hive
什么是hive?
Hive是一个基于hadoop的数据仓库平台,通过hive,我们可以方便地进行ETL的工作。hive定义了一个类似于SQL的查询语言:HQL,能够将用户编写的QL转化为相应的Mapreduce程序基于Hadoop执行。
hive数据放在哪里?
数据在HDFS的warehouse(python05:50070/user/hive/wareouse/)目录下,一个表对应一个子目录。
hive的表分为两种,内表和外表。
Hive 创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。
在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据。这样外部表相对来说更加安全些,数据组织也更加灵活,方便共享源数据。
CREATE TABLE 创建一个指定名称的表,如果相同名称的表存在则抛异常,用户可以用 IF NOT EXIST选项来忽略这个异常
EXTENRAL 创建一个外部表,同时指定一个指向实际数据的路径(LOCATION)
LIKE 用户复制现有的表结构,但不复制数据
COMMENT 可以为表和字段添加描述
SHOW TABLES; 显示所有表
SHOW TABLES '.*S''; 按正则表达式显示所有表
ALTER TABLE 表名 ADD COLUMNS(NEW_co0l int); 表添加列
ALTER TABLE 表名 ADD COLUMNS(NEW_col int COMMENT' 注释 ');
在hive里创建一个表:

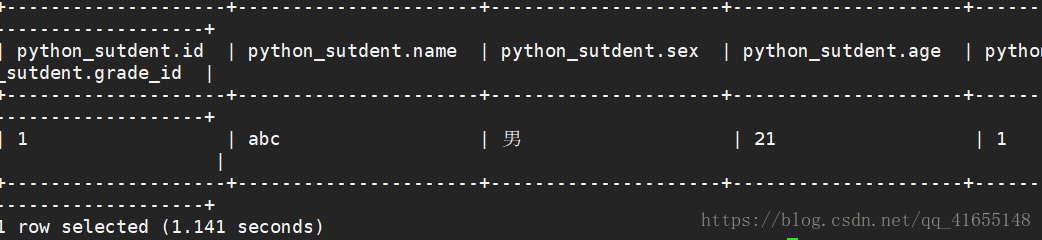
查询结果 select * from python_sutdent;

插入数据:

再进行查询 select * from python_sutdent;
添加分区:
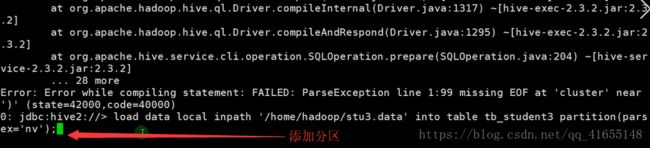
添加分区的时候报这个错:

执行一下两句:
set hive.mapred.mode=nonstrict;
set hive.strict.checks.bucketing=false;
再执行

设置配置hive文件
路径:/home/hadoop/opt/apache-hive-2.3.3-bin/conf
vi hive-site.xml 添加 nonstrict
/hive.mapred.mode查找
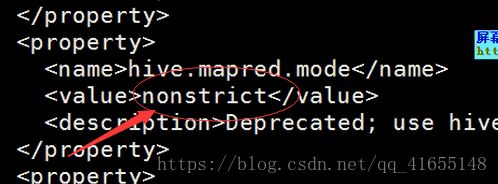
/hive.strict.checkes.bucketing查找
改成 false

改完保存完以后退出重新启动下hiveserver2
load data inpath "user/hadoop/xxxx."into table table_name :是将文件移动到/user/hive/werehouse/xxx.db/xxx下
load data local .... 加载本地文件是做了一个复制的文件
基本的select 操作
SELECT[ALL | DISTINCT] select_expr,select_expr,....
FROM TABLE_REFERENCE
[WHERE WHERE_condition]
[GROUP BY col_list[HAVING condition]]
[CLUSTER BY col_list
| DISTRIBUTE BY col_list[SORT BY | ORDER BY col_list]
]
[ LIMIT number]
order by 和sort by 的不同
order by 全局排序
sort by值再本机做排序
查询男女各多少人 count(*)做统计:

在spark 上连接hive
cd opt/spark-2.2.1-bin-hadoop2.7/conf
![]()
cd ..
cd sbin
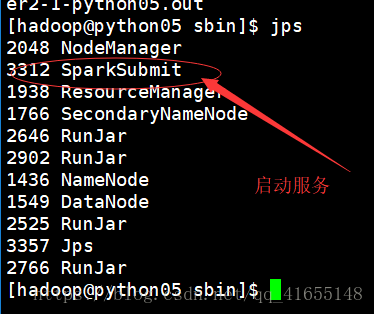
start-thriftserver.sh
jps 后查看: