2018.5-2019.1基于FPGA平台的目标检测网络实现
2018.5 - 2019.1 基于FPGA平台的目标检测网络实现,将目标检测模型实现为c++代码,成功通过HLS工具部署于FPGA平台上,实现公交摄像头画面中人头的检测。
目录
一、项目背景
1.1 公司背景
1.2 应用背景
1.3 技术路线
二、python端
2.1 MTCNN与训练过程
2.2 mAP的测试
2.3 网络结构的更改
2.4 输出python训练的权重到c代码端
python之中的顺序
c代码之中的顺序
三、c代码端
3.1 文件描述
程序文件
权重文件
更改结构顺序
3.2 卷积的更改
初始的依赖openBLAS的卷积函数
重新运用定义编写卷积代码
加入bias和ReLU
存储顺序
四、硬件端
4.1 卷积IPcore
存储
运算
接口
4.2 IPcore的验证
4.3 IPcore报告
时间资源
空间资源
4.4 ARM端工作
交叉编译工作
调用IPcore工作
一、项目背景
1.1 公司背景
智能交通上市公司,06年成立,2014年上市。车联网,物联网,智能公交,3G/4G监控,北斗/GPS监控等。
1.2 应用背景
公交车的车载终端有连接公交车的摄像头,希望根据摄像头画面估计出上车人数和下车人数。所以需要有一个目标检测网络先检测出上车下车的人头数。
因为FPGA平台价格较低,例如项目所用的zyqn系列FPGA,开发板2000元左右,单独FPGA板成本大概在500元,(开发板与FPGA板不一样,因为开发板模块更多,例如光电模块,通信模块,接口模块等等。FPGA板仅仅需要一个用于运算的FPGA板子,项目需要还要带一个单片机)。
项目目的就是希望把目标检测网络实现到FPGA上,从公交摄像头画面之中,把人头检测出来。
1.3 技术路线

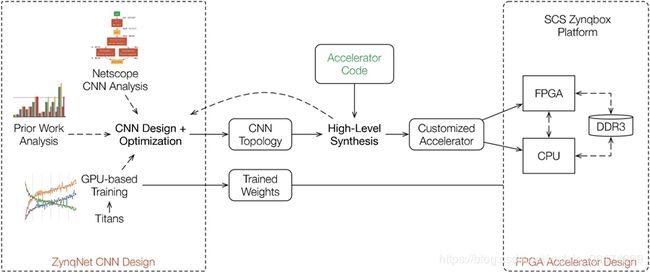

项目分为python端,c代码端,硬件端。
python端用于确定相应的网络模型结构,训练模型。从而根据相应的权重进行保存。
c++端用于实现神经网络的推断,也就是只有前馈的预测运算。根据相应的python端的权重,和输入图片,预测得出相应的bounding box。一是因为c++代码执行效率高,并且省去了训练的过程,只有前馈运算过程。二是实现为c++代码可以方便于后面的HLS部署于FPGA上。
硬件端用于部署相应的网络结构。分为ARM端和FPGA端,ARM端就是arm架构,可以用c++代码直接交叉编译即可,FPGA端为FPGA架构,需要将相应的程序通过HLS实现为IPcore,烧写到FPGA上,然后用ARM控制进行运算。
二、python端
端用于确定相应的网络模型结构,训练模型。从而根据相应的权重进行保存。早期使用YOLO,后因为YOLO运算量较大,权重文件大,并且所用FPGA板子为xilinx MIZ 7z020,很低端,片上BRAM和DDR都不够用。因此换用内存较小的MTCNN。
数据集为根据相应的公交画面标定和训练的。YOLO mAP为89,MTCNN降低30个点
2.1 MTCNN与训练过程
https://github.com/wangbm/MTCNN-Tensorflow,Multi task级联的CNN
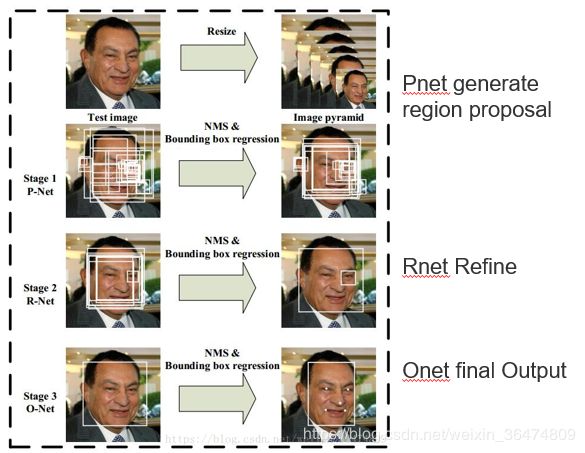
MTCNN是三个级联的网络,Pnet用于生成备选框,resize为不同的大小,然后根据响应在图像回归出12×12大小的框。
Rnet用于对备选框初次筛选,Onet用于确定最终输出的备选框。
所以训练过程需要训练三个网络。

训练流程见上面连接的内容。
2.2 mAP的测试
mAP为目标检测领域的基础指标。

首先标签相同交并比IoU>0.5表示网络检测正确。
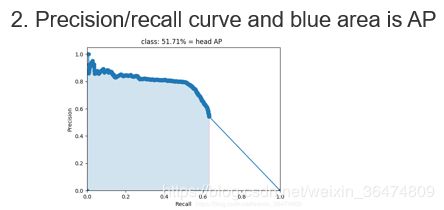
然后画出相应的查全率与查准率的曲线,积分得到的蓝色区域即为mAP。
![]()
各类的平均AP即mAP

测试mAP需要将程序做一定的修改,将所有图像的预测标签与groundTruth放入文件夹之中。然后测试。
这一系列过程被封装好,封装到test_all.py之中。
2.3 网络结构的更改

在原始结构的基础上,
- 重新制作公交人头数据集,重新训练以在公交人头数据集上运行
- 为了增加硬件平台的功能(最好确定为定长度的),将卷积固定为3x3,(为什么要固定卷积尺寸,因为硬件资源有限,所以必须固定结构的卷积能更少的占用硬件资源,从而实现重复调用)
- 去掉pooling的过程,运用stride为2的卷积来替代以增加并行性。
- 然后将PReLU改为ReLU,这样不用存储斜率。relu种类: https://blog.csdn.net/ScorpC/article/details/88186920
- 增加一定量的通道数量,以增加mAP。为减少运算,可以将Pnet与Rnet的阈值设高
- 在文件mtcnn.py之中
- 更改后的网络结构表 https://blog.csdn.net/weixin_36474809/article/details/85990687
2.4 输出python训练的权重到c代码端
python权重与c权重顺序很不一样。python之中权重为tensorflow的四维张量,c代码之中为线性存储的。需要算出偏移量也就是映射。通过python端将权重写出,写为二进制文件,就是.bin文件,c++端读取此.bin文件作为权重运算。
python之中的顺序

c代码之中的顺序

因为是线性存储,所以需要一系列偏移地址找到权重位置:

三、c代码端
3.1 文件描述
程序文件
- mtcnn.cpp .hpp : Network structure definition of MTCNN 网络结构的定义
- network.cpp hpp : Basic functions such as conv , relu , padding 基本的函数实现,比如卷积,reLU,padding
- pbox.cpp .hpp : definition of basic data format. 基本的数据结构定义。例如pBox结构体,里面存了宽,高,通道数和数据指针指向数据。
权重文件
- Pnet.bin , Rnet.bin , Onet.bin total 3.0 MB 三个权重文件3MB,为了减少FPGA数据流量
- Generated by python 通过前面的python端训练产生。
- Read by readData function. 通过c文件之中的readData函数读取。之前c代码之中权重文件为.txt格式,我们改为 .bin格式,数据更紧密。
- readData function difinied in network.cpp, function called in mtcnn.cpp
更改结构顺序
c代码的网络结构需要与python代码的结构一致。每次更改网络结构之后,需要做以下的修改。
- Changing python code network structure。更改python代码的结构
- Rerun python training code 重新训练python端的代码
- Generate weight file. 输出权重文件
- In mtcnn.hpp , change the structure of class Pnet(Rnet,Onet) private definition. 在mtcnn.hpp程序之中更改类Pnet(Rnet,Onet)的private定义
- In mtcnn.cpp , change class Pnet(Rnet,Onet) construct function and destruct function. 在mtcnn.cpp更改相应的类的构造函数和析构函数
- Change parameters in dataNumber, pointTeam, readData for weight file read.更改与权重读取相关的三个函数及参量:dataNumber, pointTeam, readData。
- Change Init function for each layer buffer malloc.更改实现相应的层的init函数,init函数用于开辟内存空间。
- Change run function to run each layer. 更改每层的运行函数。
3.2 卷积的更改
卷积的更改较为重要,因为部署于硬件端的时候,是ARM控制FPGA运算。ARM端较容易移植,通过c++代码交叉编译即可。但是FPGA端需要通过HLS工具进行移植,是异构运算。因此此部分就是需要移除相应的依赖库。
初始的依赖openBLAS的卷积函数
openBLAS为线性代数实现的函数。旧的卷积实现为矩阵乘法,但是移植入FPGA的卷积不能用此结构实现。必须实现为底层的c++代码。
卷积的运用滑窗函数实现为一个二维矩阵,然后与权重排列成的二维矩阵实现矩阵乘。这也是大多数卷积的实现方式。但是这种方法无法实现于FPGA之上。并且每次进行取框函数会加大运算量。
Convolution in 2D matrix multiplication format:
// input Weight matrix * input feature matrix(Trans) = output feature matrix
// height (outChannels) height (3D_KernelSize) height (outChannels)
// width (3D_KernelSize) width (outFeatureSize) width (outFeatureSize)重新运用定义编写卷积代码
我们需要从卷积的定义出发,编写卷积函数。
Without feature_2_matrix process:
// outpBox [out_ChannelNum][out_height][out_width]
// +=weightIn[out_ChannelNum][in_ChannelNum][kernelWidth][kernelHeight]
// *pboxIn[in_ChannelNum][width][height] 伪代码如上,这样,既不用滑窗函数,而且生成的output也可以被下层当作feature直接运用。
定义出发的卷积方便zynqNet改为FPGA内并行的结构。实现加速。
加入bias和ReLU
卷积后的过程并入卷积函数利用并行化,尽可能多的将任务给FPGA实现。
存储顺序

