Andorid 硬件显示系统HWC&HWC2架构详解
硬件合成HWC2
Hardware Composer HAL (HWC) 是 SurfaceFlinger 用来将 Surface 合成到屏幕。HWC 可以抽象出叠加层和 2D 位块传送器等,其主要是帮忙GPU完成一些工作。
SurfaceFlinger是一个系统服务,其作用是接受来自多个源的Buffer数据,对它们进行合成,然后发送到显示设备进行显示。在之前的Android版本中,显示基本都是基于硬件的FrameBuffer来实现的,例如/dev/graphics/fb0,但是在后来的版本中,实现可以多样化了,比如高通采用SDM,其他有些平台采用ADF,DRM等。
SurfaceFlinger和HWC的相关配合,实现Android系统的合成与显示~
SurfaceFlinger概述
大多数应用通常在屏幕上有三个层:屏幕顶部的状态栏、底部或侧面的导航栏以及应用的界面。有些应用会拥有更多或更少的层(例如,默认主屏幕应用有一个单独的壁纸层,而全屏游戏可能会隐藏状态栏)。每个层都可以单独更新。状态栏和导航栏由系统进程渲染,而应用层由应用渲染,两者之间不进行协调。
下面我们通过一张图,来进行说明:
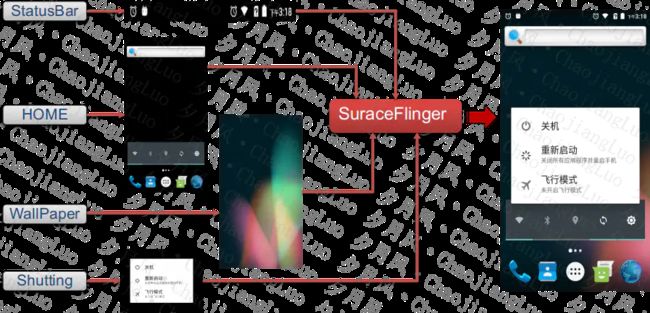
Android显示系统
从上图,我们可以看出,在长按Power键,弹出关机对话框时,有4层Layer,可以立即为有4个窗口。4个窗口经过SurfaceFlinger进行合成后,再送到显示器进行显示。
我们来看看SurfaceFlinger的类定义:
class SurfaceFlinger : public BnSurfaceComposer,
public PriorityDumper,
private IBinder::DeathRecipient,
private HWC2::ComposerCallback
{
SurfaceFlinger继承BnSurfaceComposer,实现ISurfaceComposer接口。实现ComposerCallback。PriorityDumper是一个辅助类,主要提供SurfaceFlinger的信息dump,并提供信息的分离和格式设置。
- ** ISurfaceComposer接口实现**
ISurfaceComposer是提供给上层Client端的接口,ISurfaceComposer接口包括:
* frameworks/native/libs/gui/include/gui/ISurfaceComposer.h
enum {
// Note: BOOT_FINISHED must remain this value, it is called from
// Java by ActivityManagerService.
BOOT_FINISHED = IBinder::FIRST_CALL_TRANSACTION,
CREATE_CONNECTION,
UNUSED, // formerly CREATE_GRAPHIC_BUFFER_ALLOC
CREATE_DISPLAY_EVENT_CONNECTION,
CREATE_DISPLAY,
DESTROY_DISPLAY,
GET_BUILT_IN_DISPLAY,
SET_TRANSACTION_STATE,
AUTHENTICATE_SURFACE,
GET_SUPPORTED_FRAME_TIMESTAMPS,
GET_DISPLAY_CONFIGS,
GET_ACTIVE_CONFIG,
SET_ACTIVE_CONFIG,
CONNECT_DISPLAY,
CAPTURE_SCREEN,
CAPTURE_LAYERS,
CLEAR_ANIMATION_FRAME_STATS,
GET_ANIMATION_FRAME_STATS,
SET_POWER_MODE,
GET_DISPLAY_STATS,
GET_HDR_CAPABILITIES,
GET_DISPLAY_COLOR_MODES,
GET_ACTIVE_COLOR_MODE,
SET_ACTIVE_COLOR_MODE,
ENABLE_VSYNC_INJECTIONS,
INJECT_VSYNC,
GET_LAYER_DEBUG_INFO,
CREATE_SCOPED_CONNECTION
};
ISurfaceComposer的接口在SurfaceFlinger中都有对应的方法实现。Client端通过Binder调到SurfaceFlinger中。前面我们已经说过上层怎么获取Display的信息,其实现就是SurfaceFlinger中的getDisplayConfigs函数。其他的类似,根据上面Binder的command去找对应的实现。
- ComposerCallback接口实现
ComposerCallback是HWC2的callback接口,包括以下接口:
class ComposerCallback {
public:
virtual void onHotplugReceived(int32_t sequenceId, hwc2_display_t display,
Connection connection,
bool primaryDisplay) = 0;
virtual void onRefreshReceived(int32_t sequenceId,
hwc2_display_t display) = 0;
virtual void onVsyncReceived(int32_t sequenceId, hwc2_display_t display,
int64_t timestamp) = 0;
virtual ~ComposerCallback() = default;
};
callback提供了注册接口,registerCallback,在SurfaceFlinger初始化时,注册:
void SurfaceFlinger::init() {
... ...
LOG_ALWAYS_FATAL_IF(mVrFlingerRequestsDisplay,
"Starting with vr flinger active is not currently supported.");
getBE().mHwc.reset(new HWComposer(getBE().mHwcServiceName));
getBE().mHwc->registerCallback(this, getBE().mComposerSequenceId);
registerCallback时的this就是SurfaceFlinger对ComposerCallback接口的实现。
-
onHotplugReceived
热插拔事件的回调,显示屏幕连接或断开时回调。Surfaceflinger中实现的方法为SurfaceFlinger::onHotplugReceived。这块逻辑,我们稍后介绍。 -
onRefreshReceived
接收底层HWComposer的刷新请求,实现方法如下:
void SurfaceFlinger::onRefreshReceived(int sequenceId,
hwc2_display_t /*display*/) {
Mutex::Autolock lock(mStateLock);
if (sequenceId != getBE().mComposerSequenceId) {
return;
}
repaintEverythingLocked();
}
void SurfaceFlinger::repaintEverythingLocked() {
android_atomic_or(1, &mRepaintEverything);
signalTransaction();
}
在repaintEverythingLocked中,注意这里的mRepaintEverything,repaintEverythingLocked的值为1。signalTransaction将触发一次刷新,重新进行合成显示。
重新绘制,说明底层配置,参数等有变动,SurfaceFlinger前面给的数据不能用,得重新根据变动后的配置进行进行合成,给适合当前配置的显示数据。
- onVsyncReceived
Vsync事件上报,接收底层硬件上报的垂直同步信号。
需要注意的是,这里收到的热插拔和Vsync回调,又将被封装为事件的形式再通知出去,这是回话,后续介绍。
- 显示周期Vsync
设备显示会按一定速率刷新,在手机和平板电脑上通常为每秒 60 帧。如果显示内容在刷新期间更新,则会出现撕裂现象;因此,请务必只在周期之间更新内容。在可以安全更新内容时,系统便会收到来自显示设备的信号。由于历史原因,我们将该信号称为 VSYNC 信号。
刷新率可能会随时间而变化,例如,一些移动设备的刷新率范围在 58 fps 到 62 fps 之间,具体要视当前条件而定。对于连接了 HDMI 的电视,刷新率在理论上可以下降到 24 Hz 或 48 Hz,以便与视频相匹配。由于每个刷新周期只能更新屏幕一次,因此以 200 fps 的刷新率为显示设备提交缓冲区只是在做无用功,因为大多数帧永远不会被看到。SurfaceFlinger 不会在应用提交缓冲区时执行操作,而是在显示设备准备好接收新的缓冲区时才会唤醒。
当 VSYNC 信号到达时,SurfaceFlinger 会遍历它的层列表,以寻找新的缓冲区。如果找到新的缓冲区,它会获取该缓冲区;否则,它会继续使用以前获取的缓冲区。SurfaceFlinger 总是需要可显示的内容,因此它会保留一个缓冲区。如果在某个层上没有提交缓冲区,则该层会被忽略。
- 合成方式
目前SurfaceFlinger中支持两种合成方式,一种是Device合成,一种是Client合成。SurfaceFlinger 在收集可见层的所有缓冲区之后,便会询问 Hardware Composer 应如何进行合成。
-
Client合成
Client合成方式是相对与硬件合成来说的,其合成方式是,将各个Layer的内容用GPU渲染到暂存缓冲区中,最后将暂存缓冲区传送到显示硬件。这个暂存缓冲区,我们称为FBTarget,每个Display设备有各自的FBTarget。Client合成,之前称为GLES合成,我们也可以称之为GPU合成。Client合成,采用RenderEngine进行合成。 -
Device合成
就是用专门的硬件合成器进行合成HWComposer,所以硬件合成的能力就取决于硬件的实现。其合成方式是将各个Layer的数据全部传给显示硬件,并告知它从不同的缓冲区读取屏幕不同部分的数据。HWComposer是Devicehec的抽象。
所以,整个显示系统的数据流如下图所示,此图来源于Androd 官网:
Android显示系统数据流图
GPU合成后数据,作为一个特殊的Layer,传给显示硬件。
- dump信息
dump信息是很好的一个调试手段,dump命令 如下:
adb shell dumpsys SurfaceFlinger
比如,我们通过dump,就可以知道当前有那些Layer,都用什么合成方式
Display 0 HWC layers:
-------------------------------------------------------------------------------
Layer name
Z | Comp Type | Disp Frame (LTRB) | Source Crop (LTRB)
-------------------------------------------------------------------------------
com.android.settings/com.android.settings.Settings#0
21005 | Client | 0 0 480 800 | 0.0 0.0 480.0 800.0
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
StatusBar#0
181000 | Client | 0 0 480 36 | 0.0 0.0 480.0 36.0
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
此时,有两个Layer,采用Client合成方式。
-
后端SurfaceFlingerBE
SurfaceFlingerBE是Android P上新分离出来的,没有太多信息,从目前的定义来看是将SurfaceFlinger分离为前端和后端,这里的SurfaceFlingerBE就是后端,现在的SurfaceFlinger充当前端的角色。后端SurfaceFlingerBE主要就是和底层合成打交道,前端和上层进行交互。在后续的版本中,更多的逻辑会被移到后端中。 -
消息队列和主线程
和应用进程类似,SurfaceFlinger也有一个主线程,SurfaceFlinger的主线程主要进行显示数据的处理,也就是合成。SurfaceFlinger是一个服务,将会响应上层的很多请求,各个进程的请求都在SurfaceFlinger的各个Binder线程中,如果线程很耗时,那么应用端就会被block,显示也会被block。主线程就是将他们分离开来,各干各的事。
SurfaceFlinger还有很多逻辑,我们先来看看SurfaceFlinger相关的类,接下再来我们一下进行介绍。
SurfaceFlinger相关类图
其他的都好理解,有两个地方需要注意:
1.SurfaceFlinger有两个状态,Layer也有两个状态,一个mCurrentState,一个mDrawingState。注意这里State类定义是不一样的。
2.两个EventThread,一个是给SurfaceFlinger本身用,一个是为了给应用分发事件的。
void SurfaceFlinger::init() {
... ...
sp vsyncSrc =
new DispSyncSource(&mPrimaryDispSync, SurfaceFlinger::vsyncPhaseOffsetNs, true, "app");
mEventThread = new EventThread(vsyncSrc, *this, false);
sp sfVsyncSrc =
new DispSyncSource(&mPrimaryDispSync, SurfaceFlinger::sfVsyncPhaseOffsetNs, true, "sf");
mSFEventThread = new EventThread(sfVsyncSrc, *this, true);
mEventQueue.setEventThread(mSFEventThread);
VSyncSources 是Vsync的源,并不是每一个Vsync信号都是从底层硬件上报的,平时的Vsync都是VSyncSources分发出来的,VSyncSources定期会和底层的Vsync进行同步,确保和底层屏幕新的步调一致。
HWC2 概述
Android 7.0 包含新版本的 HWC (HWC2),Android需要自行配置,到Android 8.0,HWC2正式开启,且版本升级为2.1版本。HWC2是 SurfaceFlinger 用来与专门的窗口合成硬件进行通信。SurfaceFlinger 包含使用 3D 图形处理器 (GPU) 执行窗口合成任务的备用路径,但由于以下几个原因,此路径并不理想:
- 通常,GPU 未针对此用例进行过优化,因此能耗可能要大于执行合成所需的能耗。
- 每次 SurfaceFlinger 使用 GPU 进行合成时,应用都无法使用处理器进行自我渲染,因此应尽可能使用专门的硬件而不是 GPU 进行合成。
下面是GPU和HWC两种方式的优劣对比:
| 合成类型 | 耗电情况 | 性能情况 | Alpha处理 | DRM内容处理 | 其他限制 |
|---|---|---|---|---|---|
| Device合成(HWC) | 耗电低 | 性能高 | 很多Vendor的HWC不支持Alpha的处理和合成 | 基本都能访问DRM内容 | 能合成的Surface层数有限,对每种Surface类型处理层数有限 |
| Client合成(GPU) | 耗电高 | 性能低 | 能处理每个像素的Alpha及每个Layear的Alpha | 早期版本GPU不能访问DRM的内容 | 目前的处理层数没有限制 |
所以,HWC的设计最好遵循一些基本的规则~
HWC 常规准则
由于 Hardware Composer 抽象层后的物理显示设备硬件可因设备而异,因此很难就具体功能提供建议。一般来说,请遵循以下准则:
- HWC 应至少支持 4 个叠加层(状态栏、系统栏、应用和壁纸/背景)。
- 层可以大于屏幕,因此 HWC 应能处理大于显示屏的层(例如壁纸)。
- 应同时支持预乘每像素 Alpha 混合和每平面 Alpha 混合。
- HWC 应能处理 GPU、相机和视频解码器生成的相同缓冲区,因此支持以下某些属性很有帮助:
- RGBA 打包顺序
- YUV 格式
- Tiling, swizzling和步幅属性
- 为了支持受保护的内容,必须提供受保护视频播放的硬件路径。
Tiling,翻译过来就没有原文的意味了,说白了,就是将image进行切割,切成MxN的小块,最后用的时候,再将这些小块拼接起来,就像铺瓷砖一样。
swizzling,比Tiling难理解点,它是一种拌和技术,这是向量的单元可以被任意地重排或重复,见过的hwc代码写的都比较隐蔽,没有见多处理的地方。
HWC专注于优化,智能地选择要发送到叠加硬件的 Surface,以最大限度减轻 GPU 的负载。另一种优化是检测屏幕是否正在更新;如果不是,则将合成委托给 OpenGL 而不是 HWC,以节省电量。当屏幕再次更新时,继续将合成分载到 HWC。
为常见用例做准备,如:
- 纵向和横向模式下的全屏游戏
- 带有字幕和播放控件的全屏视频
- 主屏幕(合成状态栏、系统栏、应用窗口和动态壁纸)
- 受保护的视频播放
- 多显示设备支持
HWC2 框架
从Android 8.0开始的Treble项目,对Android的架构做了重大的调整,让制造商以更低的成本更轻松、更快速地将设备更新到新版 Android 系统。这就对 HAL 层有了很大的调整,利用提供给Vendor的接口,将Vendor的实现和Android上层分离开来。
这样的架构让HWC的架构也变的复杂,HWC属于Binderized的HAL类型。Binderized类型的HAL,将上层Androd和底层HAL分别采用两个不用的进程实现,中间采用Binder进行通信,为了和前面的Binder进行区别,这里采用HwBinder。
因此,我们可以将HWC再进行划分,可以分为下面这几个部分(空间Space),如下图:
HWC2实现
- Client端
Client也就是SurfaceFlinger,不过SurfaceFlinger采用前后端的设计,以后和HWC相关的逻辑应该都会放到SurfaceFlinger后端也就是SurfaceFlingerBE中。代码位置:
frameworks/native/services/surfaceflinger
-
HWC2 Client端
这一部分属于SurfaceFlinger进程,其直接通过Binder通信,和HWC2的HAL Server交互。这部分的代码也在SurfaceFlinger进程中,但是采用Hwc2的命名空间。 -
HWC Server端
这一部分还是属于Android的系统,这里将建立一个进程,实现HWC的服务端,Server端再调底层Vendor的具体实现。并且,对于底层合成的实现不同,这里会做一些适配,适配HWC1.x,和FrameBuffer的实现。这部分包含三部分:接口,实现和服务,以动态库的形式存在:
[email protected]
[email protected]
[email protected]
代码位置:
hardware/interfaces/graphics/composer/2.1/default
- HWC Vendor的实现
这部分是HWC的具体实现,这部分的实现由硬件厂商完成。比如高通平台,代码位置一般为:
hardware/qcom/display
需要注意的是,HWC必须采用Binderized HAL模式,但是,并没有要求一定要实现HWC2的HAL版本。HWC2的实现需要配置,以Android 8.0为例:
- 添加宏定义
TARGET_USES_HWC2 - 编译打包HWC2相关的so库
- SeLinux相关的权限添加
- 配置
manifest.xml
android.hardware.graphics.composer
hwbinder
2.1
IComposer
default
基于上面的划分,我们来看看HWC2相关的类图:
HWC2相关类图
下面我们将详细来看!
HWC2 数据结构
HWC2 中提供了几个数据结构来描述合成以及可以显示设备的就交互,比如图层(Layer),显示屏(Display)。HWC2的一些常用接口定义在头文件hwcomposer2.h中:
hardware/libhardware/include/hardware
├── hwcomposer2.h
├── hwcomposer_defs.h
└── hwcomposer.h
hardware/interfaces/graphics/composer/2.1/types.hal
另外一些共用的数据定义是HAL的接口中:
hardware/interfaces/graphics/common/1.0
├── Android.bp
└── types.hal
当然,SurfaceFlinger中有很多相关的数据结构:
frameworks/native/services/surfaceflinger
图层Layer
图层(Layer)是合成的最重要单元;每个图层都有一组属性,用于定义它与其他层的交互方式。Layer在每一层中的代码的实现不一样,基本上Laye的理念都是一样的。
SurfaceFlinger中定义了Layer,相关的类如下:
frameworks/native/services/surfaceflinger
├── Layer.h
├── Layer.cpp
├── ColorLayer.h
├── ColorLayer.cpp
├── BufferLayer.h
└── BufferLayer.cpp
HWC2中定义了HWC2::Layer:
frameworks/native/services/surfaceflinger/DisplayHardware
├── HWC2.h
└── HWC2.cpp
在HAL中实现时,定义为hwc2_layer_t,这是在头文件hwcomposer2.h中定义的
typedef uint64_t hwc2_layer_t;
HIDL中定义为Layer,这个Layer其实和hwc2_layer_t是一样的:
typedef uint64_t Layer;
都是Layer,但是在具体的代码中要具体区分。
类型
Android中的 图层按照有没有Buffer分,有两种类型的Layer:BufferLayer和ColorLayer。这也是Android实现中时,代码实现时,采用的方式。
图层Layer类型
-
BufferLayer 顾名思义,就是有Buffer的Layer,需要上层应用Producer去生产。
-
ColorLayer 可以绘制一种制定的颜色,和制定的透明度Alpha。它是取代之前的Dim Layer的,可以设置任何的颜色只,而不只是黑色。
按照数据格式分,可以分为RGB Layer,YUV Layer。
-
RGB Layer
Buffer是RGB格式,比较常见的就是UI界面的数据。 -
YUV Layer
Buffer是YUV类型的,平常播放Video,Camera预览等,都是YUV类型的。
属性
Layer的属性定义它与其他层的关系,和显示屏的关系等。Layer包括的属性类别如下:
- 位置属性。
定义层在其显示设备上的显示位置。包括层边缘的位置及其相对于其他层的 Z-Order(指示该层在其他层之前还是之后)等信息。Layer中为实现这一点,定义了除了z-order外,定义了很多个区域Region:
* frameworks/native/services/surfaceflinger/Layer.h
class Layer : public virtual RefBase {
... ...
public:
... ...
// regions below are in window-manager space
Region visibleRegion;
Region coveredRegion;
Region visibleNonTransparentRegion;
Region surfaceDamageRegion;
Region中,是很多Rect的集合。简言之,一个Layer的visibleRegion可能是几个Rect的集合,其间的关系如下图:
图层Layer区域
SurfaceFlinger中定义的Region都是上层传下来的,在WindowManager空间。而在HWC中,用下面的结构描述:
typedef struct hwc_frect {
float left;
float top;
float right;
float bottom;
} hwc_frect_t;
typedef struct hwc_rect {
int left;
int top;
int right;
int bottom;
} hwc_rect_t;
typedef struct hwc_region {
size_t numRects;
hwc_rect_t const* rects;
} hwc_region_t;
另外,在SurfaceFlinger中,还定义了一个重要的结构,Transform。Transform就是变换矩阵,它是一个3x3的矩阵。相关类的关系如下:
Transform类图
每一个Layer的都有两个状态:mCurrentState和mDrawingState,mCurrentState是给SurfaceFlinger的前端准备数据,mDrawingState是给将数据给到合成;每个状态有两个Geometry的描述requested和active,requested是上层请求的,active是当前正在用的;每个Geometry中,有一个Transform矩阵,一个Transform包含一个mat33的整列。
Transform中,其实包含两部分,一部分是位置Postion,另外一部分才是真正的2D的变换矩阵。通过下面两个函数设置。
* frameworks/native/services/surfaceflinger/Transform.cpp
void Transform::set(float tx, float ty)
{
mMatrix[2][0] = tx;
mMatrix[2][1] = ty;
mMatrix[2][2] = 1.0f;
if (isZero(tx) && isZero(ty)) {
mType &= ~TRANSLATE;
} else {
mType |= TRANSLATE;
}
}
void Transform::set(float a, float b, float c, float d)
{
mat33& M(mMatrix);
M[0][0] = a; M[1][0] = b;
M[0][1] = c; M[1][1] = d;
M[0][2] = 0; M[1][2] = 0;
mType = UNKNOWN_TYPE;
}
这两个函数对应Layer中的setPosition和setMatrix函数;这是上层WindowManager设置下来的。
- 内容属性。定义显示内容如何呈现,显示的内容也就是Buffer。
Layer的显示,除了前面说道的几个区域描述,很有很多结构进一步的描述才能最终显示出来。包括诸如剪裁(用来扩展内容的一部分以填充层的边界)和转换(用来显示旋转或翻转的内容)等信息。HWCInfo结构体中 包括了一些这些信息:
* frameworks/native/services/surfaceflinger/Layer.h
struct HWCInfo {
HWCInfo()
: hwc(nullptr),
layer(nullptr),
forceClientComposition(false),
compositionType(HWC2::Composition::Invalid),
clearClientTarget(false) {}
HWComposer* hwc;
HWC2::Layer* layer;
bool forceClientComposition;
HWC2::Composition compositionType;
bool clearClientTarget;
Rect displayFrame;
FloatRect sourceCrop;
HWComposerBufferCache bufferCache;
};
怎么理解这里的sourceCrop和 displayFrame?
