动手学深度学习PyTorch版-task2
目录:
task1:https://blog.csdn.net/zahidzqj/article/details/104293563
task2:本章节
task3:https://blog.csdn.net/zahidzqj/article/details/104319328
task4:https://blog.csdn.net/zahidzqj/article/details/104324196
task5:https://blog.csdn.net/zahidzqj/article/details/10432434
task6:https://blog.csdn.net/zahidzqj/article/details/104451810
task8:https://blog.csdn.net/zahidzqj/article/details/104452274
task9:https://blog.csdn.net/zahidzqj/article/details/104452480
task10:https://blog.csdn.net/zahidzqj/article/details/104478668
task2:
1文本预处理
基本概念:读入文本、分词、建立字典、将词转为索引
读入文本:先打开一段文本如1.txt:

将文本按段落读取,再将文本转为小写,使用正则的方法,消除其中的非字母的字符,得到句子。
import re
with open('1.txt', 'r') as f:
print([re.sub('[^a-z]+', ' ', line.strip().lower()) for line in f])分词:对每个句子进行分词,也就是将一个句子划分成若干个词(token),转换为一个词的序列。
建立字典:为了方便模型处理,我们需要将字符串转换为数字。因此我们需要先构建一个字典(vocabulary),将每个词映射到一个唯一的索引编号。
需要注意的是:一些特殊的token:pad:使得短句子和长的相同,在sgd的时候批次的句子一样长; bos eos 分别为开始结束 ;unk未知字符,比如无论use_special_token参数是否为真,都会使用的特殊token是unk。
将词转为索引:使用字典,我们可以将原文本中的句子从单词序列转换为索引序列。
用现有工具进行分词
我们前面介绍的分词方式非常简单,它至少有以下几个缺点:
- 标点符号通常可以提供语义信息,但是我们的方法直接将其丢弃了
- 类似“shouldn't", "doesn't"这样的词会被错误地处理
- 类似"Mr.", "Dr."这样的词会被错误地处理
我们可以通过引入更复杂的规则来解决这些问题,但是事实上,有一些现有的工具可以很好地进行分词,我们在这里简单介绍其中的两个:spaCy和NLTK。
2语言模型
基本概念:语言模型、n元语法、读取数据、时序采样
语言模型:一段自然语言文本可以看作是一个离散时间序列,给定一个长度为TT的词的序列w1,w2,…,wTw1,w2,…,wT,语言模型的目标就是评估该序列是否合理,即计算该序列的概率:P(w1,w2,…,wT).
假设序列w1,w2,…,wTw1,w2,…,wT中的每个词是依次生成的,我们有
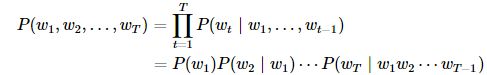
词频计算:
![]()
其中n(w1)n(w1)为语料库中以w1w1作为第一个词的文本的数量,nn为语料库中文本的总数量。
n元语法:序列长度增加,计算和存储多个词共同出现的概率的复杂度会呈指数级增加。nn元语法通过马尔可夫假设简化模型,马尔科夫假设是指一个词的出现只与前面nn个词相关,即nn阶马尔可夫链(Markov chain of order nn)如果n=1n=1,那么有P(w3∣w1,w2)=P(w3∣w2)P(w3∣w1,w2)=P(w3∣w2)。基于n−1n−1阶马尔可夫链,我们可以将语言模型改写为
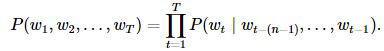

