递归最小二乘(RLS)算法详解
本文首发在我的个人博客:宅到没朋友,欢迎大家来玩!
1.最小二乘算法简介
最小二乘算法基于确定性思想,该算法讨论怎样根据有限个观测数据来寻找滤波器的最优解,即求如下图这样具有M个抽头的横向滤波器的最优权向量。
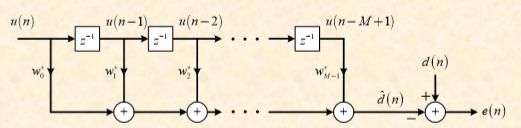
最小二乘算法的目的就是通过最小化误差向量 e ⃗ \vec{e} e的模的平方和,即最小化 J = ∥ e ⃗ ∥ 2 J = \| \vec{e} \| ^{2} J=∥e∥2,来求解得到最优权向量:
w ⃗ = [ w 0 w 1 ⋯ w M − 1 ] \vec{w}=[w_{0} \quad w_{1} \cdots w_{M-1}] w=[w0w1⋯wM−1]
由于:
e ⃗ = [ e ( M ) e ( M + 1 ) ⋯ e ( N ) ] H = b ⃗ − b ^ ⃗ = b ⃗ − A w ⃗ \vec{e}=[e(M) \quad e(M+1) \cdots e(N)]^{H}=\vec{b}-\vec{\hat{b}}=\vec{b}-A \vec{w} e=[e(M)e(M+1)⋯e(N)]H=b−b^=b−Aw
其中:
- 滤波器阶数: M M M
- 样本点数: N N N
- 误差向量: e ⃗ = [ e ( M ) e ( M + 1 ) ⋯ e ( N ) ] \vec{e}=[e(M) \quad e(M+1) \cdots e(N)] e=[e(M)e(M+1)⋯e(N)]
- 期望向量: b ⃗ = [ d ( M ) d ( M + 1 ) ⋯ d ( N ) ] \vec{b}=[d(M) \quad d(M+1) \cdots d(N)] b=[d(M)d(M+1)⋯d(N)]
- 数据矩阵: A H = [ u ⃗ ( M ) u ⃗ ( M + 1 ) ⋯ u ⃗ ( N ) ] = [ u ( M ) u ( M + 1 ) ⋯ u ( N ) u ( M − 1 ) u ( M ) ⋯ u ( N − 1 ) ⋮ ⋮ ⋱ ⋮ u ( 1 ) u ( 2 ) ⋯ u ( N − M + 1 ) ] A^{H}=[\vec{u}(M) \quad \vec{u}(M+1) \cdots \vec{u}(N)]= \begin{bmatrix} u(M) & u(M+1) & \cdots & u(N) \\ u(M-1) & u(M) & \cdots & u(N-1) \\ \vdots & \vdots & \ddots & \vdots \\ u(1) & u(2) & \cdots & u(N-M+1) \\ \end{bmatrix} AH=[u(M)u(M+1)⋯u(N)]=⎣⎢⎢⎢⎡u(M)u(M−1)⋮u(1)u(M+1)u(M)⋮u(2)⋯⋯⋱⋯u(N)u(N−1)⋮u(N−M+1)⎦⎥⎥⎥⎤
由此可以得到:
J = ∥ e ⃗ ∥ 2 = e ⃗ H e ⃗ = ( b ⃗ − A w ⃗ ) H ( b ⃗ − A w ⃗ ) J = \| \vec{e} \| ^{2}=\vec{e}^{H} \vec{e}=(\vec{b}-A \vec{w})^{H}(\vec{b}-A \vec{w}) J=∥e∥2=eHe=(b−Aw)H(b−Aw)
化简得:
J = b ⃗ H b ⃗ − b ⃗ H A w ⃗ − w ⃗ H A H b ⃗ + w ⃗ H A H A w ⃗ J = \vec{b}^{H} \vec{b}-\vec{b}^{H} A \vec{w}-\vec{w}^{H} A^{H} \vec{b}+\vec{w}^{H} A^{H} A \vec{w} J=bHb−bHAw−wHAHb+wHAHAw
