Julia高性能计算实践记录(一)
洋洋洒洒写了5篇博客之后,尝试把理论用于实际,遇到了一些问题。本文是对实战中遇到问题的记录和思考。为了方便理解,把代码做了简化,原理不变。不定时更新,每次更新的日期和内容排在最前面,太长了会分为多篇文章。
为叙述简便,把@everywhere广播的对象简称为”广播对象“,例如:广播变量、广播函数等。读者应该已经理解”共享“和”广播“之间的区别。另外,@time第一次运行时会比较慢,要多运行几遍。
Jun 24, 2019
今天测试后发现,如果在并行化的循环体中引用了结构体数组,耗时会增大两个数量级。结论是并行程序里尽量不要用结构体数组。
Jun 23, 2019
我想做这样一件事:创建一个共享数组W,在一个函数f中并行修改W。代码如下:
using Distributed
using SharedArrays
addprocs(4-nprocs())
println("Running ",nprocs()," processes")
t = 2. ; nx=1000; ny=1000
W = SharedArray{Float64}((nx,ny),init=A->(A=zeros(nx,ny)))
function f()
@time @sync @distributed for i=1:nx
for j=1:ny
W[i,j] = W[i,j] + t
end
end
end
f()
rmprocs(2,3,4)
逐行解释这段代码——
addprocs(4-nprocs())
默认nprocs()=1,所以是开启3个远程Worker。此时打开任务管理器,会看到:
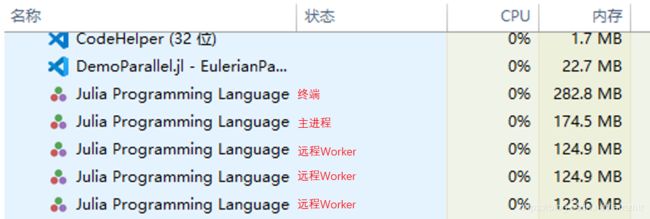
第一个是常驻的终端,不参与运算。第二个是主进程,不论是否并行,都会在有计算任务时启动。剩下三个是远程Worker。
t = 2. ; nx=1000; ny=1000
声明三个变量,第一个加了小数点,令Julia自动识别为浮点数。
W = SharedArray{Float64}((nx,ny),init=A->(A=zeros(nx,ny)))
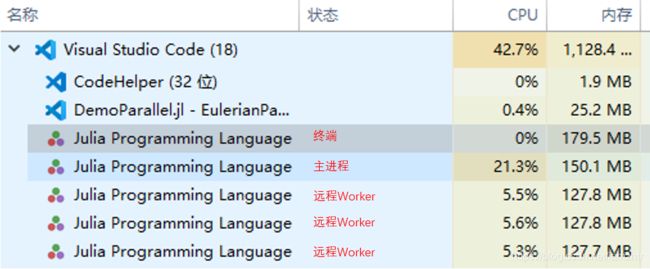
声明一个共享数组并初始化为零,默认存储在主进程上,所以在后面的并行计算中,盯着任务管理器会看到主进程完成得比三个远程Worker更快些。如图:
function f()
@time @sync @distributed for i=1:nx
for j=1:ny
W[i,j] = W[i,j] + t
end
end
end
这个函数有好几点需要解释:
f可以不带参数,此时所有变量和数组都自动继承到函数的局部域中。若带有参数,则该参数会遵循正常的参数传递方式,其余仍自动继承。例如修改为:
function f(nx)
for i=1:nx
for j=1:ny
W[i,j] = W[i,j] + t
end
end
end
W1 = f(nx)
W2 = f(nx+1)
会看到W1正常运行,而W2报错。
- 回到原先的代码中。
@distributed已经介绍过了。Julia的多层for循环可以简写为for i=1:m, j=1:n, k=1:p形式,但@distributed只能识别最外面一层,所以必须把最外层和里面几层拆开,写成:
@distributed for i=1:m
for j=1:n, k=1:p
<Expr>
end
end
由于Julia对数组是按列读取的,也即,遍历第一个指标i的速度显著快于其他指标,所以最好把指标i放在最内侧,并行时优先分割其他指标而保持指标i的完整性。修改为:
function f()
@time @sync @distributed for j=1:ny
for i=1:nx
W[i,j] = W[i,j] + t
end
end
end
f()
原代码消耗0.316919 seconds (185.12 k allocations: 9.060 MiB),修改后消耗0.262387 seconds (185.10 k allocations: 9.058 MiB),可见内存消耗几乎一致,但速度更快了。
- 在设计并行程序时,会很自然地想到是否要使用广播变量。上述例子表明:位于
@distributed结构的三个不同位置的变量nx, ny, t都不需要广播,所以在@distributed里不被多进程修改的变量不需要广播。那么假如要修改变量,应不应当广播呢?我们来看下面的例子:
function f()
@time @sync @distributed for j=1:ny
for i=1:nx
@everywhere t += 1
W[i,j] = W[i,j] + t
end
end
end
f()
假如去掉其中的@everywhere就会报错,证明广播是可行的。然而,你会发现计算时间大幅延长,因为@everywhere是一个远程调用命令,反复执行它是很耗时间的。如果你把它挪到前面,像这样:
@everywhere t = 2
function f()
@time @sync @distributed for j=1:ny
for i=1:nx
t += 1
W[i,j] = W[i,j] + t
end
end
end
f()
系统会报错。那么到底怎样才是合理的方法?答案是把t改为参数,像这样:
function f(t)
@time @sync @distributed for j=1:ny
for i=1:nx
t += 1
W[i,j] = W[i,j] + t
end
end
end
f(t)
会看到计算时间增加得很少。这种做法不需要广播。但是!!!当你打印W时会发现计算结果变了。举例来说,假如你希望一致地修改t后加到W上,以nx=3; ny=2的情况为例,得到的W是:
julia> W
3×2 SharedArray{Float64,2}:
3.0 3.0
3.0 3.0
3.0 3.0
如果用上面的传参方法会得到:
julia> W
3×2 SharedArray{Float64,2}:
3.0 3.0
4.0 4.0
5.0 5.0
表明t的修改沿着指标i的维度被叠加了。而用@everywhere t+=1方法会得到:
julia> W
3×2 SharedArray{Float64,2}:
4.0 4.0
6.0 6.0
8.0 8.0
这就更夸张了,t的修改每次在i方向叠加时还在j方向上也叠加了一遍。问题出在哪儿呢?很明显,是表达式的位置有问题,改成下面这样:
function f2(t)
@time @sync @distributed for j=1:ny
t+=1
for i=1:nx
W[i,j] = W[i,j] + t
end
end
end
获得了正确的结果。结论是:@distributed结构的最外层循环是分割开的,互相独立,变量修改不会叠加。但里层循环依旧是按照一般程序的循环规则,会把修改进行叠加。使用@distributed时要记牢这一点。
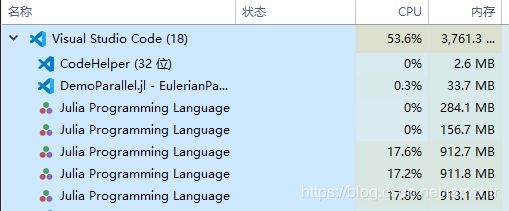
@sync是为了确保各进程全部完成任务后才继续往下走(下一个语句是@time)。如果不加@sync,会看到@time迅速返回了一个结果0.012252 seconds (8.00 k allocations: 421.867 KiB),此时任务管理器里各进程还在计算中,可见@time返回的是只是发起远程调用的消耗。把nx和ny设定得更大些会看得更明显。如果在一部分进程尚未完成计算的情况下打印W,会看到它的一部分元素没有改变。由于共享数组默认存储在主进程上,一般主进程会率先完成,随后其余进程几乎同时完成,如图:
rmprocs(2,3,4)
最后,必须像这样关闭多余的进程,否则再次执行代码时系统会为已有的进程增加新的内存,导致占用内存增加一倍,多运行几次就吃不消了。关闭远程进程后如下图:
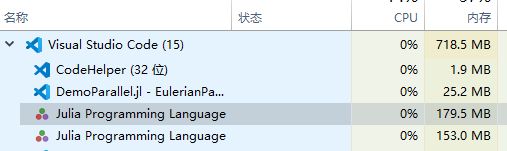
但记得不要试图关闭主进程,那样系统会拒绝执行rmprocs()命令。