如果再加上可见区域visibleRegion呢?
再加上damageRegion呢?
还有Transform呢?
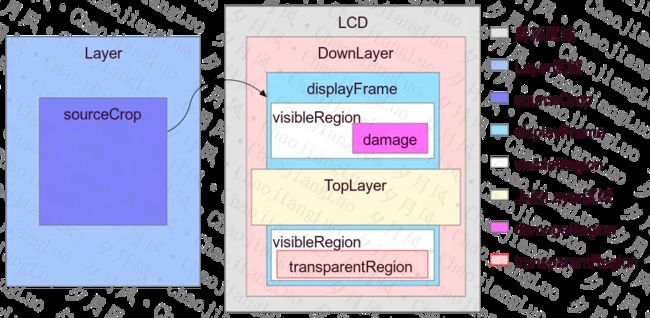
我们来个神图,让你一下子就能明白:
Android显示区域间的关系
看图说话:
-
Layer区域和屏幕区域,就是Layer和屏幕本身的大小区域
-
sourceCrop 剪切区域。
sourceCrop是对Layer进行剪切的,值截取部分Layer的内容进行显示;sourceCrop不超过Layer的大小,超过没有意义。 -
displayFrame 显示区域。
displayFrame表示Layer在屏幕上的显示区域,具体说来,是sourceCrop区域在显示屏上的显示区域。displayFrame一般来说,小于屏幕的区域。而displayFrame可能比sourceCrop大,可能小,这都是正常的,只是需要做缩放,这就是合成时需要处理的。 -
visibleRegion 可见区域。
displayFrame 区域不一定都能看到的,如果存在上层Layer,那么displayFrame区域可能部分或全部被盖住,displayFrame没有被盖住的部分就是可见区域visibleRegion。 -
damageRegion 受损区域,或者称之为更新区域。
damageRegion表示Layer内容被破坏的区域,也就是说这部分区域的内容变了,所以这个属性一般是和上一帧相比时才有意义。这算是对合成的一种优化,重新合成时,我们只去合成damageRegion区域,其他的可见区域还是用的上一帧的数据。 -
visibleNonTransparentRegion 可见非透明区域。
透明区域transparentRegion是可见区域visibleRegion的一部分,只是这一部分透明的看到的是底层Layer的内容。在SurfaceFlinger的Layer中定义visibleNonTransparentRegion,表示可见而又不透明的部分。 -
coveredRegion 被覆盖的区域。
表示Layer被TopLayer覆盖的区域,一看图就很好理解。从图中,你可以简单的认为是displayFrame和TopLayer区域重合的部分。
注意, 这里之所以说简单的认为,这是因为HWC空间的区域大小是SurfaceFlinger空间的区域经过缩放,经过Transform旋转,移动等后才得出的,要是混淆了就理解不对了。
- 合成属性。定义层应如何与其他层合成。包括混合模式和用于 Alpha 合成的全层 Alpha 值等信息。
总的说来,合成分为两个大类:GPU合成,HWC合成。根据具体的情况,分为下列几类:
* hardware/libhardware/include/hardware/hwcomposer2.h
enum class Composition : int32_t {
Invalid = HWC2_COMPOSITION_INVALID,
Client = HWC2_COMPOSITION_CLIENT,
Device = HWC2_COMPOSITION_DEVICE,
SolidColor = HWC2_COMPOSITION_SOLID_COLOR,
Cursor = HWC2_COMPOSITION_CURSOR,
Sideband = HWC2_COMPOSITION_SIDEBAND,
};
- Client 相对HWC2硬件合成的概念,主要是处理BufferLayer数据,用GPU处理。
- Device HWC2硬件设备,主要处理BufferLayer数据,用HWC处理
- SolidColor 固定颜色合成,主要处理ColorLayer数据,用HWC处理或GPU处理。
- Cursor 鼠标标识合成,主要处理鼠标等图标,用HWC处理或GPU处理
- Sideband Sideband为视频的边频带,一般需要需要硬件合成器作特殊处理,但是也可以用GPU处理。
在合成信息HWCInfo中,包含成的类型。通过Layer的setCompositionType方法进行指定:
void Layer::setCompositionType(int32_t hwcId, HWC2::Composition type, bool callIntoHwc) {
... ...
auto& hwcInfo = getBE().mHwcLayers[hwcId];
auto& hwcLayer = hwcInfo.layer;
ALOGV("setCompositionType(%" PRIx64 ", %s, %d)", hwcLayer->getId(), to_string(type).c_str(),
static_cast(callIntoHwc));
if (hwcInfo.compositionType != type) {
ALOGV(" actually setting");
hwcInfo.compositionType = type;
if (callIntoHwc) {
auto error = hwcLayer->setCompositionType(type);
... ...