nn元语法的缺陷:1 参数空间过大
2 数据稀疏
时序采样:在训练中我们需要每次随机读取小批量样本和标签。如果序列的长度为TT,时间步数为nn,那么一共有T−nT−n个合法的样本,但是这些样本有大量的重合,我们通常采用更加高效的采样方式。我们有两种方式对时序数据进行采样,分别是随机采样和相邻采样。
随机采样:在随机采样中,每个样本是原始序列上任意截取的一段序列,相邻的两个随机小批量在原始序列上的位置不一定相毗邻。
相邻采样:在相邻采样中,相邻的两个随机小批量在原始序列上的位置相毗邻。
3.RNN(主要引用自吴恩达深度学习)
RNNs在NLP中典型应用:
(1)语言模型与文本生成(Language Modeling and Generating Text)
给定一组单词序列,需要根据前面单词预测每个单词出现的可能性。语言模型能够评估某个语句正确的可能性,可能性越大,语句越正确。另一种应用便是使用生成模型预测下一个单词的出现概率,从而利用输出概率的采样生成新的文本。
(2)机器翻译(Machine Translation)
机器翻译是将一种源语言语句变成意思相同的另一种源语言语句,如将英语语句变成同样意思的中文语句。与语言模型关键的区别在于,需要将源语言语句序列输入后,才进行输出,即输出第一个单词时,便需要从完整的输入序列中进行获取。
(3)语音识别(Speech Recognition)
语音识别是指给定一段声波的声音信号,预测该声波对应的某种指定源语言语句以及计算该语句的概率值。
(4)图像描述生成 (Generating Image Descriptions)
同卷积神经网络(convolutional Neural Networks, CNNs)一样,RNNs已经在对无标图像描述自动生成中得到应用。CNNs与RNNs结合也被应用于图像描述自动生成。
从一些例子中你可以看出序列问题有很多不同类型。有些问题里,输入数据 X和输出数据Y都是序列,但就算在那种情况下,X和Y有时也会不一样长。
我们的目的是基于当前的输入与过去的输入序列,预测序列的下一个字符。循环神经网络引入一个隐藏变量H,用Ht表示H在时间步t的值。Ht的计算基于Xt和Ht−1,可以认为Ht记录了到当前字符为止的序列信息,利用Ht对序列的下一个字符进行预测。
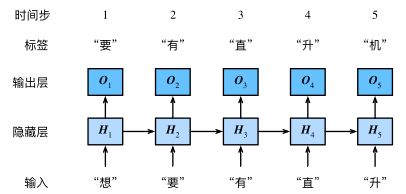
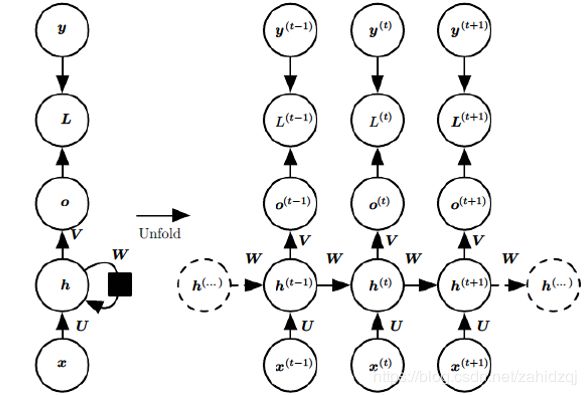
需要寻优的参数有三个,分别是U、V、W。与BP算法不同的是,其中W和U两个参数的寻优过程需要追溯之前的历史数据,参数V相对简单只需关注目前,那么我们就来先求解参数V的偏导数。
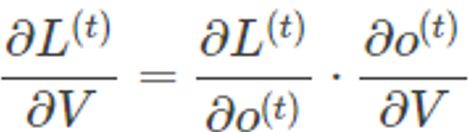
这个式子看起来简单但求解起来很容易出错,因为其中嵌套着激活函数函数,是复合函数的求导过程。 RNN的损失也是会随着时间累加的,所以不能只求t时刻的偏导。

W和U的偏导的求解由于需要涉及到历史数据,其偏导求起来相对复杂,我们先假设只有三个时刻,那么在第三个时刻 L对W的偏导数为:

相应的,L在第三个时刻对U的偏导数为:
![]()
根据上面两个式子可以写出L在t时刻对W和U偏导数的通式:
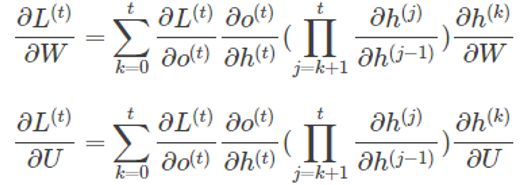
整体的偏导公式就是将其按时刻再一一加起来。前面说过激活函数是嵌套在里面的,如果我们把激活函数放进去,拿出中间累乘的那部分:
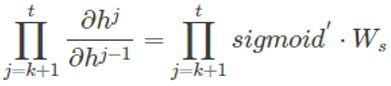
累乘会导致激活函数导数的累乘,进而会导致“梯度消失“和“梯度爆炸“现象的发生。
梯度消失就意味消失那一层的参数再也不更新,那么那一层隐层就变成了单纯的映射层,毫无意义了。