【若泽大数据实战第十七天】Hive - DDL + DML Hive日志路径修改
前言:
上一个章节,若泽给我们讲的第一堂课Hive,详细的总结了,有关Hive的各种信息,本次课程讲讲Hive的 DDL
修改Hive日志路径
【若泽大数据实战】
在Hive中,默认的日志路径是在/tmp底下,一般Linux或者CentOS系统会一个月自动清理一次tmp底下的东西,所以要将日志进行更换位置。
首先需要cp一份hive-log4j.properties文件,在默认安装好Hive后是没有的。
![]()
编辑修改路径

查看日志可以发现Hive的默认底层是MapReduce

hive的环境下,输入代码后发现输入有错误时,想用Backspace删除错误命令时,键盘无反应,操作很简单:
无法删除

【若泽大数据面试题】
Hive的信息存放在哪里?
1、Hive的数据存放在HDFS之上(真实数据)
2、Hive的元数据可以存放在RDBMS之上(元数据)

Database
Hive中包含了多个数据库,默认的数据库为default,无论你是否创建数据库,默认都会存在,对应于HDFS目录是/user/hive/warehouse,可以通过hive.metastore.warehouse.dir参数进行配置(hive-site.xml中配置)
创建一个Hive数据库,查看存储在hdfs的什么路径上


配置完hadoop启动的时候出现如下警告信息:

如果是64位直接在log4j日志中去除告警信息。在/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop/log4j.properties文件中添加
- log4j.logger.org.apache.hadoop.util.NativeCodeLoader=ERROR
现在显示正常,刚刚创建的Hive数据库也存在

DDL(Data Definition Language)
描述Hive表数据的结构:
打开Hive官网:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL

Create Database
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[WITH DBPROPERTIES (property_name=property_value, ...)];
IF NOT EXISTS:加上这句话代表判断数据库是否存在,不存在就会创建,存在就不会创建(生产中一定要添加IF NOT EXISTS)。 如:create database if not exists dbname;
COMMENT:数据库的描述
LOCATION:创建数据库的地址,不加默认在/user/hive/warehouse/路径下
WITH DBPROPERTIES:数据库的属性
【若泽大数据实战】
【重点】每当我们使用一个Hive中的SQL时,一定要知道这条语句对应的元数据信息是怎么存储的,
创建一张表。一个数据库,注释信息再哪里 DB的存放在哪里,一下我做了详细实验
创建一个数据库指定路径,往库中插入一张表:
hive> create database hive2 LOCATION '/ruozedata_03';

[hadoop@hadoop000 ~]$ hadoop fs -ls /

hive> use hive2; hive> create table b(id int);

查看相关创建后的信息,发现有b表,然后看文件的属性,最前面是一个d,ruozedata_03数据库就是一个文件夹

测试创建一个数据库并给数据库添加加一个备注,增加一些描述的信息,信息是key value

查看刚刚每个创建的数据库的信息
hive> show databases;
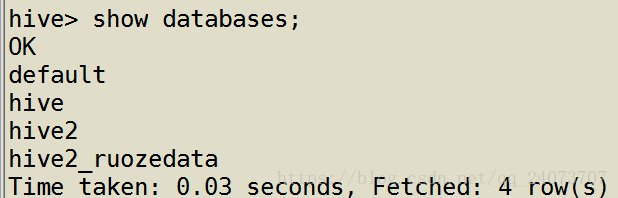
hive hdfs://hadoop000:9000/user/hive/warehouse/hive.db(路径) hadoop USER
Time taken: 0.028 seconds, Fetched: 1 row(s)
hive> desc database hive2;
hive2 hdfs://hadoop000:9000/ruozedata_03 (路径) hadoop USERTime taken: 0.09 seconds, Fetched: 1 row(s)
hive> desc database hive2_ruozedata;
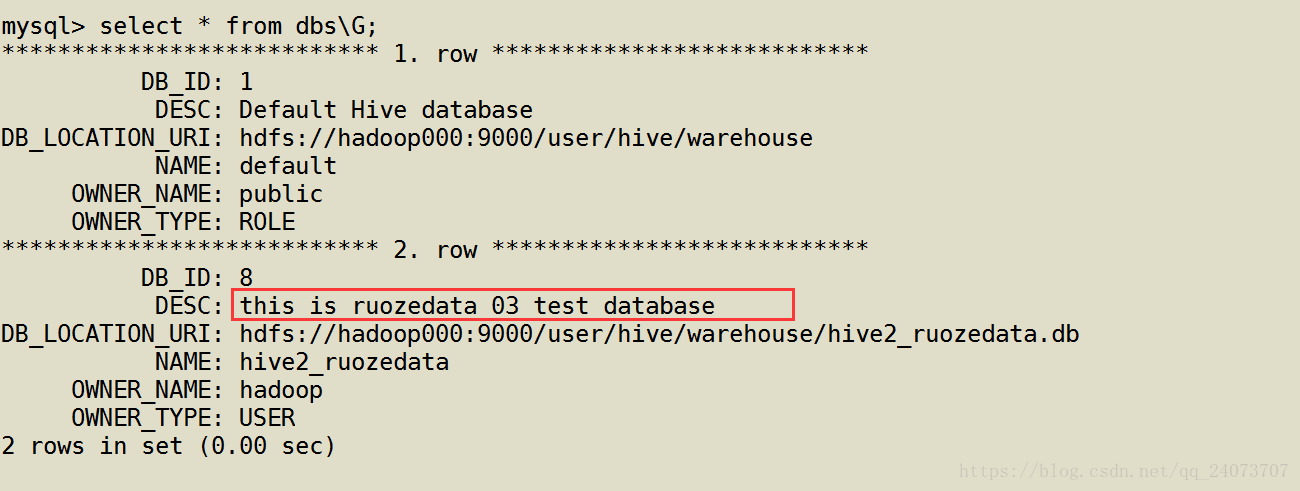
hive2_ruozedata this is ruozedata 03 test database(描述信息) hdfs://hadoop000:9000/user/hive/warehouse/hive2_ruozedata.db hadoop USER
hive> desc database default;(默认数据库)
default Default Hive database hdfs://hadoop000:9000/user/hive/warehouse(指定路径并没有文件) public ROLE