}
}
}
callIntoHwc是否设置到HWC中,默认参数为true。其实确定合成类型分3步,第一步,SurfaceFlinger制定合成类型,callIntoHwc这个时候callIntoHwc为true,将类型制定给HWC。第二步,HWC根据实际情况,看看SurfaceFlinger制定的合成类型能不能执行,如果条件不满足,做出修改;第三步,SurfaceFlinger根据HWC的修改情况,再做调整,最终确认合成类型,这个时候callIntoHwc参数设置为false。
- 优化属性。提供一些非必须的参数,以供HWC进行合成的优化。包括层的可见区域以及层的哪个部分自上一帧以来已经更新等信息。也就是前面说到的visibleRegion,damageRegion等。
显示屏Display
显示屏Display是合成的另一个重要单元。系统可以具有多个显示设备,并且在正常系统操作期间可以添加或删除显示设备。该添加/删除可以应 HWC 设备的热插拔请求,或者应客户端的请求进行,这允许创建虚拟显示设备,其内容会渲染到离屏缓冲区(而不是物理显示设备)。
HWC中,SurfaceFlinger中创建的Layer,在合成开始时,将被指定到每个Display上,此后合成过程中,每个Display合成指定给自己的Layer。
参考前面我们大的类图:
SurfaceFlinger前端,每个显示屏,用DisplayDevice类描述,在后端显示数据用DisplayData描述。而在HWC2的Client端,定义了Display类进行描述。对于HWC2服务端则用hwc2_display_t描述,hwc2_display_t只是一个序号,Vendor具体实现时,才具体的去管理Display的信息。
HWC2 提供相应函数来确定给定显示屏的属性,在不同配置(例如 4k 或 1080p 分辨率)和颜色模式(例如native颜色或真彩 sRGB)之间切换,以及打开、关闭显示设备或将其切换到低功率模式(如果支持)。
HWC设备 composerDevice
一定要注意显示屏,和合成设备的差别。HWC设备就一个,在头文件中定义如下:
typedef struct hwc2_device {
struct hw_device_t common;
void (*getCapabilities)(struct hwc2_device* device, uint32_t* outCount,
int32_t* /*hwc2_capability_t*/ outCapabilities);
hwc2_function_pointer_t (*getFunction)(struct hwc2_device* device,
int32_t /*hwc2_function_descriptor_t*/ descriptor);
} hwc2_device_t;
在HWC 的Client端,采用Device描述,底层采用hwc2_device_t描述。整个合成服务都是围绕hwc2_device_t展开的。
除了层和显示设备之外,HWC2 还提供对硬件垂直同步 (VSYNC) 信号的控制,以及对于客户端的回调,用于通知它何时发生 vsync 事件。
接口指针
HWC2 头文件中,HWC 接口函数由 lowerCamelCase 命名惯例 定义,但是这些函数名称的字段并不实际存在于接口中。相反,几乎每个函数都是通过使用 hwc2_device_t 提供的 getFunction 请求函数指针来进行加载。例如,函数 createLayer 是一个 HWC2_PFN_CREATE_LAYER 类型的函数指针,当枚举值 HWC2_FUNCTION_CREATE_LAYER 传递到 getFunction 中时便会返回该指针。
接口指针定义在hwcomposer2.h中,基本上都是以HWC2_PFN*开始命名,接口比较多,这里就不贴代码了。而每个接口,都对应一个接口描述hwc2_function_descriptor_t。hwc2_function_descriptor_t定义如下,就是一个枚举列表。
/* Function descriptors for use with getFunction */
typedef enum {
HWC2_FUNCTION_INVALID = 0,
HWC2_FUNCTION_ACCEPT_DISPLAY_CHANGES,
HWC2_FUNCTION_CREATE_LAYER,
HWC2_FUNCTION_CREATE_VIRTUAL_DISPLAY,
HWC2_FUNCTION_DESTROY_LAYER,
HWC2_FUNCTION_DESTROY_VIRTUAL_DISPLAY,
HWC2_FUNCTION_DUMP,
HWC2_FUNCTION_GET_ACTIVE_CONFIG,
HWC2_FUNCTION_GET_CHANGED_COMPOSITION_TYPES,
HWC2_FUNCTION_GET_CLIENT_TARGET_SUPPORT,
HWC2_FUNCTION_GET_COLOR_MODES,
HWC2_FUNCTION_GET_DISPLAY_ATTRIBUTE,
HWC2_FUNCTION_GET_DISPLAY_CONFIGS,
HWC2_FUNCTION_GET_DISPLAY_NAME,
HWC2_FUNCTION_GET_DISPLAY_REQUESTS,
HWC2_FUNCTION_GET_DISPLAY_TYPE,
HWC2_FUNCTION_GET_DOZE_SUPPORT,
HWC2_FUNCTION_GET_HDR_CAPABILITIES,
HWC2_FUNCTION_GET_MAX_VIRTUAL_DISPLAY_COUNT,
HWC2_FUNCTION_GET_RELEASE_FENCES,
HWC2_FUNCTION_PRESENT_DISPLAY,
HWC2_FUNCTION_REGISTER_CALLBACK,
HWC2_FUNCTION_SET_ACTIVE_CONFIG,
HWC2_FUNCTION_SET_CLIENT_TARGET,
HWC2_FUNCTION_SET_COLOR_MODE,
HWC2_FUNCTION_SET_COLOR_TRANSFORM,
HWC2_FUNCTION_SET_CURSOR_POSITION,
HWC2_FUNCTION_SET_LAYER_BLEND_MODE,
HWC2_FUNCTION_SET_LAYER_BUFFER,
HWC2_FUNCTION_SET_LAYER_COLOR,
HWC2_FUNCTION_SET_LAYER_COMPOSITION_TYPE,
HWC2_FUNCTION_SET_LAYER_DATASPACE,
HWC2_FUNCTION_SET_LAYER_DISPLAY_FRAME,
HWC2_FUNCTION_SET_LAYER_PLANE_ALPHA,
HWC2_FUNCTION_SET_LAYER_SIDEBAND_STREAM,
HWC2_FUNCTION_SET_LAYER_SOURCE_CROP,
HWC2_FUNCTION_SET_LAYER_SURFACE_DAMAGE,
HWC2_FUNCTION_SET_LAYER_TRANSFORM,
HWC2_FUNCTION_SET_LAYER_VISIBLE_REGION,
HWC2_FUNCTION_SET_LAYER_Z_ORDER,
HWC2_FUNCTION_SET_OUTPUT_BUFFER,
HWC2_FUNCTION_SET_POWER_MODE,
HWC2_FUNCTION_SET_VSYNC_ENABLED,
HWC2_FUNCTION_VALIDATE_DISPLAY,
} hwc2_function_descriptor_t;
所以,Vendor的HWC2实现,基本都是这样,伪代码:
class VendorComposer2 : public hwc2_device_t {
... ...
static void GetCapabilities(struct hwc2_device *device, uint32_t *outCount, int32_t *outCapabilities);
static hwc2_function_pointer_t GetFunction(struct hwc2_device *device, int32_t descriptor);
// 具体的接口实现
static int32_t VendorAcceptDisplayChanges(hwc2_device_t *device, hwc2_display_t display);
static int32_t VendorCreateLayer(hwc2_device_t *device, hwc2_display_t display,
hwc2_layer_t *out_layer_id);
static int32_t VendorCreateVirtualDisplay(hwc2_device_t *device, uint32_t width, uint32_t height,
int32_t *format, hwc2_display_t *out_display_id);
... ...
}
// GetFunction中
hwc2_function_pointer_t HWCSession::GetFunction(struct hwc2_device *device,
int32_t int_descriptor) {
auto descriptor = static_cast(int_descriptor);
switch (descriptor) {
case HWC2::FunctionDescriptor::AcceptDisplayChanges:
return AsFP(VendorAcceptDisplayChanges);
case HWC2::FunctionDescriptor::CreateLayer:
return AsFP(VendorCreateLayer);
case HWC2::FunctionDescriptor::CreateVirtualDisplay:
return AsFP(Vendor:CreateVirtualDisplay);
... ...
