【科普】超算到底是咋算的?

最近一段时间,有关超算的话题成为热门,一时间大家都开始讨论超算,各种浮于表面的吹牛,逼格负无穷的装逼。然而,冬瓜哥发现在所有这些讨论中,从没有在任何时间任何地点发现任何人问出就连小学生都经常问的问题:超算到底是怎么算的?不得不说是一件可悲的事情。
本文组织结构:
1.并行结算基本概念
2. 众核NoC基本概念
3. 超算集群和MPI怎么玩的
4. GPU并行计算怎么玩的
5. 科学计算到底都在算些啥以及怎么并行的(压轴的放最后)
【并行计算怎么算】
我们知道,单个CPU核心只能串行计算,也就是一条一条的把机器指令读出来执行。要理解的一点是,串行执行并不表示指令顺序执行,跳转指令可以让CPU跳到其他地址执行,但是整个过程CPU只在执行一个单一的指令流,也就是一个线程,thread。某个线程完成某种任务,而线程对应的代码中的多个函数又各自分工完成对应的工序。要想同时执行多个线程的话,有两个办法,一个是增设额外的一个或者多个CPU,这样,在时间上可以做到Parallel/并行,同一时刻有多个任务同时执行;另一种办法则是让单个CPU执行一段时间线程1,然后再强行跳转到线程2执行一段时间,然后再跳回到线程1,这样就可以实现多个线程的Concurrency/并发,但是却不是并行,因为同一个时刻还是只有一个线程在执行,只不过每个线程执行的时间非常短,一般比如10ms的时间,就会跳转到其他线程执行,这样从表面看来,一段时间内,多个线程似乎是“同时”执行的。
前者的方式看上去性能更高,但是其有2个惨痛的代价,第一个是线程之间的同步,第二个是缓存一致性。如果多个线程运行在同一个核心上,那么它们只能一个接一个的执行,执行线程1时线程2不可能得到执行,如果线程1和线程2要操作同一个变量,那么就轮流操作,不会有问题。但是多个线程运行在不同的核心上,事情就发生很大变化了,比如有两个线程,都需要操作某个变量,比如同时运行a=a+1这个逻辑,期望结果是线程1对a加了1,线程2要在线程1输出结果的基础上继续+1,而由于这两个线程运行在两个独立核心上彼此之间没有协调,可能导致线程1读到的a的初始值0,加1之后还没来得及将最新结果更改到a所在的地址之前,线程2也读到了a的初始值0,加1之后也尝试写入同样的地址,最后a的结果是1,而不是期望中的2。解决办法则是对变量a加互斥锁,当某个线程操作a之前,先将锁(也是个变量)置为1,其他线程不断的扫描锁是不是已经被置为0,如果是1则表示其他人正在操作a,如果是0则表示其他人已经释放了,那么其将锁改为1,也就是锁上,自己操作a,此时读到的a就会是被其他线程更新之后的最新数据了。这个过程叫做Consistency。所以,如果多个线程之间完全独立各干各的,没有任何交互,这是最理想的场景,这就像多台无须联网的独立的计算机各干各的一样,只不过共用了CPU和内存。
然而,如果使用了缓存,又使用了共享变量,事情又变得复杂了。线程1所在的核心1抢到变量a的锁之后会将a的内容缓存到核心1的缓存中,更新了a内容之后,该更新也依然留在缓存中而不是被flush到主存。其释放锁之后,线程2抢到a的锁并将a读入核心2的缓存,此时如果不做任何处理,核心2从主存中读到的将是a的旧内容,从而计算出错。可以看到,即便是使用了锁来保证Consistency,也无法避免缓存所带来的一致性问题,后者则被称为Coherency。
Consistency由软件来负责,而Coherency则要由硬件来负责保证,具体做法是将每一笔数据更新同步广播出去给所有其他核心/CPU,将它们缓存中的旧内容作废,收到其他所有核心的回应之后,该更新才被认为成功。所以核心/CPU之间需要一个超低时延的网络用于承载这个广播。这个过程对软件完全透明。除了需要广播作废外,当其他核心需要访问该变量时,拥有该变量最新内容的核心必须做出应答将该内容推送到发出访问请求的核心。