mysql> use ruozedata_basic03 ;
mysql> show tables;
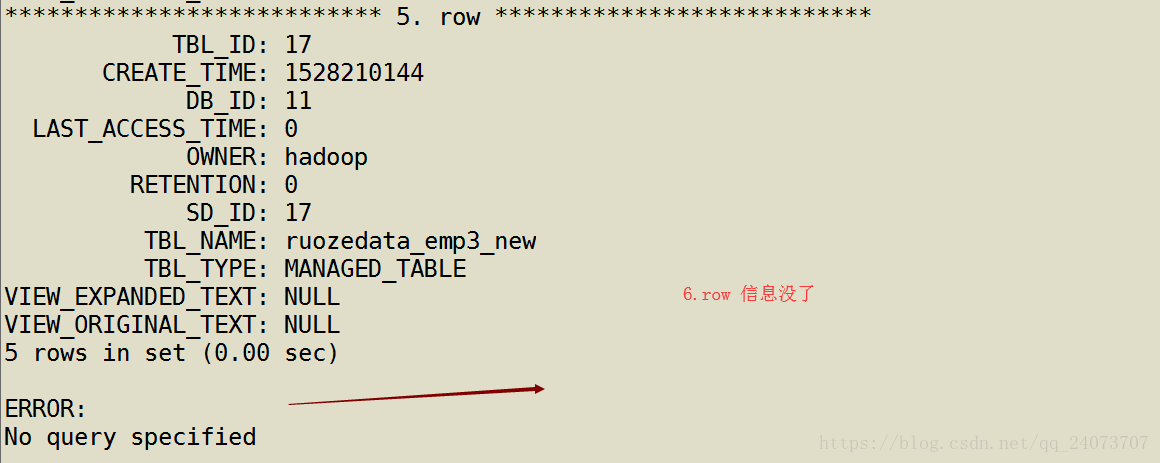
mysql> select * from dbs\G;

Drop Database
DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE];
RESTRICT:默认是restrict,如果该数据库还有表存在则报错;
CASCADE:级联删除数据库(当数据库还有表时,级联删除表后在删除数据库)。
【若泽大数据实战】
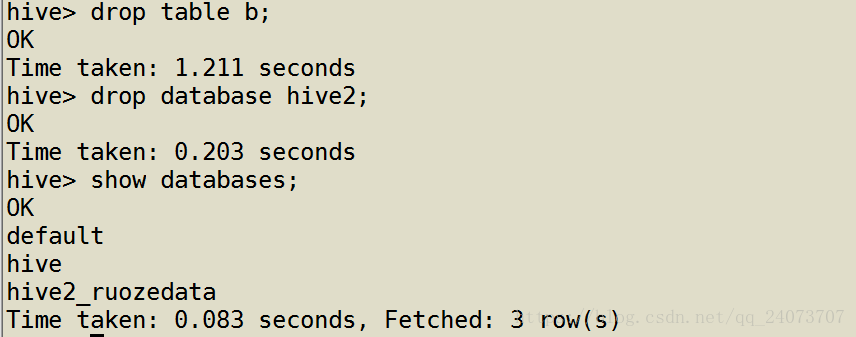
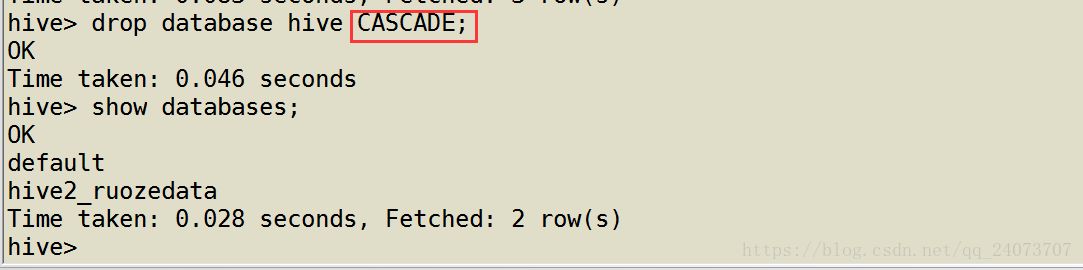
把刚刚创建的hive2表直接删除,会有报错,因为Hive2里面有一张B表,所以无法删除

