Spark Core项目实战(1) | 准备数据与计算Top10 热门品类(附完整项目代码及注释)
大家好,我是不温卜火,是一名计算机学院大数据专业大二的学生,昵称来源于成语—
不温不火,本意是希望自己性情温和。作为一名互联网行业的小白,博主写博客一方面是为了记录自己的学习过程,另一方面是总结自己所犯的错误希望能够帮助到很多和自己一样处于起步阶段的萌新。但由于水平有限,博客中难免会有一些错误出现,有纰漏之处恳请各位大佬不吝赐教!暂时只有csdn这一个平台,博客主页:https://buwenbuhuo.blog.csdn.net/
项目代码博主已经打包到Github需要的可以自行下载:https://github.com/459804692/spark0729
目录
- 一. 准备数据
- 二. Top10 热门品类
- 1. 简介
- 2. 思路
- 三. 具体实现
- 1. 前提准备
- 2.建立项目APP
- 3. 完整项目代码

一. 准备数据
本实战项目的数据是采集自电商的用户行为数据.
主要包含用户的 4 种行为: 搜索, 点击, 下单和支付.
数据格式如下, 不同的字段使用下划线分割开_:
- 1. 数据

- 2. 数据说明
- 数据采用_分割字段
- 每一行表示用户的一个行为, 所以每一行只能是四种行为中的一种.
- 如果搜索关键字是 null, 表示这次不是搜索
- 如果点击的品类 id 和产品 id 是 -1 表示这次不是点击
- 下单行为来说一次可以下单多个产品, 所以品类 id 和产品 id 都是多个, id 之间使用逗号,分割. 如果本次不是下单行为, 则他们相关数据用null来表示
- 支付行为和下单行为类似.
二. Top10 热门品类
1. 简介
品类是指的产品的的分类, 一些电商品类分多级, 咱们的项目中品类类只有一级. 不同的公司可能对热门的定义不一样. 我们按照每个品类的 点击、下单、支付 的量来统计热门品类.
2. 思路
- 1.思路 1
分别统计每个品类点击的次数, 下单的次数和支付的次数.
缺点: 统计 3 次, 需要启动 3 个 job, 每个 job 都有对原始数据遍历一次, 非常的耗时
- 2. 思路 2
最好的办法应该是遍历一次能够计算出来上述的 3 个指标.
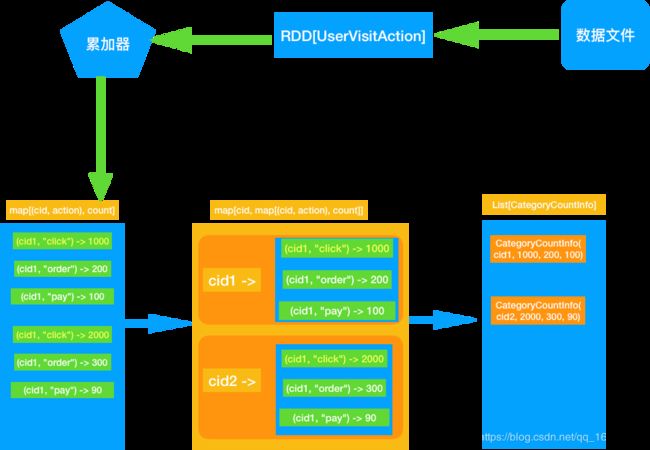
使用累加器可以达成我们的需求.
- 遍历全部日志数据, 根据品类 id 和操作类型分别累加. 需要用到累加器
- 定义累加器
- 当碰到订单和支付业务的时候注意拆分字段才能得到品类 id
- 遍历完成之后就得到每个每个品类 id 和操作类型的数量.
- 按照点击下单支付的顺序来排序
- 取出 Top10
三. 具体实现
1. 前提准备
- 1.创建新module
- 2.添加依赖
<artifactId>spark-core-project</artifactId>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.27</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- 打包插件, 否则 scala 类不会编译并打包进去 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.4.6</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
- 3. 新建package

2.建立项目APP
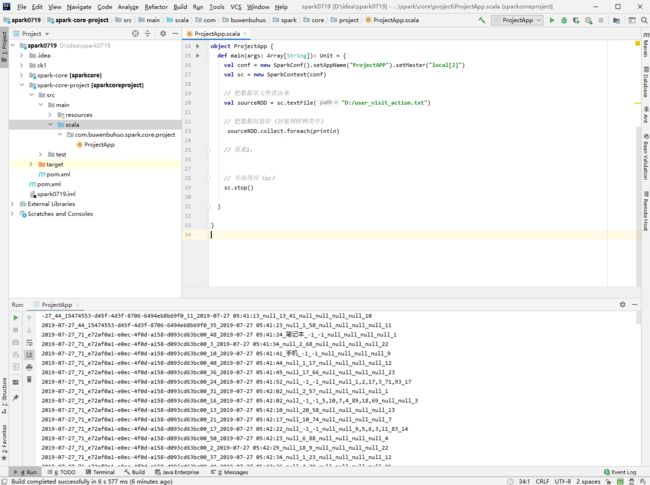
- 1. 测试看是否能够读取数据
package com.buwenbuhuo.spark.core.project
import org.apache.spark.{SparkConf, SparkContext}
/**
**
*
* @author 不温卜火
* *
* @create 2020-07-28 14:20
**
* MyCSDN :https://buwenbuhuo.blog.csdn.net/
*/
object ProjectApp {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("ProjectAPP").setMaster("local[2]")
val sc = new SparkContext(conf)
// 把数据从文件读出来
val sourceRDD = sc.textFile("D:/user_visit_action.txt")
// 把数据封装好(封装到样例类中)
sourceRDD.collect.foreach(println)
// 需求1:
// 关闭项目(sc)
sc.stop()
}
}
- 运行成功结果
3. 完整项目代码
- 1. 封装用户行为的bean类
UserVisitAction
package com.buwenbuhuo.spark.core.project.bean
/**
**
@author 不温卜火
**
* @create 2020-07-28 15:25
**
* MyCSDN :https://buwenbuhuo.blog.csdn.net/
*/
/**
* 用户访问动作表
*
* @param date 用户点击行为的日期
* @param user_id 用户的ID
* @param session_id Session的ID
* @param page_id 某个页面的ID
* @param action_time 动作的时间点
* @param search_keyword 用户搜索的关键词
* @param click_category_id 某一个商品品类的ID
* @param click_product_id 某一个商品的ID
* @param order_category_ids 一次订单中所有品类的ID集合
* @param order_product_ids 一次订单中所有商品的ID集合
* @param pay_category_ids 一次支付中所有品类的ID集合
* @param pay_product_ids 一次支付中所有商品的ID集合
* @param city_id 城市 id
*/
case class UserVisitAction(date: String,
user_id: Long,
session_id: String,
page_id: Long,
action_time: String,
search_keyword: String,
click_category_id: Long,
click_product_id: Long,
order_category_ids: String,
order_product_ids: String,
pay_category_ids: String,
pay_product_ids: String,
city_id: Long)
// 封装最终写入到数据库的数据
case class CategorySession(categoryId: String,
sessionId: String,
clickCount: Long)
- 2. 定义用到的累加器
package com.buwenbuhuo.spark.core.project.acc
import com.buwenbuhuo.spark.core.project.bean.UserVisitAction
import org.apache.spark.util.AccumulatorV2
import scala.collection.mutable
/**
**
* @author 不温卜火
* *
* @create 2020-07-29 12:16
**
* MyCSDN :https://buwenbuhuo.blog.csdn.net/
*/
// in: UserVisitAction out : Map[(种类,“click”) -> count] (品类,"order") -> (品类,"pay") ,-> count
class CategoryAcc extends AccumulatorV2[UserVisitAction,mutable.Map[(String, String), Long]]{
self => //自身类型
private val map: mutable.Map[(String, String), Long] = mutable.Map[(String, String), Long]()
// 判断累加器是否为“零”
override def isZero: Boolean = map.isEmpty
// 复制累加器
override def copy(): AccumulatorV2[UserVisitAction, mutable.Map[(String, String), Long]] = {
val acc: CategoryAcc = new CategoryAcc
map.synchronized{
acc.map ++= map // 可变集合,不应该直接赋值,应该进行数据的复制
}
acc
}
// 重置累加器 这个方法调用完之后,isZero必须返回ture
override def reset(): Unit = map.clear() // 可变集合应该做一个清楚
// 分区内累加
override def add(v: UserVisitAction): Unit = {
// 分别计算3个指标
// 对不同的行为做不同的处理 if语句 或 匹配模式
v match {
// 点击行为
case action if action.click_category_id != -1 =>
// (cid,"click") -> 100
val key:(String,String) = (action.click_category_id.toString, "click")
map += key -> (map.getOrElse(key,0L) + 1L)
// 下单行为 切出来的是字符串"null",不是空null
case action if action.order_category_ids != "null" =>
// 切出来这次下单的多个品类
val cIds: Array[String] = action.order_category_ids.split(",")
cIds.foreach(cid => {
val key:(String,String) = (cid,"order")
map += key -> (map.getOrElse(key,0L) + 1L)
})
// 支付行为
case action if action.pay_category_ids != "null" =>
// 切出来这次下单的多个品类
val cIds: Array[String] = action.pay_category_ids.split(",")
cIds.foreach(cid => {
val key:(String,String) = (cid,"pay")