要求 J J J的最小值,首先要得到 J J J关于 w ⃗ \vec{w} w的梯度:
▽ J = − 2 A H b ⃗ + 2 A H A w ⃗ \bigtriangledown J=-2A^{H}\vec{b}+2A^{H}A\vec{w} ▽J=−2AHb+2AHAw
再令 ▽ J = 0 \bigtriangledown J=0 ▽J=0得:
A H A w ^ ⃗ = A H b ⃗ ( 1 ) A^{H}A \vec{\hat{w}} =A^{H}\vec{b}\quad (1) AHAw^=AHb(1)
上式被称为确定性正则方程。
当 M < N − M + 1 M
w ^ ⃗ = ( A H A ) − 1 A H b ⃗ ( 2 ) \vec{\hat{w}}=(A^{H}A)^{-1}A^{H}\vec{b}\quad (2) w^=(AHA)−1AHb(2)
上式也被称为最小二乘 ( L S ) (LS) (LS)解。
估计向量 b ^ ⃗ = A w ⃗ \vec{\hat{b}}=A \vec{w} b^=Aw被称为对期望响应向量 b ⃗ \vec{b} b的最小二乘估计,简称 L S LS LS估计。
2.递归最小二乘 ( R L S ) (RLS) (RLS)算法
在(2)式中,涉及矩阵 A H A A^{H}A AHA的求逆运算,运算量较大,递归最小二乘 ( R L S ) (RLS) (RLS)算法就是用迭代算法代替矩阵求逆达到降低运算量的目的。
将数据矩阵 A H A^{H} AH做如下扩展:
A H = [ u ( 1 ) u ( 2 ) ⋯ u ( M ) ⋯ u ( N ) 0 u ( 1 ) ⋯ u ( M − 1 ) ⋯ u ( N − 1 ) ⋮ ⋮ ⋱ ⋮ ⋱ ⋮ 0 0 ⋯ u ( 1 ) ⋯ u ( N − M + 1 ) ] A^{H}= \begin{bmatrix} u(1) & u(2) & \cdots & u(M) & \cdots & u(N) \\ 0 & u(1) & \cdots & u(M-1) & \cdots & u(N-1) \\ \vdots & \vdots & \ddots & \vdots & \ddots & \vdots\\ 0 & 0 & \cdots & u(1) & \cdots &u(N-M+1) \\ \end{bmatrix} AH=⎣⎢⎢⎢⎡u(1)0⋮0u(2)u(1)⋮0⋯⋯⋱⋯u(M)u(M−1)⋮u(1)⋯⋯⋱⋯u(N)u(N−1)⋮u(N−M+1)⎦⎥⎥⎥⎤
将期望向量 b ⃗ \vec b b做如下扩展:
b ⃗ = [ d ( 1 ) d ( 2 ) ⋯ d ( M ) ⋯ d ( N ) ] \vec{b}=[d(1) \quad d(2) \cdots d(M) \cdots d(N)] b=[d(1)d(2)⋯d(M)⋯d(N)]
定义输入数据数据的时间相关矩阵:
Φ ( N ) = A H A = ∑ i = 1 N u ⃗ ( i ) u ⃗ H ( i ) \Phi(N)=A^{H}A=\sum_{i=1}^{N}\vec{u}(i)\vec{u}^{H}(i) Φ(N)=AHA=i=1∑Nu(i)uH(i)
定义时间互相关向量为
