果进行reshape
o = Reshape((int(input_height/2)*int(input_width/2), -1))(o)
o = Softmax()(o)
model = Model(img_input,o)
return model
def mobilenet_unet( n_classes , input_height=224, input_width=224 , encoder_level=3):
model = _unet( n_classes , get_mobilenet_encoder , input_height=input_height, input_width=input_width )
model.model_name = "mobilenet_unet"
return model
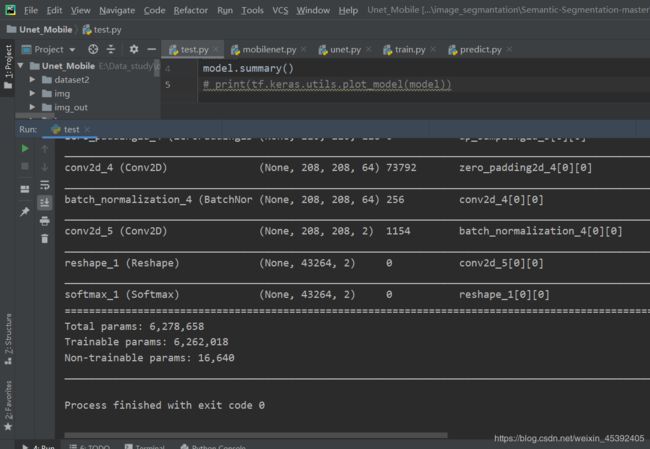
测试模型:
完成了模型的搭建