目标检测算法YOLO算法介绍
YOLO算法(You Only Look Once)
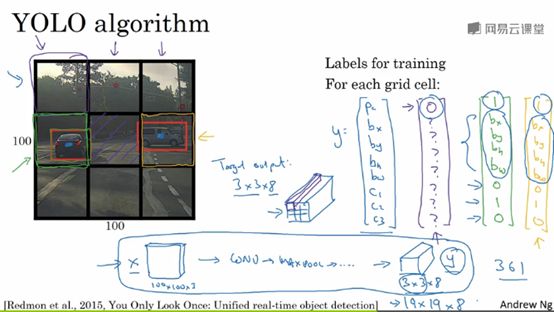
比如你输入图像是100x100,然后在图像上放一个网络,为了方便讲述,此处使用3x3网格,实际实现时会用更精细的网格(如19x19)。基本思想是,使用图像分类和定位算法,然后将算法应用到9个格子上。更具体一点,你需要这样定义训练标签,对于9个格子中的每一个都指定一个标签y,其中y是一个8维向量(与前面讲述的一样,分别为Pc,bx,by,bh,bw,c1,c2,c3,其中Pc=1表示含有目标,Pc=0表示为背景;c1,c2,c3表示要分类的3个目标,如行人、汽车、摩托车,不包括背景)。9个格子,每个格子都有这样一个8维的向量,对于不包含目标的格子,标签y=[0, ? , ? , ? , ? , ? , ? , ? , ?],?表示任意值。对于包含目标的格子,YOLO算法是这样处理的,取每个对象的中心点,然后将这个对象分配给包含这个对象中心点的格子,所以下图中左边的汽车就分配到第4个格子(从左往右,从上往下数,图中绿色方框的格子),因此中间第5个格子不包含目标。对于第4个格子的目标标签是这样的:y=[1, bx, by, bh, bw, 0, 1, 0]。因此,对于任意一个格子,你都会得到一个8维输出向量,由于这里是3x3的网格,所以有9个格子,故总的输出尺寸是3x3x8。
如果你现在要训练一个输入为100x100x3的神经网络,最后会映射到一个3x3x8的输出尺寸。所以你要做的就是,有一个输入x,有对应的3x3x8的目标标签。当你使用反向传播训练神经网络时,将任意的输入x映射到这类输出向量y。
这个算法的优点是,网络可以输出精确地边界框。所以测试的时候,你做的是提供输入图像x,然后跑正向传播,直到你得到这个输出y,然后对于这里3x3位置对应的9个输出,我们就可以读出1或0。只要每个格子中目标的数量没有超过一个,这个算法应该是没有问题的;对于一个格子中存在多个对象的问题,以后再讨论。实践中,我们可能会使用更精细的19x19网格,所以就是19x19x8,这样的网格精细的多,那么多个对象被分配到同一个格子的概率就很小。另外再提一句,把对象分配到一个格子的过程是,你观察对象的中心点,然后将这个对象分配到其中心点所在的格子,所以即使对象可以横跨多个格子,也只会被分配到9个格子其中之一。
1) 神经网络输出边界框可以具有任意宽高比,并且能输出更精确的坐标,不会受到滑动窗口分类器的步长大小限制
2) 这是一个卷积实现,你并没有在3x3网格上跑9次算法,不需要让同一个算法跑9次,相反,这是单次卷积实现,但你使用了一个卷积网络,有很多共享的计算步骤,所以这个算法效率很高
事实上,YOLO算法有一个好处,因为这是一个卷积实现,它的运行速度非常快,可以达到实时识别。
另外一个小细节,如何编码这些边界框(bx, by, bh, bw)?
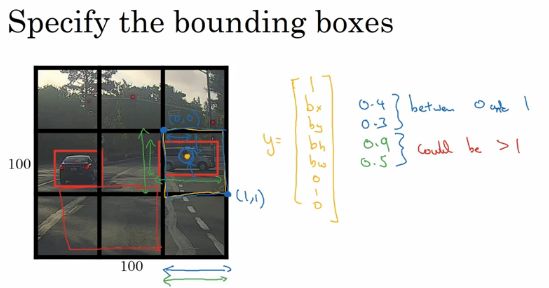
上面的图中有两辆车,我们有3x3网格,以右边的车为例,第6个格子有汽车,所以目标标签y中Pc=1,后面的c1,c2,c3分别为0,1,0(假设代表行人、汽车、摩托车三个类)。
在YOLO算法中,对于这个边界框,我们约定每个格子的左上角是(0, 0),右下角坐标是(1, 1),要指定汽车中心点(图中橙色点)的位置,bx大概是0.4,by大概是0.3,然后是边界框的高度,用格子总体宽度的比例表示,因此这个红框的宽度可能是格子宽度的90%,因此bh=0.9;它的高度大概是格子高度的一半,因此bw=0.5。.换句话说,bx,by,bh,bw单位是相对格子尺度的比例,因此bx和by必须在0和1之间,而bh,bw可能大于1。当然也有其他的约定方式。
如何判断目标检测算法运作良好?
----交并比(IoU,intersection over union),可以用来评价目标检测算法
IoU,计算两个边界框交集(图中橙色阴影部分)和并集(图中绿色阴影部分)之比,即计算交集的大小
一般情况下,在计算机视觉任务中约定,如果IoU大于或等于0.5,就说明检测正确;如果预测器和实际边界框完美重叠,那么IoU就是1。具体情况下,IoU阈值可以随具体任务进行设置。