z ⃗ ( N ) = A H b ⃗ = ∑ i = 1 N u ⃗ ( i ) d ∗ ( i ) \vec{z}(N)=A^{H}\vec{b}=\sum_{i=1}^{N}\vec{u}(i)d^{*}(i) z(N)=AHb=i=1∑Nu(i)d∗(i)
于是,如式(1)所示的确定性正则方程变成下式:
Φ ( N ) w ^ ⃗ = z ⃗ ( N ) ( 3 ) \Phi(N)\vec{\hat{w}}=\vec{z}(N)\quad(3) Φ(N)w^=z(N)(3)
(3)式就是N时刻的确定性正则方程。
将N时刻变为任意时刻n,并引入遗忘因子 λ ( 0 < λ ≤ 1 ) \lambda(0<\lambda \leq1) λ(0<λ≤1),则 Φ \Phi Φ、 z z z和(3)式变成如下所示:
Φ ( n ) = ∑ i = 1 n λ n − i u ⃗ ( i ) u ⃗ H ( i ) + δ λ n I \Phi(n)=\sum_{i=1}^{n}\lambda^{n-i}\vec{u}(i)\vec{u}^{H}(i)+\delta \lambda ^{n}I Φ(n)=i=1∑nλn−iu(i)uH(i)+δλnI
z ( n ) = ∑ i = 1 n λ n − i u ⃗ ( i ) d ∗ ( i ) z(n)=\sum_{i=1}^{n}\lambda^{n-i}\vec{u}(i)d^{*}(i) z(n)=i=1∑nλn−iu(i)d∗(i)
Φ ( n ) w ^ ⃗ = z ⃗ ( n ) \Phi(n)\vec{\hat{w}}=\vec{z}(n) Φ(n)w^=z(n)
注: Φ ( n ) \Phi(n) Φ(n)中引入 δ λ n I \delta \lambda ^{n}I δλnI是为了使 Φ ( n ) \Phi(n) Φ(n)可逆。
令 P ( n ) = Φ − 1 ( n ) P(n)=\Phi^{-1}(n) P(n)=Φ−1(n),接下来需要的事情就是求出 w ^ ⃗ \vec{\hat{w}} w^的迭代公式,推导过程较为繁琐,在此不再展开,直接给出最后的迭代公式。
w ^ ⃗ ( n ) = w ^ ⃗ ( n − 1 ) + k ⃗ ( n ) ξ ∗ ( n ) \vec{\hat{w}}(n)=\vec{\hat{w}}(n-1)+\vec{k}(n) \xi ^{*}(n) w^(n)=w^(n−1)+k(n)ξ∗(n)
其中:
k ⃗ ( n ) = λ − 1 P ( n − 1 ) u ⃗ ( n ) 1 + λ − 1 u ⃗ H ( n ) P ( n − 1 ) u ⃗ ( n ) \vec{k}(n)=\frac{\lambda ^{-1}P(n-1)\vec{u}(n)}{1+\lambda ^{-1}\vec{u}^{H}(n)P(n-1)\vec{u}(n)} k(n)=1+λ−1uH(n)P(n−1)u(n)λ−1P(n−1)u(n)
ξ ( n ) = d ( n ) − w ^ ⃗ ( n − 1 ) u ⃗ ( n ) \xi(n)=d(n)-\vec{\hat{w}}(n-1)\vec{u}(n) ξ(n)=d(n)−w^(n−1)u(n)
P ( n ) = λ − 1 P ( n − 1 ) − λ − 1 k ⃗ ( n ) u ⃗ H ( n ) P ( n − 1 ) P(n)=\lambda ^{-1}P(n-1)-\lambda ^{-1}\vec{k}(n)\vec{u}^{H}(n)P(n-1) P(n)=λ−1P(n−1)−λ−1k(n)uH(n)P(n−1)