先删除b表再删除数据库Hive2,查看是否有Hive2数据库存在
强制删除数据库(生产中不能使用)
hive> drop database hive CASCADE;
Alter Database
ALTER (DATABASE|SCHEMA) database_name SET DBPROPERTIES (property_name=property_value, ...); -- (Note: SCHEMA added in Hive 0.14.0)
ALTER (DATABASE|SCHEMA) database_name SET OWNER [USER|ROLE] user_or_role; -- (Note: Hive 0.13.0 and later; SCHEMA added in Hive 0.14.0)
ALTER (DATABASE|SCHEMA) database_name SET LOCATION hdfs_path; -- (Note: Hive 2.2.1, 2.4.0 and later)
Use Database
USE database_name;
USE DEFAULT;
Show Databases
SHOW (DATABASES|SCHEMAS) [LIKE 'identifier_with_wildcards'
“ | ”:可以选择其中一种
“[ ]”:可选项
LIKE ‘identifier_with_wildcards’:模糊查询数据库
Describe Database
DESCRIBE DATABASE [EXTENDED] db_name;
DESCRIBE DATABASE db_name:查看数据库的描述信息和文件目录位置路径信息;
EXTENDED:加上数据库键值对的属性信息。
hive> describe database default;
OK
default Default Hive database hdfs://hadoop1:9000/user/hive/warehouse public ROLE
Time taken: 0.065 seconds, Fetched: 1 row(s)
hive>
hive> describe database extended hive2;
OK
hive2 it is my database hdfs://hadoop1:9000/user/hive/warehouse/hive2.db hadoop USER {date=2018-08-08, creator=zhangsan}
Time taken: 0.135 seconds, Fetched: 1 row(s)Hive的基本数据类型&分隔符
官网:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Types
生产中常用数据类型: int bigint float double decimal (数值类型选择一个其他都用string) string (函数也可以用)
生产中不建议使用数据类型:date/timestamp boolean(不建议使用)-> 都用string类型存
分隔符
行:\n 行直接转换用的分隔符列:^A \001 列转换用的分隔符
map/struct/array
【重要】一般情况下,在创建表的时候就直接指定了分隔符:\t ,
Table
Hive中的表又分为内部表和外部表 ,Hive 中的每张表对应于HDFS上的一个文件夹,HDFS目录为:/user/hadoop/hive/warehouse/[databasename.db]/table
create table xxx xxx 创建表默认使用的是 MANAGED_TABLE: 内部表
内部表创建:
hive> create table ruozedata_emp_managed as select * from ruozedata_emp;
hive> desc formatted ruozedata_emp_managed;
看到下面表的类型,MANAGED_TABLE

MySQL中查看数据信息
mysql> show databases;
mysql> use ruozedata_basic03
mysql> select * from tbls \G;

查看这个数据在HDFS上面什么地方
[hadoop@hadoop000bin]$
hadoop fs -ls hdfs://hadoop000:9000/user/hive/warehouse/hive3.db/ruozedata_emp_managed

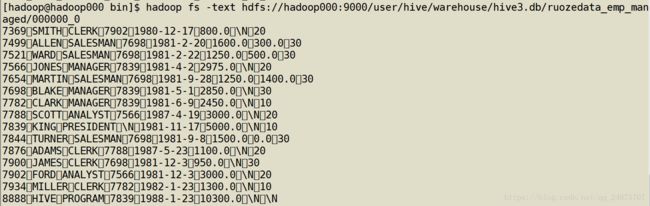
查看 000000_0 是否有数据
[hadoop@hadoop000 bin]$
hadoop fs -text hdfs://hadoop000:9000/user/hive/warehouse/hive3.db/ruozedata_emp_managed/000000_0
删除表 ruozedata_emp_managed 我们看看会发身什么
hive> drop table ruozedata_emp_managed;