在很早期的SMP/UMA架构下,由于那时的SMP总线本身就是一个广播域,任何核心的访存请求都会被其他所有核心收听到,包括更新了某个地址、读取某个地址,这样很天然的可以实现Coherency,比如,当某个核心更新了某个地址之后,其他核心后台默默的收听(或者说嗅探,Snoop),并在自己缓存中查询自己有没有缓存这个地址的内容,有则作废无则不动作。当某个核心发起对某个地址读的时候,其他核心收听之后也默默的搜索自己的缓存看看是否有该内容最新版本,有则使用特殊的信号抢占总线并压制主存控制器对总线的抢占,将数据返回到总线上,与此同时主存控制器也收听该内容并将该内容同步更新到该地址在主存中的副本。此时,该地址将拥有三个副本,分别位于:之前缓存它的那个核心的缓存、刚刚读它的那个核心的缓存、主存,而且内容一致。如果此时之前缓存它的那个核心再次发起读操作,就没有必要将读请求发送到总线上,而浪费电,同时也浪费其他核心的搜索运算耗费的电能以及对其他正常缓存访问的抢占。所以人们想了个办法,每个缓存条目(Cache Line,缓存行)增加一个字段,专门用来描述”该缓存当前处于什么状态“,上述状态称为Share态,而如果有人更新了某个地址,其他核心嗅探到之后,便将自己缓存里这份内容改为”Invalid“态,而刚刚更新内容的那个核心里缓存的该条目被改为”Modified“态,Invalid态的条目已经作废,再读就得走总线,M态的条目可以直接读,因为此时没有其它人有比你新的内容了。如果加电之后某个核心第一个抢到总线并发起该地址的读,则读入之后该条目就是Exclusive态,因为只有它一个人缓存了该条目,当另外核心再发起读之后,该核心嗅探到这个事件,于是将自己缓存里的该条目发送给刚才发起读的核心,那个核心从而知道其他核心也有该内容,于是两个核心一起将自己本地的该条目改为Share态,这两个核心中任何一个如果再发起该地址的读,就不用走总线了,直接缓存命中。可以看到,当某个核心需要访问的数据在其他核心的缓存中时,硬件会自动传递这份数据,软件根本无需关心。所以多个线程之间引用共享变量的时候,直接引用即可。
上述方式被称为MESI协议,其目的是为了提升效率,不需要每一笔访问都走外部总线。后来过渡到NUMA架构之后,NUMA是通过一个分布式交换网络来广播同步这些消息以及进行变量内容传送的,由于该网络并非一跳直达的广播网络,所以过滤不必要的广播就更加重要了。不同的CPU厂商有不同的方式,MESI协议也有不少变种,比如MESIF等等。另外,由于失去了天然的总线嗅探机制,如果某个缓存行处于Invalid态,读取该缓存行之前硬件需要发出Probe操作,探寻,主动广播这个Probe请求给所有核心的缓存控制器,缓存了该行的缓存控制器会返回最新数据并将自己该行的状态改为S态。如果要更新某行,该行本地处于E或者M态则直接更新,处于S态则需要发出Probe请求作废其他缓存中的该行。总之,当MESI遇到NUMA,就是个非常复杂的状态机,冬瓜哥就不继续展开了,要想与冬瓜哥深聊NUMA和Cache Coherency,可接受预约面聊,前提是你得拿出冬瓜哥看得上的干货来咱们互换一下。
【核心数能否再多点】
可以看到,增加核心数量并不是那么容易的事情,除非不使用缓存,所有核心吧所有的更新都写到主存里。但是这样做性能将会不可接受。有人问,把缓存也集中共享不就没这么多事了么?的确,但是如果把缓存单独放到某个地方,多个CPU芯片通过某种总线集中访问该缓存,那么其总线速率一定不够高,因为其走到了芯片外面,导线长度变高,信号质量就会变差。这个思路就不现实了。
所以,又得使用分布式缓存,又得要求核心数量越来越多的话,就得保证所有核心之间的网络足够高速才行,而核心数量越来越多,网络的直径就会越来越大,即便是MESI过滤,去效果也是有限的,广播的时延随着网络规模的增大变得越来越高。所以,核心数量达到一定程度之后,缓存一致性问题就变成了整个系统扩展性的瓶颈点所在。怎么办?没办。反正,硬件是不会再给你保证一致性了,因为如果成百上千个核心的网络,用硬件保证一致性得不偿失。
