cv算法常见问题总结
梯度爆炸:在深层网络或循环神经网络中,误差梯度会在更新中累积,变成非常大的梯度,然后导致网络权重的大幅更新,并因此使网络变得不稳定。在极端情况下,权重的值变得非常大,以至于溢出,导致 NaN 值,梯度爆炸会引起网络不稳定,最好的结果是无法从训练数据中学习,而最坏的结果是出现无法再更新的 NaN 权重值
如何确定是否梯度爆炸:训练过程中出现梯度爆炸会伴随一些细微的信号,如: 模型不稳定,导致更新过程中的损失出现显著变化。 训练过程中,模型损失变成 NaN, 训练过程中,每个节点和层的误差梯度值持续超过 1.0。
防止过拟合:解析:
1. 加L1/L2正则化
3. BatchNormalization
5. 提取终止训练
6. 数据增强L1、L2、smooth L1三类损失函数:
https://blog.csdn.net/weixin_41940752/article/details/93159710?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase
字节:
问:L1损失函数和L2损失函数有什么区别?
参考这个 讲的很好https://www.cnblogs.com/wangguchangqing/p/12021638.html
答:L1是稀疏的,因为L1和L2的图像是这样这样这样的(画了图)
L2因为要平方,数值很大,所有一开始训练会容易不稳定。但是训练到后期,L1斜率一直是1,会有些没必要的计算
问:给定一个n×m的矩阵,将其中所有值为0的元素所在的行和列元素都置为0。
improt numpy as np
def function(grid):
grid = np.array(grid)
i, j = np.where(grid == 0)
for k in i:
grid[i][:] = 0
for k in j:
grid[:][j] = 0
问:稀疏向量的点乘 要求:尽量高效地实现,需要同时考虑时空复杂度。
二面
1、先问项目的一些细节
2、深度学些基础
smoothL1
fpn的结构
4. detection 的发展,从 RCNN 到 CenterNet
5. 着重讲 Faster RCNN,问的非常细, RPN原理,。9 种Anchor怎么来的,为什么这样设计Anchor。哪些为正类,哪些为负类。Loss怎么设计的,tx,ty,tw,th。
6. 在同时考虑 pooling, stride, padding 的情况下,计算 depthwise conv 和 pointwise conv 过程中每一步的计算量和feature map的尺寸
roi pooling和roi align的区别,怎么做插值,线性插值,spline插值,写插值公式。这个问题二面和三面都被问到了:https://blog.csdn.net/kk123k/article/details/86563425
1、论文讲下,没有提问题
2、RPN介绍一下
3、卷积神经网络的复杂度分析,Inception V1,V2,V3分析
https://zhuanlan.zhihu.com/p/31575074?utm_source=wechat_session&utm_medium=social&s_s_i=qrAaGyAjaUf6N1tDiObxvW0s7JAUoTQeK%2F25NdNZI3c%3D&s_r=0
4、轻量化网络结构总结:https://www.jianshu.com/p/2d58e5fc9f59?from=groupmessage
5、池化有哪些方法,分别用在什么场景下
6、BN 的原理,前向传播,反向传播推导:BN公式中epsilon的作用是,参考https://blog.csdn.net/biubiubiu888/article/details/90171087
-
eps: a value added to the denominator for numerical stability.
-
Default: 1e-5
关于BN的作用、前向,反向传播推到讲的很好:https://zhuanlan.zhihu.com/p/26138673
非常全面的知乎介绍:https://zhuanlan.zhihu.com/p/34879333
非常清晰简介的知乎介绍:https://www.jianshu.com/p/5ea8b994d8f2
7、激活函数有哪些?ReLU 的优缺点
8、focal loss 如何实现难分样本训练,如何解决正负样本不均衡?
https://blog.csdn.net/qwer7512090/article/details/93136325?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522159416701219724843335801%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=159416701219724843335801&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v3~pc_rank_v2-2-93136325.first_rank_ecpm_v3_pc_rank_v2&utm_term=focal+loss
9、anchor-free 论文读过哪些?
10、NMS 的原理,什么情况下不 work? 如何解决?编程:计算两个框的 IOU
理论:https://blog.csdn.net/bingbingxie1/article/details/86571112
https://blog.csdn.net/weixin_41665360/article/details/99818073?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-6.compare&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-6.compare
代码:https://blog.csdn.net/mooneve/article/details/100537621?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.compare&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.compare
11、
12、Kmeans 原理介绍下
13、深度学习框架如何实现数据的加载?