hdfs上数据信息,没有

hdfs上没有这张表
![]()
元数据信息也查不到这张表
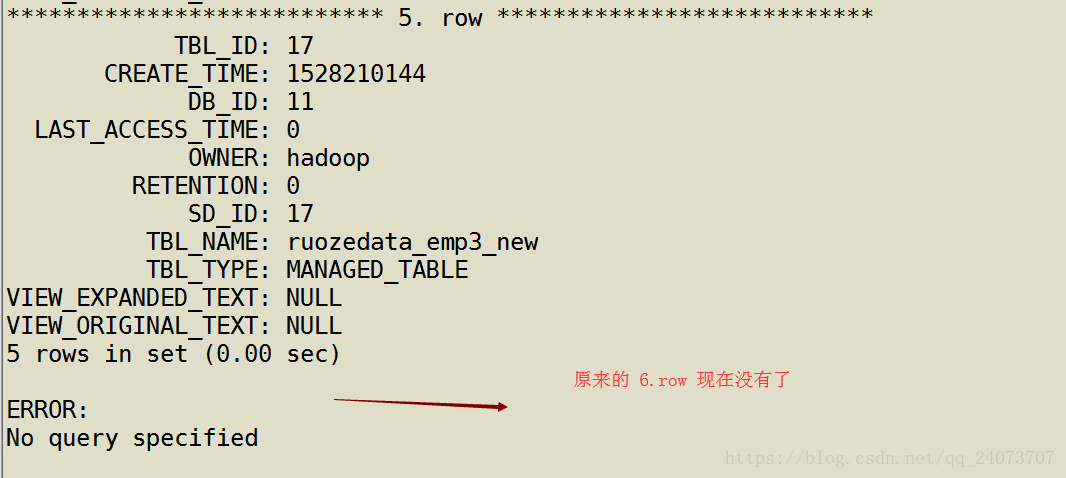
内部表总结:只要drop表,就会把hdfs + 元数据的数据全部都删除。
EXTERNAL:外部表
创建一个外部表
create EXTERNAL table ruozedata_emp_external
(empno int, ename string, job string, mgr int, hiredate string, salary double, comm double, deptno int)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LOCATION "/ruozedata/external/emp" ; (指定路径)

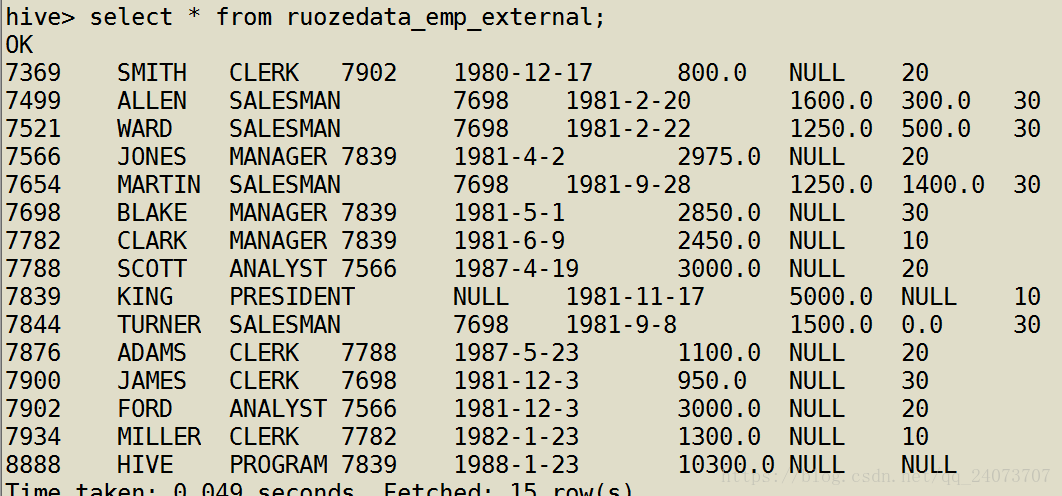
hive> desc formatted ruozedata_emp_external;

在hdfs上查一下有没有数据


【重要】查看到有数据了,以上的这些操作是在工作中非常常见的,只要把数据移动到目录上去立刻就查的出来。
查看 MySQL表的类型信息
mysql> select * from tbls\G;

删除外部表 ruozedata_emp_external
hive> drop table ruozedata_emp_external


外部表总结:只要drop表,就会把元数据的数据删除,但是HDFS上的数据是保留的。
Hive上有两种类型的表,一种是Managed Table(默认的),另一种是External Table(加上EXTERNAL关键字)。内部表数据由Hive自身管理,外部表数据由HDFS管理;
它俩的主要区别在于:当我们drop表时,Managed Table会同时删去data(存储在HDFS上)和meta data(存储在MySQL),而External Table只会删meta data。内部表数据存储的位置是hive.metastore.warehouse.dir(默认:/user/hive/warehouse),外部表数据的存储位置由自己制定; 对内部表的修改会将修改直接同步给元数据,而对外部表的表结构和分区进行修改,则需要修复(MSCK REPAIR TABLE table_name;)
生产中99%都用到的是外部表,因为可以有一份备份,如果删除表用LOAD DATA LOCAL INPATH 在传一份就可以了。
生产中1%用到的内部表的情况,外面的数据传过来,你这里可建立外部表,如果表删没了再导一份。
Create Table
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name -- (Note: TEMPORARY available in Hive 0.14.0 and later)
[(col_name data_type [COMMENT col_comment], ... [constraint_specification])]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[SKEWED BY (col_name, col_name, ...) -- (Note: Available in Hive 0.10.0 and later)]
ON ((col_value, col_value, ...), (col_value, col_value, ...), ...)
[STORED AS DIRECTORIES]
[
[ROW FORMAT row_format]
[STORED AS file_format]
| STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)] -- (Note: Available in Hive 0.6.0 and later)
]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)] -- (Note: Available in Hive 0.6.0 and later)
[AS select_statement]; -- (Note: Available in Hive 0.5.0 and later; not supported for external tables)
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
LIKE existing_table_or_view_name
[LOCATION hdfs_path];
data_type
: primitive_type
| array_type
| map_type
| struct_type
| union_type -- (Note: Available in Hive 0.7.0 and later)
primitive_type
: TINYINT
| SMALLINT
| INT
| BIGINT
| BOOLEAN
| FLOAT
| DOUBLE
| DOUBLE PRECISION -- (Note: Available in Hive 2.2.0 and later)
| STRING
| BINARY -- (Note: Available in Hive 0.8.0 and later)
| TIMESTAMP -- (Note: Available in Hive 0.8.0 and later)
| DECIMAL -- (Note: Available in Hive 0.11.0 and later)
| DECIMAL(precision, scale) -- (Note: Available in Hive 0.13.0 and later)
| DATE -- (Note: Available in Hive 0.12.0 and later)
| VARCHAR -- (Note: Available in Hive 0.12.0 and later)
| CHAR -- (Note: Available in Hive 0.13.0 and later)
array_type
: ARRAY < data_type >
map_type
: MAP < primitive_type, data_type >
struct_type
: STRUCT < col_name : data_type [COMMENT col_comment], ...>
union_type
: UNIONTYPE < data_type, data_type, ... > -- (Note: Available in Hive 0.7.0 and later)
row_format
: DELIMITED [FIELDS TERMINATED BY char [ESCAPED BY char]] [COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
[NULL DEFINED AS char] -- (Note: Available in Hive 0.13 and later)
| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]
file_format:
: SEQUENCEFILE
| TEXTFILE -- (Default, depending on hive.default.fileformat configuration)
| RCFILE -- (Note: Available in Hive 0.6.0 and later)
| ORC -- (Note: Available in Hive 0.11.0 and later)
| PARQUET -- (Note: Available in Hive 0.13.0 and later)
| AVRO -- (Note: Available in Hive 0.14.0 and later)
| INPUTFORMAT input_format_classname OUTPUTFORMAT output_format_classname
constraint_specification:
: [, PRIMARY KEY (col_name, ...) DISABLE NOVALIDATE ]
[, CONSTRAINT constraint_name FOREIGN KEY (col_name, ...) REFERENCES table_name(col_name, ...) DISABLE NOVALIDATE 按照按照官方文档给的信息,创建一个表看看详细信息
hive> create database hive3;![]()
hive> use hive3;
hive> CREATE TABLE hive3_test
> (id int comment 'this is id', name string comment 'this id name' )
> comment 'this is hive3_test'
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY '\t' ;

查看详细信息
hive> desc formatted hive3_test;


对于存放数据库的路径我们可以修改(一般不做修改)
[hadoop@hadoop000 conf]$ vi hive-site.xml
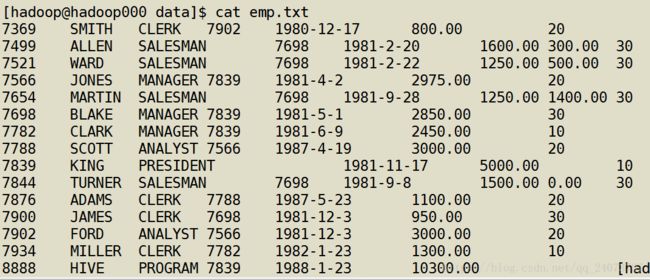
从Oracle里面搞了一张emp表来做实验
7369 SMITH CLERK 7902 1980-12-17 800.00 20
7499 ALLEN SALESMAN 7698 1981-2-20 1600.00 300.00 30
7521 WARD SALESMAN 7698 1981-2-22 1250.00 500.00 30
7566 JONES MANAGER 7839 1981-4-2 2975.00 20
7654 MARTIN SALESMAN 7698 1981-9-28 1250.00 1400.00 30
7698 BLAKE MANAGER 7839 1981-5-1 2850.00 30
7782 CLARK MANAGER 7839 1981-6-9 2450.00 10
7788 SCOTT ANALYST 7566 1987-4-19 3000.00 20
7839 KING PRESIDENT 1981-11-17 5000.00 10
7844 TURNER SALESMAN 7698 1981-9-8 1500.00 0.00 30
7876 ADAMS CLERK 7788 1987-5-23 1100.00 20
7900 JAMES CLERK 7698 1981-12-3 950.00 30
7902 FORD ANALYST 7566 1981-12-3 3000.00 20
7934 MILLER CLERK 7782 1982-1-23 1300.00 10
8888 HIVE PROGRAM 7839 1988-1-23 10300.00
还有一个dept表
10 ACCOUNTING NEW YORK
20 RESEARCH DALLAS
30 SALES CHICAGO
40 OPERATIONS BOSTON

创建表ruozedata_emp
create table ruozedata_emp
(empno int, ename string, job string, mgr int, hiredate string, salary double, comm double, deptno int)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t' ;
我们要把本地的数据导入到Hive里面去
官网翻译

LOAD DATA LOCAL INPATH '/home/hadoop/data/emp.txt' OVERWRITE INTO TABLE ruozedata_emp;
local: 从本地文件系统加载数据到hive表
非local:从HDFS文件系统加载数据到hive表 LOAD DATA LOCAL (非本地去掉LOCAL)INPATH '/home/hadoop/
OVERWRITE: 加载数据到表的时候数据的处理方式,覆盖 (生产使用)
非OVERWRITE:追加

表已经加载了numFiles=1(有一个文件)

totalSize=700(文件大小)

查看文件是否已经到了hdfs上
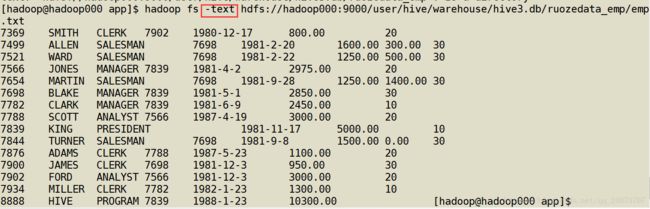
查看数据有没有进入到Hive里面去
hive> use hive3
hive> select * from ruozedata_emp

创建一个新的表数据从ruozedata_emp里面导入:这个作业是通过MapReduce来执行的
hive> CREATE table ruozedata_emp2 as select * from ruozedata_emp;
这里的 * 可以更换成字段,如果只需要ruozedata_emp2的字段就填写字段内容。
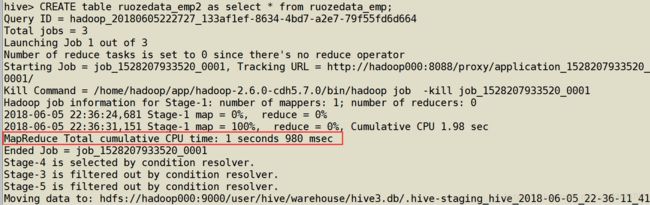
通过YARN可以查看作业的信息
http://192.168.137.130:8088/cluster/apps/FINISHED
作业成功了
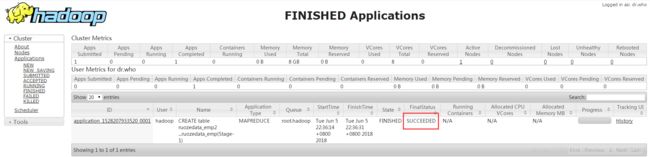
查看数据是否正常
hive> select * from ruozedata_emp2;
测试:拷贝表结构
没有数据单有表结构
hive> CREATE table ruozedata_emp3 like ruozedata_emp;

之前不太理解 RunJar 是什么,后来通过实验知道了,是Hive的客户端

truncate
清空 ruozedata_emp2 表里的数据,但是表还存在
hive> truncate table ruozedata_emp2;


