2019移动广告反欺诈算法挑战赛之数据清洗
原始数据集的各个属性:
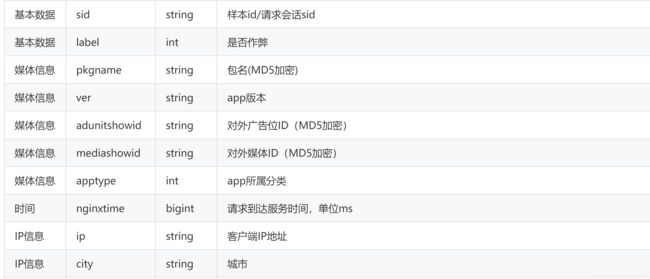
1: sid每条记录的索引
2: label, 训练的标签
3: pkgname,一个包名代表一个应用,包名必须唯一,
4: ver, app版本号,
5: 对外广告位ID,应该是投放广告的位置
6: 对外媒体ID, 通过什么方式传播的广告
7: apptype, app的类别
8:请求达到服务时间, 什么时候请点击了该广告
9: ip, city
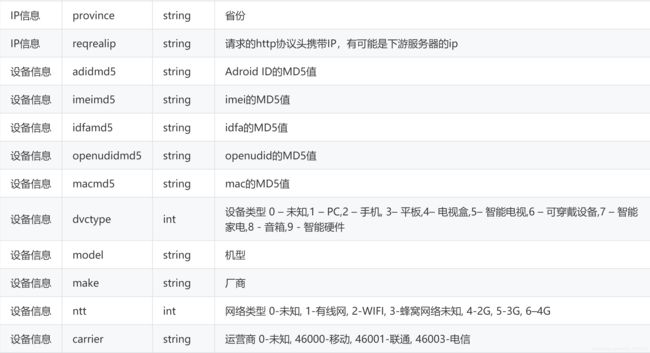
10: province,该ip地址所在的省市
11: reqrealip: 表示http请求头 包括 User-Agent:产生请求的浏览器类型。Accept:客户端可识别的内容类型列表。Host:主机地址, 具体可参考https://www.cnblogs.com/Hellorxh/p/10867892.html
12: Adroid ID不是用于标识你的设备的。他是标识一个设备的一次刷机行为的。 换句话说,每次刷机的时候,这个ID会改变
13:imeimd5: 用于在移动电话网络中识别每一部独立的手机等移动通信设备,相当于手机号的身份证
14:idfamd5: iOS独有的广告标识符
15:openudidmd5: 苹果手机上专有的东西,用来表示app类型,不是很理解,可以参考知乎上的讲解
16:macmd5: 表示唯一的苹果设备
17:model: 手机的型号
18: make: 设备的厂商
19: ntt: 使用什么类型的网络访问的广告
20: carrier: 使用什么那家网络访问的该广告

21: osv 设备的操作系统的版本号
21-25: 设备的基础信息,
-----------------------------------------------------------------------------------------------------------------------
数据的探索:
主要使用pandas两个基本函数:
1、为了能够打印出所有的列,使用pandas设置打印的列能够显示的行数和列数
import pandas as pd
pd.set_option('display.max_columns', 1000)
pd.set_option('display.max_rows', 1000)
2、查看某一列的唯一值 : len(new_data['ver'].unique())
3、统计每一列元素的出现次数: new_data['ver'].value_counts()
pkgname: 从中可以看到有2328应用 其中263239为空表示不知道应用属于哪个产品 产品分布严重不均于最多出现的次数18万 最少出现次数是1次。

数据清洗: 2019/09/15 更新
清洗方案是按照某列样本出现的次数,从上到下一次发现异常值的数据,找出异常值的规律,进行批量修改。对于出现次数比较多的异常数据使用raplace()替换也可以。对于出现非常少的数据(长尾数据)直接进行合并为一类,以ver版本号为例:


我们可以看到数据中出现的数据明显的异常值是 30927000,30928000,30936000,但是它和3.9.36.000.0730.2100明显可以归为一类,所以可以对这类数据进行批量处理。


我们可以还有一类数据是没有. 数字本身没啥规律,例如 470,150,193。对于这类数据每隔一位加上标点即可。

可以发现最后的数据分布不均匀,对于前面的数据可能出现上万次,但是到后面的数据仅仅只有1、2次,所以清洗之后我们可以直接选择排名前N位的数据, 对于后面的数据我们直接归为一类,好处是能够节约内存。
清洗代码如下:
# 这个版本是最后的版本 不在进行任何的修改操作
def my_ver_trans(x):
x = str(x).replace('[', '').replace(']', '').replace('".', '').replace('"', '')
if x[0:3] == '309':
if len(x) > 4:
return '3.9.' + x[3:5] + '.' + x[5:7]
else:
return '3.9.' + '0.0.0'
if x[0:3] == '190':
if len(x) > 4:
return '1.9.' + x[3] + '.' + x[4:]
else:
return '1.9.' + '0.0'
if '521000' in x or '5.2.1' in x:
return '5.2.1.0'
if '.' not in x:
if len(x) >= 3:
return x[0] + '.' + x[1] + '.' + x[2] + '.' + x[3:]
elif len(x) > 1 and len(x) < 3:
return x[0] + '.' + x[1] + '.0'
else:
return x + '.0.0.0'
# 处理带点 但是数据位数小于三位的情况
tmp = x.split('.')
if len(tmp) < 3:
return x + '.0.0'
return x
print('loading ver .............')
all_df['ver'] = all_df.ver.apply(my_ver_trans)
# 对ver取排名靠前的1500位
vers = []
for i in all_df['ver'].value_counts().head(1500).index:
vers.append(i)
all_df.loc[~all_df['ver'].isin(vers), 'ver'] = 'others'