map += key -> (map.getOrElse(key,0L) + 1L)
})
// 其他非正常情况,做任何处理
case _ =>
}
}
// 分区间的合并
override def merge(other: AccumulatorV2[UserVisitAction, mutable.Map[(String, String), Long]]): Unit = {
// 把other中的map合并到this(self)的map中
// 合并map
other match {
case o: CategoryAcc =>
// 1. 遍历 other的map,然后把变量的导致和self的mao进行相加
/* o.map.foreach{
case ((cid,action),count) =>
self.map += (cid,action) -> (self.map.getOrElse((cid,action),0L) + count)
}*/
// 2, 对other的map进行折叠,把结果都折叠到self的map中
// 如果是可变map,则所有的变化都是在原集合中发生变化,最后的值可以不用再一次添加
// 如果是不可变map,则计算的结果,必须重新赋值给原来的map变量
self.map ++= o.map.foldLeft(self.map){
case (map,(cidAction,count)) =>
map += cidAction -> (map.getOrElse(cidAction,0L) + count)
map
}
case _=>
throw new UnsupportedOperationException
}
}
// 最终的返回值
override def value: mutable.Map[(String, String), Long] = map
}
- 3. 首页APP
package com.buwenbuhuo.spark.core.project.app
import com.buwenbuhuo.spark.core.project.bean.{CategoryCountInfo, UserVisitAction}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
**
*@author 不温卜火
**
* @create 2020-07-29 12:18
**
* MyCSDN :https://buwenbuhuo.blog.csdn.net/
*/
object ProjectApp {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("ProjectAPP").setMaster("local[2]")
val sc: SparkContext = new SparkContext(conf)
// 把数据从文件读出来
val sourceRDD: RDD[String] = sc.textFile("D:/user_visit_action.txt")
// 把数据封装好(封装到样例类中)
// sourceRDD.collect.foreach(println)
val userVisitActionRDD: RDD[UserVisitAction] = sourceRDD.map(line => {
val fields: Array[String] = line.split("_")
UserVisitAction(
fields(0),
fields(1).toLong,
fields(2),
fields(3).toLong,
fields(4),
fields(5),
fields(6).toLong,
fields(7).toLong,
fields(8),
fields(9),
fields(10),
fields(11),
fields(12).toLong)
})
// 需求1:
CategoryTopApp.calcCatgoryTop10(sc , userVisitActionRDD)
// 关闭项目(sc)
sc.stop()
}
}
- 4. 计算Top10 热门品类的具体代码
package com.buwenbuhuo.spark.core.project.app
import com.buwenbuhuo.spark.core.project.acc.CategoryAcc
import com.buwenbuhuo.spark.core.project.bean.{CategoryCountInfo, UserVisitAction}
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import scala.collection.mutable
/**
**
*
* @author 不温卜火
* *
* @create 2020-07-29 13:21
**
* MyCSDN : https://buwenbuhuo.blog.csdn.net/
*
*/
object CategoryTopApp {
def calcCatgoryTop10(sc: SparkContext, userVisitActionRDD: RDD[UserVisitAction]): List[CategoryCountInfo] = {
// 使用累加器完成3个指标的累加: 点击 下单量 支付量
val acc: CategoryAcc = new CategoryAcc
sc.register(acc)
userVisitActionRDD.foreach(action => acc.add(action))
// 1. 把一个品类的三个指标封装到一个map中
val cidActionCountGrouped: Map[String, mutable.Map[(String, String), Long]] = acc.value.groupBy(_._1._1)
// 2. 转换成 CategoryCountInfo 类型的集合, 方便后续处理
val categoryCountInfoArray: List[CategoryCountInfo] = cidActionCountGrouped.map {
case (cid, map) =>
CategoryCountInfo(cid,
map.getOrElse((cid, "click"), 0L),
map.getOrElse((cid, "order"), 0L),
map.getOrElse((cid, "pay"), 0L)
)
}.toList
// 3. 对数据进行排序取top10
val result: List[CategoryCountInfo] = categoryCountInfoArray.sortBy(info => (-info.clickCount, -info.orderCount, -info.payCount))
.take(10)
// 4. 返回top10品类
result
}
}
/*
利用累加器完成
*/
- 5. 运行结果

本次的分享就到这里了,

好书不厌读百回,熟读课思子自知。而我想要成为全场最靓的仔,就必须坚持通过学习来获取更多知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
如果我的博客对你有帮助、如果你喜欢我的博客内容,请“点赞” “评论”“收藏”一键三连哦!听说点赞的人运气不会太差,每一天都会元气满满呦!如果实在要白嫖的话,那祝你开心每一天,欢迎常来我博客看看。
码字不易,大家的支持就是我坚持下去的动力。点赞后不要忘了关注我哦!