14、讲一下你熟悉的优化器,说一下区别或发展史
https://blog.csdn.net/jinxiaonian11/article/details/83141916?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522159531677419725222438871%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=159531677419725222438871&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v3~pc_rank_v3-7-83141916.pc_ecpm_v3_pc_rank_v3&utm_term=%E4%BC%98%E5%8C%96%E5%99%A8
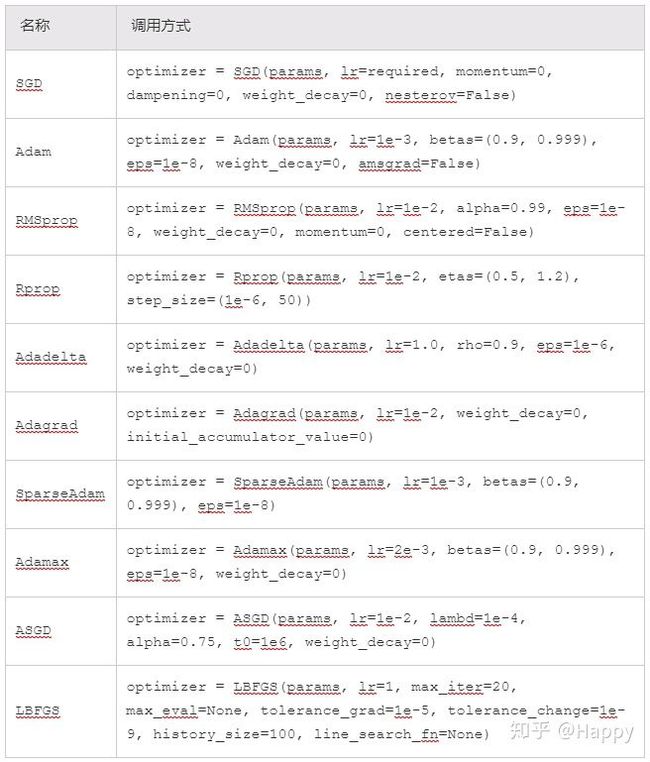
15、1x1卷积的作用
16、经典分类网络backbone
17、讲一下inception系列
18、
19、输入为L*L,卷积核为k*k,还有步长s和padding p,求输出尺寸?(L1 = (L-k+2*p)/s + 1)
接上题,求操作的FLOPs?(FLOPS = k*k*c1*c2*L1*L1)
20、过拟合要怎么解决?(减少模型参数、早停、正则化、数据增强、GAN合成数据、dropout、few shot learning,等等等等)
21、几个激活函数都有什么优缺点(sigmoid, tanh, relu, lrelu等)
1、fpn结构,fpn解决什么问题
2、输入图像大小,目标物体大小,anhor大小的设置
3、focal loss解决什么问题,如何写,每个参数有什么作用
28、说说bn
bn是解决梯度消失问题的,通过bn能使数据在输入到激活函数之前回到导数较大的位置
#解决问题
解决内部数据分布不稳定问题
#做法
统计mini-batch个样本的期望和方差从而进行归一化,但这样会导致数据表达能力的缺失,所以要引入两个参数从而恢复数据本身的表达能力
#优势
使得网络中每层输入数据的分布相对稳定,加速模型学习速度
允许网络使用饱和性激活函数,缓解梯度消失问题
具有一定的正则化效果
29、bn是做了归一化吗
先做了归一化,例如先减去期望再除以方差,然后再乘以一个参数和加上一个参数,这两个参数是可学习的
30、bn是在哪一维进行操作的
在mini-batch和通道这两维,描述了一下具体是怎么算的。我举了个例子,四维tensor,分别是[n,c,h,w],然后bn是统计每张特征图的期望和方差,而这个期望和方差是n个样本同一张特征图的期望和方差
31、那gn有什么用
gn是解决bn对mini-batch过度依赖,gn是在通道处进行分组统计,不依赖mini-batch
32、bn和gn都在哪用
bn和gn我所了解的是在目标检测,当然图像分类也用到bn
others:
1、如何根据实例分割的标注,圈出实例的边界框?
2、经典分割网络
3、算法题
1)链表判断是否有环,归并排序描述,二叉排序树时间复杂度
1)leetcode958 判断是否是完全二叉树。之前刷面经看到了,非常感谢大家分享面经。
2)leetcode3 最长不重复子串
3)算法题:一个整数数组A,求Ai-Aj的最大值Max,i 4)一个图片中心逆时针旋转30度后,求最小外接矩形长和宽,说一下有哪些解决方法 具体参考https://blog.csdn.net/flyyufenfei/article/details/80208361 6)编程题,LEETCODE 448,要求时间o(n),空间o(1)。这题还好,顺利做出来了。 7)买卖股票两次的最大收益,LEETCODE 123 8)给出一条长度为 9)给出一个数组 10)判断链表有环 11)二叉树中序遍历 12)一个链表,奇数下标递增,偶数下标递减,使其总体递增。 13)给一个数组,求其所有数都平方后,共有多少个唯一的值。 14)a , b ~ U(0,1), a 和 b 独立。求 E(max(a,b)) 这题很简单,直接遍历每个 9)给定一个字符串,对该字符串进行删除操作,保留 k 个字符且相对位置不变,使字典序最小。 题解 主要思想是这样的,最后要保留 k 个字符,那么第一个字符只能在下标 0 ~ n-k 中寻找,那肯定找最小的啊,如果有多个就找最前面那个,把它的位置记为 pos。 然后第二个字符肯定得在下标 pos ~ n-k+1 中寻找,还是一样的思路,找到以后更新 pos 位置,依次找下去找到 k 个为止。 所以我就利用了 map 的特性,把寻找窗口内的字符个数做一下统计,然后取出 map 中的第一个字符就是字典序最小的了,次数减一,如果减到 0 了就删除掉。 然后从 pos 位置开始遍历,直到第一个等于你刚刚取出的字符为止,更新 pos 位置。 最终的时间复杂度是 ,可以直接看作 。 最优解: 最优解当时没想出来,是用单调栈。维护一个递增的单调栈,我们的目标是保留 k 个字符,也就是删除 n-k 个字符。 那么如果栈顶元素大于当前遍历元素,并且还没删够 n-k 个,就出栈,当作删除了一个元素。否则的话如果删够了,不管大小关系统统入栈,因为你没法删了。 最后全遍历完了,如果还没删够,那就继续出栈,直到删够为止。最后把栈里的字符拼接成一个字符串就是答案了。 时间复杂度是 的。 10)给一个正数数组,找出最小长度连续子数组,其和大于等于 11)算法题如下:给个有序数组,然后求元素平方后不重复的元素个数,例如[-10, -10, -5, 0, 1, 5, 8, 10] 我思想描述对了,然后面试官说有更好的方法吗,我想了一下说没有,然后面试官让我选个语言实现一下,选择了python来实现,用到了字典,然后面试官说用集合会不会更好,我说会的 第 K 大的数 def f(arr):
if len(arr)==0 or len(arr)==1:
return 0
if len(arr)==2:
return arr[0]-arr[1]
p1 = 0
p2 = 1
max = arr[p1]-arr[p2]
n = len(arr)
while p2
答:第一种初中数学,几何知识;第二种,求解仿射变换矩阵(2x3),然后和原图相乘,就得到变换后的图片,也就知道了最小外接矩形的长和宽
5)概率题:x, y服从0-1均匀分布,求x+y<1的概率?x, y, z服从0-1均匀分布,求x+y+z<1的概率?L 的线段,除了头和尾两个点以外,上面还有 n 个整数点,需要在上面再放 k 个新的点,使得相邻的两个点之间的最大距离最小,求这个最小的距离。A,找到最大的 A[i] - A[j],要求 i > j。题解
A[i],维护它前面最小的那个数 minn,然后求出最大的 A[i] - minn 就行了。
这题也脑抽了,想了一堆方法,dp 复杂度太高,线段树太麻烦,最后用 map 勉强写了一下。
m。# 这是我的实现,没有用到集合,如果用到集合会更好data = [-10, -10, -5, 0, 1, 5, 8, 10]new_list = []for x in data: temp = x*x if temp not in new_list: new_list.append(temp)print(len(new_list))
# 这是群友给的代码,实在是太优秀了print(len(set([x**2 for x in data])))