非极大值抑制抑制NMS
目前为止,目标检测中的一个问题是,你的算法可能对同一个对象作出多次检测,非极大值抑制这个方法可以确保你的算法对每个对象只检测一次。
举个例子,假如你需要在这张图片里检测行人和汽车,你可能会在上面放19x19网格,理论上这辆车只有一个中点,所以它应该只被分配到一个格子里,而实践中当你跑目标分类和定位算法时,对每个格子都跑一次,可能会有多个格子认为对象的中心点在其自己的格子内。
因为你要在361格子上都跑一次,图像检测和定位算法,那么可能很多格子都会说我这个格子里有车的概率很高,所以当你跑算法的时候,最后可能会对同一个对象做出多次检测,如下图所示。因此非极大值抑制做的就是清理这些检测结果,这样一辆车只检测一次,而不是每辆车都出发多次检测。
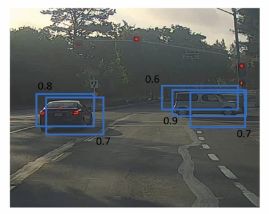
所以具体上,这个算法是这样做的,首先看看每次报告,每个检测结果相关的概率为Pc。首先看概率最大的那个,在这个例子中是0.9,然后就说这是最可靠的检测,之后,非极大值抑制就会逐一审视剩下的矩形,所有和这个最大的边界框有很高交并比,高度重叠的其他边界框,那么这些输出就被被抑制,所以这两个矩形Pc分别为0.6和0.7,它们和0.9的矩形有很高的重叠度,因此这两个矩形就会被抑制。接下来逐一审视剩下的矩形,找出概率最高的那个,是左边0.8概率的那个矩形,然后非极大值抑制算法就会去掉其他IoU值很高的矩形。最后剩下的矩形框就是最终结果。
非极大值抑制意味着,你只输出概率最大的分类结果,但是会抑制那些很接近但不是最大的预测结果。
算法细节
首先在这个19x19网格上跑一下算法,你会得到19x19x8的输出尺寸,不过对于这个例子,我们简化一下,我们只做汽车检测,因此每个格子(总共19x19=361个格子)输出的预测值就是[Pc, bx, by, bh, bw],Pc表示有对象的概率。

现在要实现非极大值抑制,你可以做的第一件事就是去掉所有的Pc值小于等于某一阈值(如0.6)的边界框,即抛弃所有概率低的边界框;接下来处理剩下的边界框,我们重复的选择概率Pc最高的边界框,然后把它输出成预测结果;接下来去掉所有剩下的边界框,所有任何没有达到输出标准的边界框,把这些和输出边界框有很高重叠面积和上一步输出的边界框有很高交并比的边界框全部抛弃,所有while循环的第二步是(上一张幻灯片变暗的那些边界框和高亮标记的边界框重叠面积很高的那些边界框抛弃掉),不停的循环,直到每个边界框都判断过了,它们有的作为输出结果,另外的就被抛弃。
上述算法是针对单个目标的情况,如果你尝试同时检测三个对象,比如说行人、汽车、摩托车,那么输出向量就会有三个额外的分量;那么正确的做法就是独立进行三次非极大值抑制,对每个类别都做一次。