TEMPORARY(临时表)
Hive从0.14.0开始提供创建临时表的功能,表只对当前session有效,session退出后,表自动删除。
语法:CREATE TEMPORARY TABLE …
注意:
1. 如果创建的临时表表名已存在,那么当前session引用到该表名时实际用的是临时表,只有drop或rename临时表名才能使用原始表
2. 临时表限制:不支持分区字段和创建索引
ROW FORMAT
官网解释:
: DELIMITED
[FIELDS TERMINATED BY char [ESCAPED BY char]] [COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char]
[LINES TERMINATED BY char]
[NULL DEFINED AS char]
-- (Note: Available in Hive 0.13 and later)
| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]
DELIMITED:分隔符(可以自定义分隔符);
FIELDS TERMINATED BY char:每个字段之间使用的分割;
例:-FIELDS TERMINATED BY ‘\n’ 字段之间的分隔符为\n;
COLLECTION ITEMS TERMINATED BY char:集合中元素与元素(array)之间使用的分隔符(collection单例集合的跟接口);
MAP KEYS TERMINATED BY char:字段是K-V形式指定的分隔符;
LINES TERMINATED BY char:每条数据之间由换行符分割(默认[ \n ])
一般情况下LINES TERMINATED BY char我们就使用默认的换行符\n,只需要指定FIELDS TERMINATED BY char。
创建demo1表,字段与字段之间使用\t分开,换行符使用默认\n:
hive> create table demo1(
> id int,
> name string
> )
> ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
OK
创建demo2表,并指定其他字段:
hive> create table demo2 (
> id int,
> name string,
> hobbies ARRAY ,
> address MAP
> )
> ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
> COLLECTION ITEMS TERMINATED BY '-'
> MAP KEYS TERMINATED BY ':';
OK Create Table As Select
创建表(拷贝表结构及数据,并且会运行MapReduce作业)
CREATE TABLE emp (
empno int,
ename string,
job string,
mgr int,
hiredate string,
salary double,
comm double,
deptno int
) ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t";
#加载数据
LOAD DATA LOCAL INPATH "/home/hadoop/data/emp.txt" OVERWRITE INTO TABLE emp;
#复制整张表
hive> create table emp2 as select * from emp;
Query ID = hadoop_20180108043232_a3b15326-d885-40cd-89dd-e8fb1b8ff350
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1514116522188_0003, Tracking URL = http://hadoop1:8088/proxy/application_1514116522188_0003/
Kill Command = /opt/software/hadoop/bin/hadoop job -kill job_1514116522188_0003
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2018-01-08 05:21:07,707 Stage-1 map = 0%, reduce = 0%
2018-01-08 05:21:19,605 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.81 sec
MapReduce Total cumulative CPU time: 1 seconds 810 msec
Ended Job = job_1514116522188_0003
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to: hdfs://hadoop1:9000/user/hive/warehouse/hive.db/.hive-staging_hive_2018-01-08_05-20-49_202_8556594144038797957-1/-ext-10001
Moving data to: hdfs://hadoop1:9000/user/hive/warehouse/hive.db/emp2
Table hive.emp2 stats: [numFiles=1, numRows=14, totalSize=664, rawDataSize=650]
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Cumulative CPU: 1.81 sec HDFS Read: 3927 HDFS Write: 730 SUCCESS
Total MapReduce CPU Time Spent: 1 seconds 810 msec
OK
Time taken: 33.322 seconds
hive> show tables;
OK
emp
emp2
order_partition
order_partition2
Time taken: 0.071 seconds, Fetched: 4 row(s)
hive>
#复制表中的一些字段
create table emp3 as select empno,ename from emp;
LIKE
使用like创建表时,只会复制表的结构,不会复制表的数据
hive> create table emp4 like emp;
OK
Time taken: 0.149 seconds
hive> select * from emp4;
OK
Time taken: 0.151 seconds
hive> desc formatted table_name
查询表的详细信息
hive> desc formatted emp;
OK
# col_name data_type comment
empno int
ename string
job string
mgr int
hiredate string
salary double
comm double
deptno int
# Detailed Table Information
Database: hive
Owner: hadoop
CreateTime: Mon Jan 08 05:17:54 CST 2018
LastAccessTime: UNKNOWN
Protect Mode: None
Retention: 0
Location: hdfs://hadoop1:9000/user/hive/warehouse/hive.db/emp
Table Type: MANAGED_TABLE
Table Parameters:
COLUMN_STATS_ACCURATE true
numFiles 1
numRows 0
rawDataSize 0
totalSize 668
transient_lastDdlTime 1515359982
# Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
field.delim \t
serialization.format \t
Time taken: 0.228 seconds, Fetched: 39 row(s)
hive>
通过查询可以列出创建表时的所有信息,并且我们可以在mysql中查询出这些信息(元数据)select * from table_params;
查询数据库下的所有表
hive> show tables;
OK
emp
emp1
emp2
emp3
emp4
order_partition
order_partition2
Time taken: 0.047 seconds, Fetched: 7 row(s)
hive>
查询创建表的语法
拿到DDL语句
hive> show create table emp;
OK
CREATE TABLE `emp`(
`empno` int,
`ename` string,
`job` string,
`mgr` int,
`hiredate` string,
`salary` double,
`comm` double,
`deptno` int)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://hadoop1:9000/user/hive/warehouse/hive.db/emp'
TBLPROPERTIES (
'COLUMN_STATS_ACCURATE'='true',
'numFiles'='1',
'numRows'='0',
'rawDataSize'='0',
'totalSize'='668',
'transient_lastDdlTime'='1515359982')
Time taken: 0.192 seconds, Fetched: 24 row(s)
hive>
Drop Table
DROP TABLE [IF EXISTS] table_name [PURGE]; -- (Note: PURGE available in Hive 0.14.0 and later)
指定PURGE后,数据不会放到回收箱,会直接删除
DROP TABLE删除此表的元数据和数据。如果配置了垃圾箱(并且未指定PURGE),则实际将数据移至.Trash / Current目录。元数据完全丢失
删除EXTERNAL表时,表中的数据不会从文件系统中删除
Alter Table
#重命名
hive> alter table ruozedata_emp3 rename to ruozedata_emp3_new;
OK

insert
创建一个新的表并插入信息
create table ruozedata_emp4 like ruozedata_emp;

select * FROM ruozedata_emp;
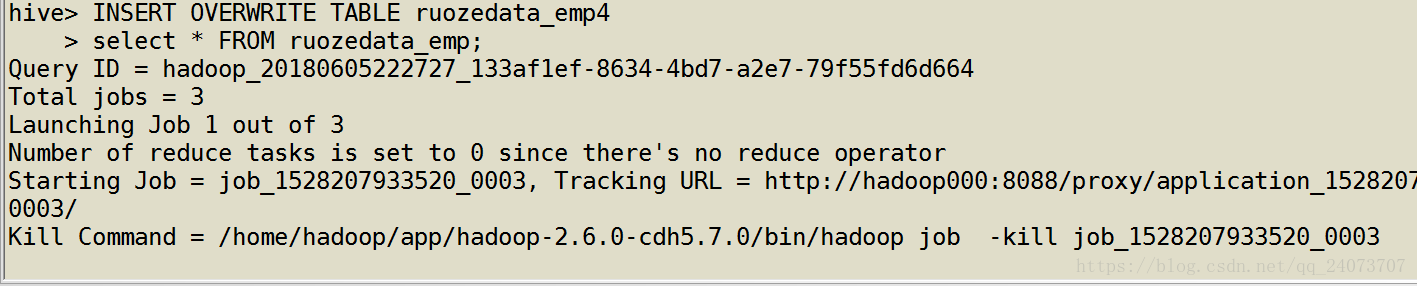
查看结果:
hive> select * from ruozedata_emp4;

按指定字段插入,查看结果
报错显示,不能插入到目标端表内,他们的行的数量不相同,一个有8行,另一个只有2行,插入错误,所以需要相同的表结构才能插入。如果不用 * 就要把所有的列信息写进去。

插入的时候如果有一列,和源数据信息的列,位置搞错了,不按正常写,就会出现报错,数据错乱
所有在插入的时候需要慎重,列的数量,列的类型,以及列的顺序都写清楚。
万一出错了,对于大数据而言,没有回滚的概念,只有重跑job
重跑:幂等 ***** 非常重要的概念,重跑100次结果也是一样
所以我们要解决所有的场景都是支持幂等的,结果都需要一样
hive> INSERT INTO TABLE ruozedata_emp4
> SELECT empno,job, ename,mgr, hiredate, salary, comm, deptno from ruozedata_emp;
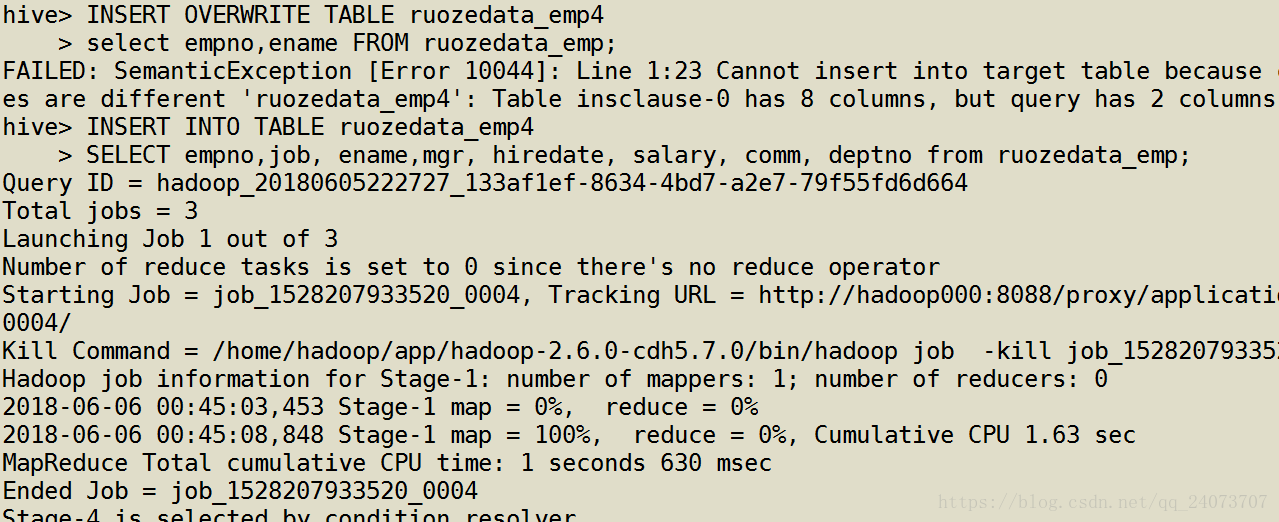
hive> select * from ruozedata_emp4;

补充:
CTAS什么意思?

大数据课程推荐:
