启动spark服务,解决端口占用的踩坑过程及使用Phoenix操作hbase数据表
前言
在尝试运行sparksql,发现spark服务没有启动,且发现其端口占用!
问题处理过程
在liunx系统中,搜索以下是否有spark服务?
[root@A ~]# ps -ef|grep spark
root 16970 25666 0 18:19 pts/2 00:00:00 grep --color=auto spark没有,就去启动spark服务
启动spark服务
[root@A sbin]# cd /home/software/spark2.2/sbin/
找到start-thriftserver.sh 脚本,进行启动
[root@A sbin]# ./start-thriftserver.sh
starting org.apache.spark.sql.hive.thriftserver.HiveThriftServer2, logging to /home/software/spark2.2/logs/spark-root-org.apache.spark.sql.hive.thriftserver.HiveThriftServer2-1-cdh03.out
打开日志,查看是否启动成功?
20/07/01 17:52:36 ERROR thrift.ThriftCLIService: Error starting HiveServer2: could not start ThriftBinaryCLIService
org.apache.thrift.transport.TTransportException: Could not create ServerSocket on address 0.0.0.0/0.0.0.0:10000.
at org.apache.thrift.transport.TServerSocket.(TServerSocket.java:109)
at org.apache.thrift.transport.TServerSocket.(TServerSocket.java:91)
at org.apache.thrift.transport.TServerSocket.(TServerSocket.java:87)
at org.apache.hive.service.auth.HiveAuthFactory.getServerSocket(HiveAuthFactory.java:242)
at org.apache.hive.service.cli.thrift.ThriftBinaryCLIService.run(ThriftBinaryCLIService.java:66)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.net.BindException: Address already in use (Bind failed)
at java.net.PlainSocketImpl.socketBind(Native Method)
at java.net.AbstractPlainSocketImpl.bind(AbstractPlainSocketImpl.java:387)
at java.net.ServerSocket.bind(ServerSocket.java:375)
at org.apache.thrift.transport.TServerSocket.(TServerSocket.java:106)
... 5 more
20/07/01 17:52:36 INFO server.HiveServer2: Shutting down HiveServer2
发现spark端口10000被占用。
查看spark端口10000被谁占用
[root@A logs]# netstat -tunlp|grep 10000
tcp 0 0 0.0.0.0:10000 0.0.0.0:* LISTEN 111409/java
[root@A logs]# ps -ef|grep 111409
root 96683 94013 0 17:53 pts/0 00:00:00 grep --color=auto 111409
hive 111409 514 0 May20 ? 01:03:23 /home/software/jdk1.8/bin/java -Xmx256m -Dhadoop.log.dir=/home/software/cloudera-manager/cloudera/parcels/CDH-5.12.1-1.cdh5.12.1.p0.3/lib/hadoop/logs -Dhadoop.log.file=hadoop.log -Dhadoop.home.dir=/home/software/cloudera-manager/cloudera/parcels/CDH-5.12.1-1.cdh5.12.1.p0.3/lib/hadoop -Dhadoop.id.str= -Dhadoop.root.logger=INFO,console -Djava.library.path=/home/software/cloudera-manager/cloudera/parcels/CDH-5.12.1-1.cdh5.12.1.p0.3/lib/hadoop/lib/native -Dhadoop.policy.file=hadoop-policy.xml -Djava.net.preferIPv4Stack=true -Djava.net.preferIPv4Stack=true -Djava.net.preferIPv4Stack=true -Xms4294967296 -Xmx4294967296 -XX:MaxPermSize=512M -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=70 -XX:+CMSParallelRemarkEnabled -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/home/tmp/hive_hive-HIVESERVER2-f6ff52da0d69207d1c238828ec506c2f_pid111409.hprof -XX:OnOutOfMemoryError=/home/software/cloudera-manager/cm-5.12.1/lib64/cmf/service/common/killparent.sh -Dhadoop.security.logger=INFO,NullAppender org.apache.hadoop.util.RunJar /home/software/cloudera-manager/cloudera/parcels/CDH-5.12.1-1.cdh5.12.1.p0.3/lib/hive/lib/hive-service-1.1.0-cdh5.12.1.jar org.apache.hive.service.server.HiveServer2 --hiveconf hive.aux.jars.path=file:///home/software/cloudera-manager/cloudera/parcels/CDH-5.12.1-1.cdh5.12.1.p0.3/lib/hive/auxlib/hive-exec-1.1.0-cdh5.12.1-core.jar,file:///home/software/cloudera-manager/cloudera/parcels/CDH-5.12.1-1.cdh5.12.1.p0.3/lib/hive/auxlib/hive-exec-core.jar
hive 111461 111409 0 May20 ? 00:00:00 python2.7 /home/software/cloudera-manager/cm-5.12.1/lib64/cmf/agent/build/env/bin/cmf-redactor /home/software/cloudera-manager/cm-5.12.1/lib64/cmf/service/hive/hive.sh hiveserver2发现被hiveserver2占用。
修改hiveserver2占用的10000端口
进入到CM的管理界面,找到hive标签

点开,找到“配置”-->"HiveServer2 "-->" 端口和地址"-->"HiveServer2 端口"
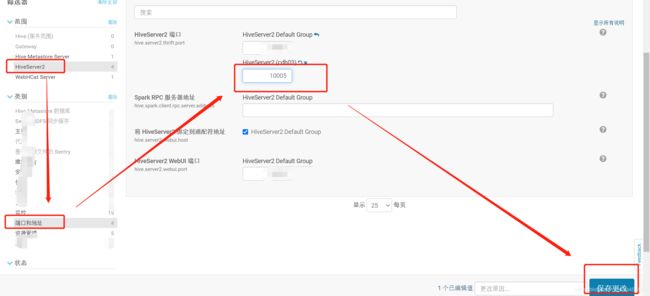
把HiveServer2 端口修改10000端口为10005,然后保存修改的配置,
再次回到CM的管理界面,会发现Hive的标签旁边有一个重启配置,

点击![]() ,等待重启完毕,即可以释放10000端口
,等待重启完毕,即可以释放10000端口
然后再次启动spark服务即可!
重新启动spark服务
和上面的操作一样,查看日志,spark正常执行启动!
[root@cdh03 logs]# tail -n 100 spark-root-org.apache.spark.sql.hive.thriftserver.HiveThriftServer2-1-cdh03.out
tail: cannot open ‘100’ for reading: No such file or directory
==> spark-root-org.apache.spark.sql.hive.thriftserver.HiveThriftServer2-1-cdh03.out <==
user: root
20/07/01 17:58:21 INFO cluster.YarnClientSchedulerBackend: Application application_1589967654982_0039 has started running.
20/07/01 17:58:21 INFO util.Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 34246.
20/07/01 17:58:21 INFO netty.NettyBlockTransferService: Server created on 172.16.7.142:34246
20/07/01 17:58:21 INFO storage.BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
…………
20/07/01 17:58:37 INFO thrift.ThriftCLIService: Starting ThriftBinaryCLIService on port 10000 with 5...500 worker threads
20/07/01 18:00:44 INFO thrift.ThriftCLIService: Client protocol version: HIVE_CLI_SERVICE_PROTOCOL_V6
20/07/01 18:00:44 INFO session.SessionState: Created local directory: /tmp/d3aa2950-7b71-4cde-acba-1472b5dc6f5c_resources
20/07/01 18:00:44 INFO session.SessionState: Created HDFS directory: /tmp/hive/rrrr/d3aa2950-7b71-4cde-acba-1472b5dc6f5c
20/07/01 18:00:44 INFO session.SessionState: Created local directory: /tmp/root/d3aa2950-7b71-4cde-acba-1472b5dc6f5c
20/07/01 18:00:44 INFO session.SessionState: Created HDFS directory: /tmp/hive/rrrr/d3aa2950-7b71-4cde-acba-1472b5dc6f5c/_tmp_space.db
20/07/01 18:00:44 INFO session.HiveSessionImpl: Operation log session directory is created: /tmp/root/operation_logs/d3aa2950-7b71-4cde-acba-1472b5dc6f5c
20/07/01 18:00:44 INFO session.SessionState: Created local directory: /tmp/7d36ab64-afc8-455a-9a8d-025b41b63d90_resources
20/07/01 18:00:44 INFO session.SessionState: Created HDFS directory: /tmp/hive/root/7d36ab64-afc8-455a-9a8d-025b41b63d90
20/07/01 18:00:44 INFO session.SessionState: Created local directory: /tmp/root/7d36ab64-afc8-455a-9a8d-025b41b63d90
20/07/01 18:00:44 INFO session.SessionState: Created HDFS directory: /tmp/hive/root/7d36ab64-afc8-455a-9a8d-025b41b63d90/_tmp_space.db
20/07/01 18:00:44 INFO client.HiveClientImpl: Warehouse location for Hive client (version 1.2.1) is file:/home/software/spark2.2/sbin/spark-warehouse