此时,必须抛弃由硬件保证的缓存一致性,改为软件自行解决。NoC(Network on Chip)方案就是在一个芯片中将几十个上百个核心通过高速网络连接起来但是却不提供硬件缓存一致性,其网络直径很大。这种架构天然适合各干各的,如果不是各干各的,必须传递更新后的变量的话,需要由软件自行向位于每个核心前端的NoC网络控制器发送消息+目标节点地址并传递到对方,对方通过底层驱动+协议栈接收该变量并传递给其本地程序,这已经是赤裸裸的程序控制网络通信了,其实NUMA已经是这样了,只不过其网络通信程序跑在硬件微码或者硬状态机中,且该状态机可直接接收访存请求并将其通过网络发送从而 对软件透明 。
另外,NoC架构的CPU很少会被设计为共享内存架构,因为此时主存也是通过主存控制器接入NoC,由于NoC时延过大,每一笔访存请求又是同步的,将代码直接放到主存,性能将会非常差,所以NoC上的RAM主要用于所有核心之间的最后一层共享缓存了,只不过是可寻址的缓存,由软件而不是硬件来管理。NoC架构下每个核心内部一般会有几百KB的SRAM可寻址空间,代码则运行在这里。外部主存可以使用虚拟驱动映射成某个带队列的设备,异步读写。也有支持直接映射到核心地址空间的但是访问性能会很差,所以鲜有。具体可参考冬瓜哥另外一篇文章: 《【冬瓜哥手绘】大话众核心处理器体系结构》
【再多点!】
我说,能否让核心数量再多点?冬瓜哥大学是应用化学专业,但是冬瓜哥学到最后已经完全对化学失去了兴趣,尤其是看到薛定谔老哥们之后。记得某室友的毕业设计就是用程序来算分子结构,一台破pc,奔四的,导师/师兄给了个程序说:按照步骤输入参数,点确定,贴个条“别关机,计算中!“,行了。一个月以后,来看结果。的确,不够用啊,如果一分钟能算完,这哥们就可以更安逸的玩暗黑2和看玄幻了。钱啊,学费啊,就特么干这个。当然,冬瓜哥做的更让人寒心,当时冬瓜哥是搅和化合物,分析天平称点粉末,弄点液体放烧瓶里加热搅拌,一晚上第二天结晶,拿去做x光衍射分析,写论文,当时都不知道自己在干什么,为什么干。这比那哥们更耗钱,人家只耗电,冬瓜哥这一勺子下去,就是几千块!撒地上一点就是几百块!!哎,内疚啊!
跑题了。核心数量再多,一个芯片真就搞不定了,NoC也白搭。必须用多个芯片,也不行,几万个CPU芯片怎么给它弄到一起?那就不能NoC了,得眼睛看得见的网络了,包括网卡、网线、交换机。这么大范围的网络,其速率相比NoC又降低一个档次,比如万兆以太、Infiniband等这种级别了。也就是说,这种规模之下,必须使用多台独立的机器来搭建,也就是所谓的超算集群。

哦?一堆单独的机器用网络连起来就是超级计算机?难道不应该是科幻片里那些超脑类脑神秘机器么?哈哈,没那么科幻了,兄弟。可以这么说,整个Internet上的计算机也天然组成了一个超算集群,只要Internet用户同意,就可以用来计算。比如SETI@Home项目就是利用所有Internet上的计算机各自下载一部分数据然后用同样的方式去分析然后返回结果,其将程序作为一个屏保程序,在离开或者空闲的时候,便后台启动计算,屏保结束则自动停止。当然,这个计算过程中基本不会有网络通信,多个部分之间各算个的。
使用了外部网络的话,多个不同机器上的线程之间就不能够共享内存来通信或者共同引用或处理某个变量或数据结构。如果需要通信或者共享变量,就得彻底使用这些外部网络来传递了。比如,利用TCP/IP,RDMA over IB等等。这么复杂了?老子之前写程序都是直接声明变量和数据结构,直接引用的,充其量加个锁,你现在让老子每次引用的时候要调用TCP/IP发个包给对方,再接收包,才能拿到?老子不干。。
不干不行啊,必须干,你不干就别用几万个核,回去舒舒服服用你的8路服务器,或者小型机去,那个舒服,但是就是一算一个月,爽不?酸爽。那好吧,老子接受,但是底层这么多网络,老子不懂TCP/IP怎么调用,更不懂什么RDMA,几千上万台机器,老子光记录IP地址就得记多少个。。你说咋办吧。
【 MPI是干啥的 】
鉴于上面这位老兄的顾虑,人们开发了一种叫做Message Passing Interface,简称MPI的函数库。来来来,这位客官,您要把什么东西发送给谁,敬请吩咐~~。嗯~~~?好,我这有个数组a[100],现在想把a[0]到a[9]分别发给运行在1~9号节点上的各自进程。片刻后,“上~~菜!”。我去,这么快就完成了?
上述场景成为MPI_Scatter场景,某个进程将一组数据一个一个的散播给多个进程。对应的函数为 MPI_Scatter (&sendbuf,sendcnt,sendtype,&recvbuf,recvcnt,recvtype,root,comm) , 每个进程的代码中该处加上一句,就可以了,该收的收,该发的发,该函数为同步阻塞调用,执行到这一步时发送方发出数据,接收方等待接收,搞完之后大家再继续往下走。
如果是共享内存架构,进程在代码里可以直接引用a[i],根本不需要接收/发送。比如int b=a[9]+1。该函数底层也是调用本机的网络协议栈、设备驱动从而将消息封包传递给其他机器的。
同理,还有如下这些常用函数: MPI_Send, MPI_ISend, MPI_Recv, MPI_IRecv等用于点对点数据传递的;MPI_Bcase, MPI_Gather, MPI_Reduce, MPI_Barrier等用于集合通信的等,后者统称为Collective类MPI通信。
利用MPI框架编写好对应的程序之后,需要使用mpirun脚本将程序load到集群里的每个节点上,具体如何load需要预先写好一份配置文件,大家有兴趣可以自行研究,冬瓜哥这里就不再多说了。
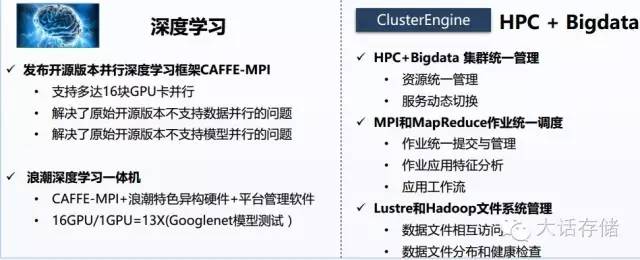
【浪潮Caffe MPI版本】
浪潮则是国内HPC领域的领军厂商,有一系列的软硬件解决方案,比如高密度刀片、GPU一体机、深度学习一体机、SmartRack整机柜服务器、InCloudRack整机柜服务器等等。

在HPC生态环境和软件方面,浪潮专门为Caffe深度学习平台开发了对应的MPI版本(开源);提供高性能计算服务平台ClusterEngine,可实现集群监控,故障报警,系统管理,作业提交管理及调度,支持提供优先级,公平共享,资源限制,资源回填等多种调度策略,支持HPC应用集成,记账管理,统计分析等功能;
以及 集群诊断调优工具Teye。天眼是一个高性能应用特征监控分析系统,面向大规模HPC集群系统,用于提取应用程序对集群资源的使用情况,并实时反映其运行特征;可在现有硬件平台基础上,深度挖掘应用程序的计算潜力;为诊断应用程序瓶颈,改进应用算法,提高并行效率提供科学有力的指引,最终达到优化系统资源利用率,提高系统计算性能的目标。并提供 热点走势图、数据分布律、特征雷达图等可视化监控。

深度学习是近年来的热点技术,冬瓜哥在这方面的知识为0。虽然不知道它是怎么做的,但是看上去真的很厉害。Caffe是伯克利发布的一款深度学习计算框架,广泛用于图像识别等深度学习领域。

浪潮发布的MPI集群版Caffe计算框架正是切中当下深度学习的迫切需求,其基于伯克利的caffe框架进行了MPI改造,让原本只支持单机+GPU环境的Caffe框架完美支持了多机MPI集群环境,并且完全保留了caffe原有的特性。
浪潮的MPI版的Caffe计算框架已经在某超级计算机上进行部署并测试,结果显示,在保证正确率相同的情况下,浪潮MPI Caffe在16个GPU上并行计算效率上提升13倍。

【GPU事半功倍】
超算又可以被称为并行计算,用大量的计算核心堆砌。高端GPU里天然就有数千个计算核心,其原本专门用于加速计算图形渲染过程,后来被人们用于通用计算领域。Nvidia GPU的典型架构如下图所示。

上图只是多个Stream Multi Processor中的一个,整个GPU含有数以千计的Core。程序编写人员需要通告GPU某个计算步骤要分成多少个线程以及如何划分。GPU内部会将32个线程为一组(也就是warp),轮流调度到SM中执行。
比如如下对一个一维数组中的各项元素求平方然后再求和的过程:
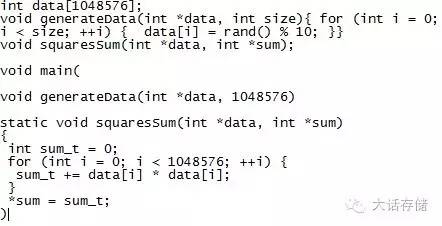