可以看到 w ^ ⃗ ( n ) \vec{\hat{w}}(n) w^(n)迭代式中的变量 P ( n ) 、 k ⃗ ( n ) ) 、 ξ ( n ) P(n)、\vec{k}(n))、\xi(n) P(n)、k(n))、ξ(n)都是可以迭代求解的。
2.1 ( R L S ) (RLS) (RLS)算法步骤
1. 初始化:
P ( 0 ) = δ I , δ 是 小 正 数 P(0) = \delta I \quad, \delta 是小正数 P(0)=δI,δ是小正数
w ^ ⃗ ( 0 ) = 0 ⃗ \vec{\hat{w}}(0)=\vec{0} w^(0)=0
λ 取 接 近 于 1 \lambda取接近于1 λ取接近于1
2. n = 1 , 2 , ⋯ , N n=1,2,\cdots,N n=1,2,⋯,N时,做如下迭代运算:
k ⃗ ( n ) = λ − 1 P ( n − 1 ) u ⃗ ( n ) 1 + λ − 1 u ⃗ H ( n ) P ( n − 1 ) u ⃗ ( n ) \vec{k}(n)=\frac{\lambda ^{-1}P(n-1)\vec{u}(n)}{1+\lambda ^{-1}\vec{u}^{H}(n)P(n-1)\vec{u}(n)} k(n)=1+λ−1uH(n)P(n−1)u(n)λ−1P(n−1)u(n)
ξ ( n ) = d ( n ) − w ^ ⃗ ( n − 1 ) u ⃗ ( n ) \xi(n)=d(n)-\vec{\hat{w}}(n-1)\vec{u}(n) ξ(n)=d(n)−w^(n−1)u(n)
w ^ ⃗ ( n ) = w ^ ⃗ ( n − 1 ) + k ⃗ ( n ) ξ ∗ ( n ) \vec{\hat{w}}(n)=\vec{\hat{w}}(n-1)+\vec{k}(n) \xi ^{*}(n) w^(n)=w^(n−1)+k(n)ξ∗(n)
P ( n ) = λ − 1 P ( n − 1 ) − λ − 1 k ⃗ ( n ) u ⃗ H ( n ) P ( n − 1 ) P(n)=\lambda ^{-1}P(n-1)-\lambda ^{-1}\vec{k}(n)\vec{u}^{H}(n)P(n-1) P(n)=λ−1P(n−1)−λ−1k(n)uH(n)P(n−1)
3. 令 n = n + 1 n=n+1 n=n+1,重复步骤2。
2.2 算例
考虑一阶 A R AR AR模型 u ( n ) = − 0.99 u ( n − 1 ) + v ( n ) u(n)=-0.99u(n-1)+v(n) u(n)=−0.99u(n−1)+v(n)的线性预测。假设白噪声 v ( n ) v(n) v(n)的方差为 σ v 2 = 0.995 \sigma_{v}^{2}=0.995 σv2=0.995,使用抽头数为 M = 2 M=2 M=2的 F I R FIR FIR滤波器,用 R L S RLS RLS算法实现 u ( n ) u(n) u(n)的线性预测,选择遗忘因子 λ = 0.98 \lambda = 0.98 λ=0.98。
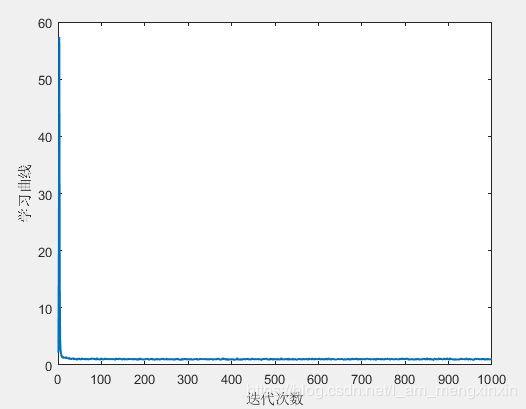
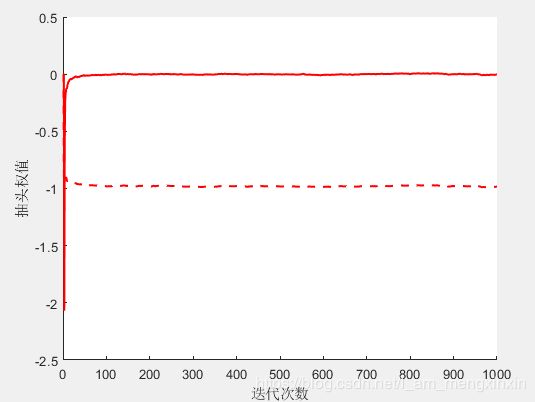
2.3 M a t l a b Matlab Matlab仿真结果
可以看到 R L S RLS RLS算法收敛的速度很快,收敛特性相当好。
2.4 M a t l a b Matlab Matlab源码下载
点此下载源码!
欢迎搜索并关注微信公众号“工科南”。