20/07/01 18:00:44 INFO thriftserver.SparkExecuteStatementOperation: Running query 'USE default' with 7f487f06-9710-4879-9fed-884f27183883
20/07/01 18:00:44 INFO execution.SparkSqlParser: Parsing command: USE default
20/07/01 18:00:45 INFO metastore.HiveMetaStore: 1: get_database: default
…………
20/07/01 18:00:46 INFO thriftserver.SparkExecuteStatementOperation: Result Schema: StructType(StructField(databaseName,StringType,false))Phoenix操作hbase数据表
Apache Phoenix相当于一个Java中间件,提供jdbc连接,操作hbase数据表,Phoenix 使得Hbase 支持通过JDBC的方式进行访问,并将你的SQL查询转换成Hbase的扫描和相应的动作。
启动Phoenix
[root@A logs]# cd /home/software/phoenix/phoenix-4.11.0-HBase-1.2/bin/若不连接集群,直接执行 sqlline.py
[root@A bin]# ./sqlline.py
Setting property: [incremental, false]
Setting property: [isolation, TRANSACTION_READ_COMMITTED]
issuing: !connect jdbc:phoenix:localhost:2181:/hbase none none org.apache.phoenix.jdbc.PhoenixDriver
Connecting to jdbc:phoenix:localhost:2181:/hbase
20/07/01 18:02:22 WARN zookeeper.ClientCnxn: Session 0x0 for server null, unexpected error, closing socket connection and attempting reconnect
java.net.ConnectException: Connection refused
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:717)
at org.apache.phoenix.shaded.org.apache.zookeeper.ClientCnxnSocketNIO.doTransport(ClientCnxnSocketNIO.java:361)
at org.apache.phoenix.shaded.org.apache.zookeeper.ClientCnxn$SendThread.run(ClientCnxn.java:1081)
20/07/01 18:02:24 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Connected to: Phoenix (version 4.11)
Driver: PhoenixEmbeddedDriver (version 4.11)
Autocommit status: true
Transaction isolation: TRANSACTION_READ_COMMITTED
Building list of tables and columns for tab-completion (set fastconnect to true to skip)...
2564/2564 (100%) Done
Done
sqlline version 1.2.0
0: jdbc:phoenix:localhost:2181:/hbase> 若要连接集群,执行 sqlline.py后面要加上zookeeper的集群IP地址
[root@A bin]$ ./bin/sqlline.py 192.168.100.21,192.168.100.22,192.168.100.23:2181
Setting property: [incremental, false]
Setting property: [isolation, TRANSACTION_READ_COMMITTED]
issuing: !connect jdbc:phoenix:192.168.100.21,192.168.100.22,192.168.100.23:2181 none none org.apache.phoenix.jdbc.PhoenixDriver
Connecting to jdbc:phoenix:192.168.100.21,192.168.100.22,192.168.100.23:2181
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/phoenix-4.14.0-HBase-1.2/phoenix-4.14.0-HBase-1.2-client.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/hadoop-2.7.6/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
18/08/21 02:28:30 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Connected to: Phoenix (version 4.14)
Driver: PhoenixEmbeddedDriver (version 4.14)
Autocommit status: true
Transaction isolation: TRANSACTION_READ_COMMITTED
Building list of tables and columns for tab-completion (set fastconnect to true to skip)...
133/133 (100%) Done
Done
sqlline version 1.2.0
0: jdbc:phoenix:192.168.100.21,192.168.100.22>友情链接
- https://www.cnblogs.com/frankdeng/p/9536450.html
- https://www.jianshu.com/p/3a30f3705af2
- https://www.cnblogs.com/zlslch/p/7096353.html