Anchor Boxes
目前为止,每个格子只能检测出一个对象,如果你想让一个格子检测出多个对象,你可以使用anchor box。
假设你有这样一张图,对于这个例子,我们继续使用3x3的网格,注意行人的中心点和汽车的中心点,几乎在同一个地方,两者都落到同一个格子中,所有对于那个格子,如果y输出这个向量,你可以检测3个类,行人、汽车和摩托,它将无法输出检测结果,所以我必须从两个检测结果中选择一个。
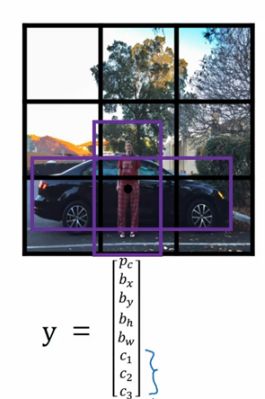
而anchor box的思路是这样的,预先定义两个不同形状的anchor box,你要做的就是把预测结果和这两个anchor box关联起来,一般来说,你可能会用更多的anchor box,可能要5个或者更多,但是此处为了讲解方便,就用两个anchor box。你要做的就是定义类别标签,用的向量不是上面那个,而是重复两次。即为每个anchor box赋予一个与上面一样的标签y=[Pc, bx, by, bh, bw, c1, c2, c3]。因为行人的形状更类似于anchor box1的形状,而不是anchor box2的形状,所以你可以用前8个数值来预测行人。
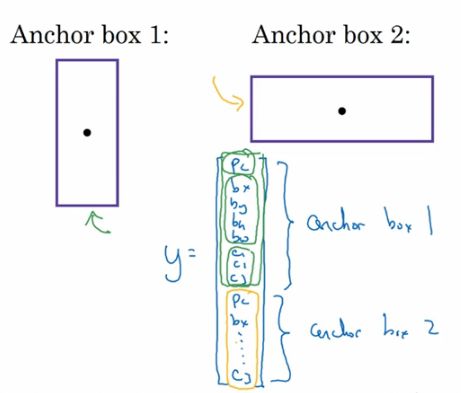
面来看一个具体的例子。
由于行人更类似于anchor box1的形状,所以对于行人来说,我们将他分配到向量的上半部分,同理,汽车被分配到下半个格子。现在,其中一个格子有车,没有行人,那么当一个格子中有三个对象的时候,这种情况下算法处理不好;或者,同一个格子中两个对象的anchor box形状也一样,这样的情况算法也处理不好。
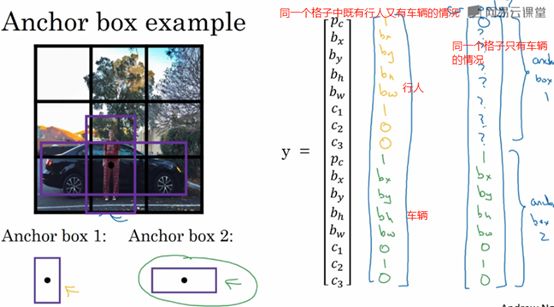
最后,如何选择anchor box?大家一般是手工指定anchor box形状,你可以选择5到10个的anchor box形状,覆盖你想要检测的对象的各种形状。K-Means可以将两类对象形状聚类,如果我们用它来选择一组anchor box,选择最具有代表性的一组anchor box,可以代表你试图检测的十几个对象类别,这是自动选择anchor box的高级方法。
YOLO算法
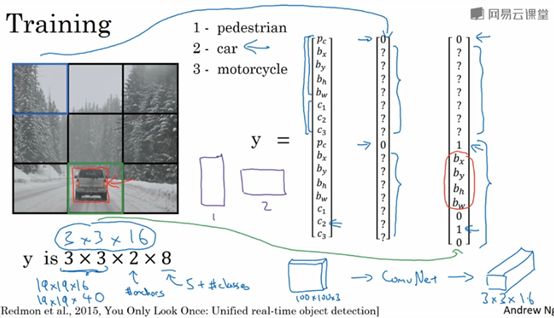
首先看看如何构造数据集。假设你要训练一个算法,要检测三种对象,行人,汽车和摩托,你还需要显式指定完整的背景类别。如果你要用两个anchor box,那么输出y就是3x3(因为使用的是3x3的网格),然后x2(anchor box的数量),最后x8。要构造训练集,你需要遍历9个格子,然后构成对应的目标向量y。所以对于第一个格子,里面没有出现要检测的对象,所以第一个格子的目标y=[0,?,?,?,?,?,?,?,0,?,?,?,?,?,?,?],对于下图中汽车所在的那个格子,其对应的目标向量y=[0,?,?,?,?,?,?,?,1,bx,by,bh,bw,0,1,0](汽车的形状与第二个anchor box类似)。最终输出尺寸是3x3x16(实际中可以使用19x19x16,如果需要用到更多的anchor box,那可能是19x19x5x8)。这是训练集,然后你训练一个卷积网络,输入是图片,大小可能是100x100x3,然后你的卷积网络最后输出尺寸是3x3x16或者3x3x2x8。
接下来,我们看看算法如何做出预测。输入图像,你的神经网络的输出尺寸是3x3x2x8,对于9个格子,每个都有对应的向量。最后要跑一下这个非极大值抑制。
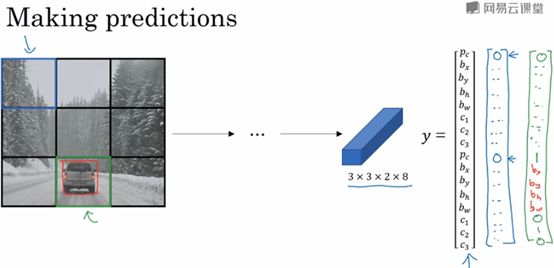
为了让内容更有趣一些,我们看看一张新的测试图片,这就是运行非极大值抑制的过程。如果你使用两个anchor box,那么对于9个格子中任何一个都会有两个预测的边界框,其中一个的概率Pc很低,但9个格子中,每个都有两个预测的边界框,比如说我们得到的边界框是下面这样的,注意有些边界框可以超出所在格子的高度和宽度。

接下来,你抛弃概率低的预测,去掉那些连神经网络都说这里很可能什么都没有的边界框。

最后,如果你有三个对象检测类别,你希望检测行人、车子和摩托,那么你要做的就是对于每个类别,单独运行非极大值抑制,处理预测结果就是那个类别的边界框。