对上述过程的计算加速很简单,就是创建多个线程,装载到多个核心上同时执行,每个核心执行这一百万个元素中的一部分,形成部分和,最后再累加起来即可。如果形成一千个线程,每个线程各自求解其中一千个元素的平方和,然后再累加一千次即可,累加的过程也可以使用加法树再次加速,比如再将这一千个部分和分成20个线程来加,每个线程加50个数,这样同一时段内总共累加70次即可完成,而不是累加一千次。上述过程可以采用OpenMP库在单机共享内存场景下来完成,OpenMP库会自动将这个for循环展开为多个线程计算。如果采用NVidia GPU来加速上述过程,则需要下列步骤:
Step1. 主程序在主机内存中将数据准备好,比如:int data[1048576],表示一个含100万个元素的一维数组,然后向其中填充对应的待计算的数据。
Step2. 主程序调用NVidia提供的CUDA库函数InitCUDA()声明当前进程需要与GPU通信调用其执行计算任务,GPU侧则做好相应的上下文切换。
Step3. 主程序调用Nvidia所提供的CUDA库函数cudaMalloc( ),要求GPU在显存中开辟对应大小的空间用于存放第一步中生成的数据。
Step4. 主程序调用CUDA库函数cudaMemcpy( )让GPU从主存中对应位置将数据拷贝到第二步开辟的显存空间中。
Step5. 主程序采用 ”__global__ 函数名<<<块数,线程数>>> (参数) 的方式声明让CUDA库自动在GPU上生成多个线程来同时执行该函数,该函数被CUDA成为“核函数”或者“Kernel”,意思就是该函数中才是整个计算的核心逻辑,会被GPU并行执行,之前做的都是些准备工作而已。在函数中也可以采用手动方式明确指定由哪个线程处理哪一部分的的数据,具体采用将线程ID与变量相关联的方式实现。 <<<块数,线程数>>>是CUDA中对线程的组织方式,多个线程组成块,多个块组成Grid,用三级描述来区分各个线程。调度则以32个线程为一组。
Step6. 主程序调用cudaMemcpy( )将第五步执行完的结果从显存拷贝到主存。
Step7. 主程序调用cudafree( )释放之前分配的显存。
Step8. 主程序进行收尾工作,比如进行部分和的累加,以及显示出对应的结果,等等。
【浪潮SmartRack中的GPU节点】
浪潮SmartRack协处理加速整机柜服务器实现了在1U空间里部署4个Tesla® GPU 加速器,实现"CPU+协处理器"协同计算加速。此外,该产品还融合了广泛使用的NVIDIA® CUDA®并行计算平台以及cuDNN GPU加速库。


【科学计算到底怎么算】
最后,则是本篇压轴的知识,那就是,那些个科学计算到底都在算什么东西,又是怎么映射到多线程的?举个例子,分子动力学,模拟蛋白质折叠过程。(关于蛋白质分子相关背景知识请参考冬瓜哥的 《生物大分子是如何“计算”的》 )一文。一维肽链被核糖体读取DNA加工生成之后,在原子间相互作用力的影响之下,自然折叠卷曲成三维立体结构。科学家们想看看这个过程到底是怎么运动的,以及是不是真的可以自行折叠,还是必须依靠其他分子的辅助折叠,于是就想直接根据原子间作用力算出来。高中物理题,我们随便计算个受力分解,都会捶胸顿足“这题太难了!!”,可想而知,计算几百上千个原子之间的相互作用得有多复杂。其本质上其实就是牛顿运动力学,对F=ma的求解,一个原子会收到各个方向的各种力,静电力、化学键、范德华力等等,求出最终的合力方向,则知道该原子即将向哪移动,速度为多少。但是随着所有原子的移动,有些快有些慢,各自又朝着不同方向移动,那么每个原子的受力状况又会随之改变,这种问题的求解想想都复杂,需要使用积分的思想了。积分就是算出每一小步的结果然后积累成一大步,每一小步范围内可以近似认为所有原子的受力状况暂且没有变化。这一小步精确到多大呢?目前计算分子动力学领域一般在飞秒级,十几个飞秒,也就是将合力加在某个原子上十几个飞秒,计算每个原子的移动坐标,这十几个飞秒内可以近似认为原子的受力仍然不变。但是本质上,任何微小的变化都会持续影响受力,但是大自然底层是如何做到极限精确且连续的,或者也有某种最小精细单位,我们无从知晓,或许积分的思想也正预示着自然底层的确就是有最小移动单位的,比如:一个场。具体可以参考冬瓜哥 《时空参悟》 一文。模拟完这一小步,然后再次根据各原子的空间坐标,生成新的合力,再走一小步,最终走到某个稳定的点,引力斥力平衡,不能走为止,整个过程需要庞大的计算量。
那么上述过程如何映射到多个线程并行运算?比如,可以以原子为单位,每个线程负责计算每个原子在十几飞秒后将移动到哪个位置,该线程的输入值是该原子的元素、化合价等等,以及初始三维坐标和初速度(初始速度为0);输出值则是在牛顿力学公式的作用之下经过十几飞秒加速之后该原子的新三维坐标和速度矢量。该线程中又会有大量函数相互作用,比如:有函数会专门根据当前原子的化合价以及与其化合的其他原子都是谁,然后计算静电力,有的函数则负责计算氢键力、范德华力等。然后求合力F,算出初速度为0,合力F,质量m,t=10fs之后的该原子的位置和速度,最后这一步相信高中物理及格的朋友都可以算出来了。这一步结束之后,数千个线程之间便会发生通信操作,比如,原子A---原子B----原子C,当原子A移动位置之后,需要将其位置信息告诉原子B,因为A的移位会对B的受力造成影响;同理,原子B的最新位置也需要通告给A和C。看模拟的精度,如果认为A和C之间的相互作用力不可忽略,那么A和C之间也需要相互通告。此时可以采用MPI Send操作各自通告结果,第一轮相互同步完成之后,继续再进行下一个10fs的计算,继续循环下去,直到到达规定的时间或者触发条件,则全部线程结束运算,各自执行MPI Gather向主线程汇报最终的计算结果,主线程根据所有原子的三维坐标绘图,最终生成模拟之后的分子空间构象。
如果用GPU来完成上述计算,则需要调用CUDA计算框架来完成。先把主计算程序写好,也就是从数组中提取其中一个元素进行计算。然后向GPU分配显存,再将数组拷贝到显存,然后向GPU声明上述核心函数需要用多少个线程来计算,每个线程算哪些数组元素,算完之后将结果拷贝回主存,形成新的数组,然后再进行一轮。或者直接在GPU内部实现各个线程之间的数据同步,这需要利用到GPU内的Share Memory,细节冬瓜哥不再介绍,有兴趣自行了解。
分子动力学其实是最容易理解的超算过程,上述过程也是一种简化描述,实际上非常复杂。有些更加复杂的科学计算,比如冷冻电镜三维构象重构。其产生的背景是,分子生物界的科学家们有时候不相信用计算机模拟计算出来的分子构象,只相信肉眼所见的实际结构。于是人们想了一种办法,把含有大量某蛋白质分子的液体液氮冷却成冰块,然后切割成两半,用电子显微镜对横截面拍照,在很大几率上便会拍到位于各种角度的蛋白质大分子,有竖着的、横着的、躺着的、各种角度的。然后就将这幅高清图片输入到计算机进行处理,先将这些轮廓进行采样和描述,然后开始用这些各种角度的样子拼出一副三维空间构象。至于程序是采用什么算法将二维轮廓重构成三维构象的,其计算过程已经超出了冬瓜哥的理解范围,冬瓜哥的脑子只能理解F=ma,而这个过程则需要傅里叶变换,将平面图变成三维描述,这已经完全超越了冬瓜哥的认知,有兴趣可以自行研究,并且分享一下,不亦乐乎?
如果你耐心看到这里,证明你的收益达到了冬瓜哥的预期,那么是不是可以赏了?点击结尾赞赏按钮打赏冬瓜哥。
冬瓜哥在本文中的部分知识体系受到了浪潮公司的刘羽、王渭巍、张清三位大侠的指点和真传,在此表示衷心感谢!
相关阅读:
《 【冬瓜哥科普】生物大分子是如何“计算”的 》
《 聊聊FPGA/GPCPU/PCIE/Cache-Coherency/CAPI1.0 》
《【冬瓜哥手绘】致敬龙芯!冬瓜哥手工设计了一个CPU译码器!》
《 【冬瓜哥手绘】大话众核心处理器体系结构 》