句柄Handle
这个前面穿插将过了。Layer,Display和配置信息Config在HWC都是用各自的Handle表示的。
typedef uint32_t hwc2_config_t;
typedef uint64_t hwc2_display_t;
typedef uint64_t hwc2_layer_t;
Buffer也是用handle来描述native_handle_t。
当 SurfaceFlinger 想要创建新层时,它会调用 createLayer 函数,然后返回一个 hwc2_layer_t 类型的句柄,。在此之后,SurfaceFlinger 每次想要修改该层的属性时,都会将该 hwc2_layer_t 值以及进行修改所需的任何其他信息传递给相应的修改函数。hwc2_layer_t 类型句柄的大小足以容纳一个指针或一个索引,并且 SurfaceFlinger 会将其视为不透明,从而为 HWC 实现人员提供最大的灵活性。
HWC合成服务
代码位置:
hardware/interfaces/graphics/composer/2.1/default
这个HWC的的默认服务。SurfaceFlinger初始化时,可以通过属性debug.sf.hwc_service_name来制定,默认为default:
* frameworks/native/services/surfaceflinger/SurfaceFlinger.cpp
std::string getHwcServiceName() {
char value[PROPERTY_VALUE_MAX] = {};
property_get("debug.sf.hwc_service_name", value, "default");
ALOGI("Using HWComposer service: '%s'", value);
return std::string(value);
}
在编译时,manifest.xml中配置的也是default。
HWC服务分两部分:
- 可以执行程序 [email protected]
其main函数如下,通过defaultPassthroughServiceImplementation函数注册IComposer服务。
hardware/interfaces/graphics/composer/2.1/default/service.cpp
int main() {
// the conventional HAL might start binder services
android::ProcessState::initWithDriver("/dev/vndbinder");
android::ProcessState::self()->setThreadPoolMaxThreadCount(4);
android::ProcessState::self()->startThreadPool();
// same as SF main thread
struct sched_param param = {0};
param.sched_priority = 2;
if (sched_setscheduler(0, SCHED_FIFO | SCHED_RESET_ON_FORK,
¶m) != 0) {
ALOGE("Couldn't set SCHED_FIFO: %d", errno);
}
return defaultPassthroughServiceImplementation(4);
}
对应的rc文件如下:
service vendor.hwcomposer-2-1 /vendor/bin/hw/[email protected]
class hal animation
user system
group graphics drmrpc
capabilities SYS_NICE
onrestart restart surfaceflinge
- 实现库 [email protected]
hwc的执行程序中,注册的IComposer,将调到对应的FETCH函数,FETCH函数实现及是so库中。FETCH如下:
IComposer* HIDL_FETCH_IComposer(const char*)
{
const hw_module_t* module = nullptr;
int err = hw_get_module(HWC_HARDWARE_MODULE_ID, &module);
if (err) {
ALOGI("falling back to FB HAL");
err = hw_get_module(GRALLOC_HARDWARE_MODULE_ID, &module);
}
if (err) {
ALOGE("failed to get hwcomposer or fb module");
return nullptr;
}
return new HwcHal(module);
}
FETCH函数中,才正在去加载Vendor的实现,通过统一的接口hw_get_module根据IDHWC_HARDWARE_MODULE_ID去加载。加载完成后,创建HAL描述类似HwcHal。
HwcHal::HwcHal(const hw_module_t* module)
: mDevice(nullptr), mDispatch(), mMustValidateDisplay(true), mAdapter() {
uint32_t majorVersion;
if (module->id && strcmp(module->id, GRALLOC_HARDWARE_MODULE_ID) == 0) {
majorVersion = initWithFb(module);
} else {
majorVersion = initWithHwc(module);
}
initCapabilities();
if (majorVersion >= 2 && hasCapability(HWC2_CAPABILITY_PRESENT_FENCE_IS_NOT_RELIABLE)) {
ALOGE("Present fence must be reliable from HWC2 on.");
abort();
}
initDispatch();
}
如果是FrameBuffer驱动,通过initWithFb初始化。如果是HWC驱动,通过initWithHwc初始化。我们需要的是HWC2的接口,如果不是HWC2的HAl实现,那么需要做适配。
FrameBuffer驱动,采用HWC2OnFbAdapter进行适配:
uint32_t HwcHal::initWithFb(const hw_module_t* module)
{
framebuffer_device_t* fb_device;
int error = framebuffer_open(module, &fb_device);
if (error != 0) {
ALOGE("Failed to open FB device (%s), aborting", strerror(-error));
abort();
}
mFbAdapter = std::make_unique(fb_device);
mDevice = mFbAdapter.get();
return 0;
}
HWC1.x通过HWC2On1Adapter进行适配:
uint32_t HwcHal::initWithHwc(const hw_module_t* module)
{
// Determine what kind of module is available (HWC2 vs HWC1.X).
hw_device_t* device = nullptr;
int error = module->methods->open(module, HWC_HARDWARE_COMPOSER, &device);
... ...
uint32_t majorVersion = (device->version >> 24) & 0xF;
// If we don't have a HWC2, we need to wrap whatever we have in an adapter.
if (majorVersion != 2) {
uint32_t minorVersion = device->version & HARDWARE_API_VERSION_2_MAJ_MIN_MASK;
minorVersion = (minorVersion >> 16) & 0xF;
ALOGI("Found HWC implementation v%d.%d", majorVersion, minorVersion);
if (minorVersion < 1) {
ALOGE("Cannot adapt to HWC version %d.%d. Minimum supported is 1.1",
majorVersion, minorVersion);
abort();
}
mAdapter = std::make_unique(
reinterpret_cast(device));
// Place the adapter in front of the device module.
mDevice = mAdapter.get();
} else {
mDevice = reinterpret_cast(device);
}
return majorVersion;
}
这两种适配的实现代码如下:
frameworks/native/libs
├── hwc2onfbadapter
└── hwc2on1adapter
分别打包成两个动态so库,Adapter中再调具体的Vendor实现。
初始化时,第一步先获取Vendor实现的处理能力:
void HwcHal::initCapabilities()
{
uint32_t count = 0;
mDevice->getCapabilities(mDevice, &count, nullptr);
std::vector caps(count);
mDevice->getCapabilities(mDevice, &count, caps.data());
caps.resize(count);
mCapabilities.reserve(count);
for (auto cap : caps) {
mCapabilities.insert(static_cast(cap));
}
}
第二步,初始化,HWC的接口函数:
void HwcHal::initDispatch()
{
initDispatch(HWC2_FUNCTION_ACCEPT_DISPLAY_CHANGES,
&mDispatch.acceptDisplayChanges);
initDispatch(HWC2_FUNCTION_CREATE_LAYER, &mDispatch.createLayer);
initDispatch(HWC2_FUNCTION_CREATE_VIRTUAL_DISPLAY,
&mDispatch.createVirtualDisplay);
... ...
根据ID,同过Vendor实现的getFunction函数,去获取Vendor对应的函数地址。
template
void HwcHal::initDispatch(hwc2_function_descriptor_t desc, T* outPfn)
{
auto pfn = mDevice->getFunction(mDevice, desc);
if (!pfn) {
LOG_ALWAYS_FATAL("failed to get hwcomposer2 function %d", desc);
}
*outPfn = reinterpret_cast(pfn);
}
Client和Server的通信
SurfaceFlinger和HWC服务之间,很多函数,并没有直接的调用,而是通过Buffer的读写来实现调用和参数的传递的。所以,Client端和Server端通信,基本通过以下相关的途径:
- 通过IComposerClient.hal接口
- 通过IComposer.hal接口
- 通过command Buffer
Server端回调Client端,通过IComposerCallback.hal接口。
hal接口的方式,比较好理解,其本质就是Binder。那么问题来了,既然有hal的接口,为什么又加了一个command Buffer的方式呢?其实这是为了解决Binder通信慢的问题。
我们先来看看IComposerClient.hal接口
IComposerClient.hal 接口
IComposerClient.hal的接口如下:
* hardware/interfaces/graphics/composer/2.1/IComposerClient.hal
registerCallback(IComposerCallback callback);
getMaxVirtualDisplayCount() generates (uint32_t count);
createVirtualDisplay(uint32_t width,
uint32_t height,
PixelFormat formatHint,
uint32_t outputBufferSlotCount)
generates (Error error,
Display display,
PixelFormat format);
destroyVirtualDisplay(Display display) generates (Error error);
createLayer(Display display,
uint32_t bufferSlotCount)
generates (Error error,
Layer layer);
destroyLayer(Display display, Layer layer) generates (Error error);
getActiveConfig(Display display) generates (Error error, Config config);
getClientTargetSupport(Display display,
uint32_t width,
uint32_t height,
PixelFormat format,
Dataspace dataspace)
generates (Error error);
getColorModes(Display display)
generates (Error error,
vec modes);
getDisplayAttribute(Display display,
Config config,
Attribute attribute)
generates (Error error,
int32_t value);
getDisplayConfigs(Display display)
generates (Error error,
vec configs);
getDisplayName(Display display) generates (Error error, string name);
getDisplayType(Display display) generates (Error error, DisplayType type);
getDozeSupport(Display display) generates (Error error, bool support);
getHdrCapabilities(Display display)
generates (Error error,
vec types,
float maxLuminance,
float maxAverageLuminance,
float minLuminance);
setClientTargetSlotCount(Display display,
uint32_t clientTargetSlotCount)
generates (Error error);
setActiveConfig(Display display, Config config) generates (Error error);
setColorMode(Display display, ColorMode mode) generates (Error error);
setPowerMode(Display display, PowerMode mode) generates (Error error);
setVsyncEnabled(Display display, Vsync enabled) generates (Error error);
setInputCommandQueue(fmq_sync descriptor)
generates (Error error);
getOutputCommandQueue()
generates (Error error,
fmq_sync descriptor);
executeCommands(uint32_t inLength,
vec inHandles)
generates (Error error,
bool outQueueChanged,
uint32_t outLength,
vec outHandles);
IComposerClient.hal的接口函数比较多,这里提供的接口,都是一些实时的接口,也就是Client需要Server立即响应的接口。
IComposer.hal接口
IComposer.hal就3个接口函数,createClient主要的是这里的createClient函数,创建一个ComposerClient,通过ComposerClient,就可以用上面的IComposerClient.hal接口。
* hardware/interfaces/graphics/composer/2.1/IComposer.hal
getCapabilities() generates (vec capabilities);
dumpDebugInfo() generates (string debugInfo);
createClient() generates (Error error, IComposerClient client);
IComposer.hal接口也是实时接口。
IComposerCallback.hal接口
IComposerCallback.hal接口是Server回调给Client端的,主要是下面3个接口:
onHotplug(Display display, Connection connected);
oneway onRefresh(Display display);
oneway onVsync(Display display, int64_t timestamp);
三个接口分别上报热插拔,刷新请求,和Vsync事件。另外,IComposerCallback接口需要通过IComposerClient.hal的registerCallback函数进行注册。
command Buffer
相比前面的hal接口,这里的Buffer方式的调用都不是实时的,先将命令写到Buffer中,最后再一次性的调用到Server。
相关的定义在头文件IComposerCommandBuffer.h中,定义了一个CommandWriterBase和一个CommandReaderBase
* hardware/interfaces/graphics/composer/2.1/default/IComposerCommandBuffer.h
class CommandWriterBase {
... ...
uint32_t mDataMaxSize;
std::unique_ptr mData;
uint32_t mDataWritten;
// end offset of the current command
uint32_t mCommandEnd;
std::vector mDataHandles;
std::vector mTemporaryHandles;
std::unique_ptr mQueue;
};
class CommandReaderBase {
... ...
std::unique_ptr mQueue;
uint32_t mDataMaxSize;
std::unique_ptr mData;
uint32_t mDataSize;
uint32_t mDataRead;
// begin/end offsets of the current command
uint32_t mCommandBegin;
uint32_t mCommandEnd;
hidl_vec mDataHandles;
};
都是用一个uint32_t的数组来保存数据mData。Client端和Server端基于两个Base类,又继承Base,重写各自的Reader和Writer。
相关的类图如下:

命令读写器
相关的command命令,定义在IComposerClient.hal中
* hardware/interfaces/graphics/composer/2.1/IComposerClient.hal
enum Command : int32_t {
LENGTH_MASK = 0xffff,
OPCODE_SHIFT = 16,
OPCODE_MASK = 0xffff << OPCODE_SHIFT,
/** special commands */
SELECT_DISPLAY = 0x000 << OPCODE_SHIFT,
SELECT_LAYER = 0x001 << OPCODE_SHIFT,
... ...
我们以setZOrder函数为例,对应的command为SET_LAYER_Z_ORDER。
SET_LAYER_Z_ORDER = 0x40a << OPCODE_SHIFT,
对应的函数为:
Error Composer::setLayerZOrder(Display display, Layer layer, uint32_t z)
{
mWriter.selectDisplay(display);
mWriter.selectLayer(layer);
mWriter.setLayerZOrder(z);
return Error::NONE;
}
setZOrder时:
1.首先指定Display
* hardware/interfaces/graphics/composer/2.1/default/IComposerCommandBuffer.h
static constexpr uint16_t kSelectDisplayLength = 2;
void selectDisplay(Display display)
{
beginCommand(IComposerClient::Command::SELECT_DISPLAY,
kSelectDisplayLength);
write64(display);
endCommand();
}
指定Display也是通过一个命令来完成,传递一个命令具体分为3步:
- beginCommand
beginCommand先写命令值,SELECT_DISPLAY
void beginCommand(IComposerClient::Command command, uint16_t length)
{
if (mCommandEnd) {
LOG_FATAL("endCommand was not called before command 0x%x",
command);
}
growData(1 + length);
write(static_cast(command) | length);
mCommandEnd = mDataWritten + length;
}
beginCommand时,先增加Buffer的大小,Buffer采用一个uint32_t类型的数组。
std::unique_ptr mData;
再将command和长度或后,写入Buffer。最后记录,Buffer应该结束的位置mCommandEnd。这里的+1是为了写command命令,是command命令的长度。
- 写具体的值
display是64bit的,所以直接用write64的接口;将被拆分为两个32位,用32位的接口write写入Buffer。写入后,mDataWritten相应的增加。
void write(uint32_t val)
{
mData[mDataWritten++] = val;
}
- endCommand
函数如下:
void endCommand()
{
if (!mCommandEnd) {
LOG_FATAL("beginCommand was not called");
} else if (mDataWritten > mCommandEnd) {
LOG_FATAL("too much data written");
mDataWritten = mCommandEnd;
} else if (mDataWritten < mCommandEnd) {
LOG_FATAL("too little data written");
while (mDataWritten < mCommandEnd) {
write(0);
}
}
mCommandEnd = 0;
}
endCommand中主要是看我们写的数据对不对,如果写的太多,超过mCommandEnd的截掉。如果写的太少,补0。
2.指定Layer
通过selectLayer函数指定layer;selectLayer函数和前面的selectDisplay类似:
static constexpr uint16_t kSelectLayerLength = 2;
void selectLayer(Layer layer)
{
beginCommand(IComposerClient::Command::SELECT_LAYER,
kSelectLayerLength);
write64(layer);
endCommand();
}
3.将要设置的数据写如Buffer
static constexpr uint16_t kSetLayerZOrderLength = 1;
void setLayerZOrder(uint32_t z)
{
beginCommand(IComposerClient::Command::SET_LAYER_Z_ORDER,
kSetLayerZOrderLength);
write(z);
endCommand();
}
设置 z-order 时,用的SET_LAYER_Z_ORDER命令。z-order是32bit的类型,这里直接用的write函数。
到此,z-order写到Buffer mData中。注意,只是写到了mData中,还没有传到HWC的服务端呢。
4.执行命令
Buffer中的数据什么时候才传到HWC的服务端呢? 答案是 executeCommands的时候。execute 基本就是validate和present处理的时候会先调,execute将Buffer命令真正是传到Server进行解析,调相应的接口。execute主要是通过IComposerClient.hal的实时接口来完成。
execute函数如下:
Error Composer::execute()
{
// 准备command队列
bool queueChanged = false;
uint32_t commandLength = 0;
hidl_vec commandHandles;
if (!mWriter.writeQueue(&queueChanged, &commandLength, &commandHandles)) {
mWriter.reset();
return Error::NO_RESOURCES;
}
// set up new input command queue if necessary
if (queueChanged) {
auto ret = mClient->setInputCommandQueue(*mWriter.getMQDescriptor());
auto error = unwrapRet(ret);
if (error != Error::NONE) {
mWriter.reset();
return error;
}
}
if (commandLength == 0) {
mWriter.reset();
return Error::NONE;
}
Error error = kDefaultError;
auto ret = mClient->executeCommands(commandLength, commandHandles,
[&](const auto& tmpError, const auto& tmpOutChanged,
const auto& tmpOutLength, const auto& tmpOutHandles)
{
... ...
if (error == Error::NONE && tmpOutChanged) {
error = kDefaultError;
mClient->getOutputCommandQueue(
[&](const auto& tmpError,
const auto& tmpDescriptor)
{
... ...
mReader.setMQDescriptor(tmpDescriptor);
});
}
... ...
if (mReader.readQueue(tmpOutLength, tmpOutHandles)) {
... ...
});
... ...
mWriter.reset();
return error;
}
execute主要做了下面几件事:
- 准备命令队列commandQueue
通过Writer的writeQueue来实现,其作用就是将前面我们已经写到Buffer中的command及数据,写到命令队列mQueue中。代码如下:
bool writeQueue(bool* outQueueChanged, uint32_t* outCommandLength,
hidl_vec* outCommandHandles)
{
... ...
} else {
auto newQueue = std::make_unique(mDataMaxSize);
if (!newQueue->isValid() ||
!newQueue->write(mData.get(), mDataWritten)) {
ALOGE("failed to prepare a new message queue ");
return false;
}
mQueue = std::move(newQueue);
*outQueueChanged = true;
}
*outCommandLength = mDataWritten;
outCommandHandles->setToExternal(
const_cast(mDataHandles.data()),
mDataHandles.size());
return true;
}
- 设置新的命令队列
setInputCommandQueue传递的是命令队列的文件描述符,Server端Reader根据队列的文件描述符去找对应的队列。
Return ComposerClient::setInputCommandQueue(
const MQDescriptorSync& descriptor)
{
std::lock_guard lock(mCommandMutex);
return mReader->setMQDescriptor(descriptor) ?
Error::NONE : Error::NO_RESOURCES;
}
setMQDescriptor时Reader会根据描述符创建对应的命令队形。
- 执行命令队列
executeCommands在server端的实现为:
Return ComposerClient::executeCommands(uint32_t inLength,
const hidl_vec& inHandles,
executeCommands_cb hidl_cb)
{
std::lock_guard lock(mCommandMutex);
bool outChanged = false;
uint32_t outLength = 0;
hidl_vec outHandles;
if (!mReader->readQueue(inLength, inHandles)) {
hidl_cb(Error::BAD_PARAMETER, outChanged, outLength, outHandles);
return Void();
}
Error err = mReader->parse();
if (err == Error::NONE &&
!mWriter.writeQueue(&outChanged, &outLength, &outHandles)) {
err = Error::NO_RESOURCES;
}
hidl_cb(err, outChanged, outLength, outHandles);
mReader->reset();
mWriter.reset();
return Void();
}
server端的Reader读取命令队列,将命令,数据等从mQueue中又读到Reader的Buffer mData中。读到Mdata中后,再解析parse。
Error ComposerClient::CommandReader::parse()
{
IComposerClient::Command command;
uint16_t length = 0;
while (!isEmpty()) {
if (!beginCommand(&command, &length)) {
break;
}
bool parsed = parseCommand(command, length);
endCommand();
if (!parsed) {
ALOGE("failed to parse command 0x%x, length %" PRIu16,
command, length);
break;
}
}
return (isEmpty()) ? Error::NONE : Error::BAD_PARAMETER;
}
解析命令,也分3步:
beginCommand 读取命令,看看是什么命令;
parseCommand 解析命令,根据命令,解析具体的数据。比如我们设置z-order的命令处理如下:
bool ComposerClient::CommandReader::parseSetLayerZOrder(uint16_t length)
{
if (length != CommandWriterBase::kSetLayerZOrderLength) {
return false;
}
auto err = mHal.setLayerZOrder(mDisplay, mLayer, read());
if (err != Error::NONE) {
mWriter.setError(getCommandLoc(), err);
}
return true;
}
parseCommand时数据才真正传递到Server中,生效。z-order通过mHal的setLayerZOrder设置到Vendor的HAL实现中。
endCommand 表示数据读取完,记录读取的位置。
回到啊Client端execute函数。Client端的Reader也会读取返回值,
HWC2 中Fence的更改
HWC 2.0 中同步栅栏的含义相对于以前版本的 HAL 已有很大的改变。
在 HWC v1.x 中,释放Fence和退出Fence是推测性的。在帧 N 中检索到的Buffer的释放Fence或显示设备的退出Fence不会先于在帧 N + 1 中检索到的Fence变为触发状态。换句话说,该Fence的含义是“不再需要您为帧 N 提供的Buffer内容”。这是推测性的,因为在理论上,SurfaceFlinger 在帧 N 之后的一段不确定的时间内可能无法再次运行,这将使得这些栅栏在该时间段内不会变为触发状态。
在 HWC 2.0 中,释放Fence和退出Fence是非推测性的。在帧 N 中检索到的释放Fence或退出Fence,将在相关Buffer的内容替换帧 N - 1 中缓冲区的内容后立即变为触发状态,或者换句话说,该Fence的含义是“您为帧 N 提供的缓冲区内容现在已经替代以前的内容”。这是非推测性的,因为在硬件呈现此帧的内容之后,该栅栏应该在 presentDisplay 被调用后立即变为触发状态。
小结
这里主要是总结性的介绍一下HWC2,很多流程,稍后我们在代码中具体来分析。
作者:夕月风
链接:https://www.jianshu.com/p/824a9ddf68b9
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。