四、硬件端
硬件端是最复杂的。首先卷积的IPcore需要通过HLS来实现。为什么通过HLS来实现?一是因为HLS可以直接将c++代码进行HLS,从而更好地保证逻辑特性,二是缩短实现周期,用verilog这种底层语言写出来要更久时间。
4.1 卷积IPcore
在此之前,我们需要了解FPGA的存储结构。
存储
四种存储方式,主要是下面几种。
- LUT,翻转寄存器,数据调用最快,直接参与运算。
- BRAM,片上RAM,调用数据需要一个时钟周期。
- DDR片上扩存存储,调用周期较长。因此采用的原则是尽量从BRAM上调取数据。少从DDR上搬运。但是权重文件过多,不得不从DDR上调取数据,需要用BRAM作为buffer,并行的从DDR调取数据到BRAM上。
- 移位寄存器。用于实现数据流操作。
- 还有其他的部分,可以在HLS工具里面查找到,例如LUT RAM,DSP RAM,具体可以通过HLS实现为不同的部分。
根据此存储结构,尽量将时钟调用周期短的和数据读取进行并行化。注意,大量权重文件存储于DDR上(BRAM存不下,不然全都存在BRAM上了),然后通过DDR与BRAM之间作为缓冲,然后BRAM之间并行实现并行的运算。
运算
运算结构:
- LUT,既是运算单元也是存储单元。
- FF,flip flop,翻转寄存器,可以参与运算。
- DSP48 ,运行浮点运算较快
运算地址时候,运算单元与相应的BRAM的分配要并行化。比如地址运算需要DSP48,及时根据HLS生成的报告加入优化指令并且增加并行性。
接口
三种类型的接口,卷积函数的FPGA实现(四)函数接口的HLS
- AXI-4,地址被实现为指针,较快,例如IPcore从DDR读取数据就需要用到此结构。
- AXI-lite,接口被实现为register,适合小数据量传输。例如函数参数的传递。
- AXI-strem,数据流,不需要地址。https://blog.csdn.net/weixin_36474809/article/details/81009769
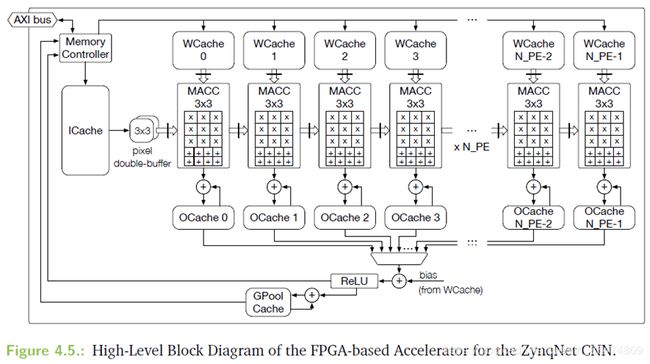
卷积IPcore的实现参考zynqNet的结构,在DDR上搬运数据,传入BRAM上,然后通过并行实现加速。
vivado HLS硬件化指令(一)HLS针对循环的硬件优化
vivado HLS硬件化指令(二)HLS针对数组的硬件优化
vivado HLS硬件化指令(三)HLS增大运算吞吐量的硬件优化
4.2 IPcore的验证
关于IPcore的实现有很多内容,可以参考之前的博客。首先需要嵌入MTCNN之中验证,逻辑通过,再用testBench进行验证。
- •Validated in MTCNN code 嵌入入MTCNN代码之中验证
- •Validated in HLS test bench (C-simulation) 嵌入HLS的test Bench之中验证。也就是实现c仿真。
- •Validated in synthesis and generate report 通过synthesisi和生成相应的报告
- •Export RTL 输出RTL代码
•C-RTL co-simulation C与RTL协同仿真。
4.3 IPcore报告
https://blog.csdn.net/weixin_36474809/article/details/85271940
时间资源
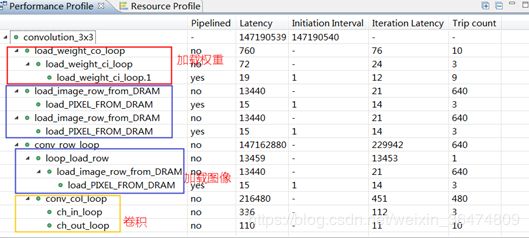
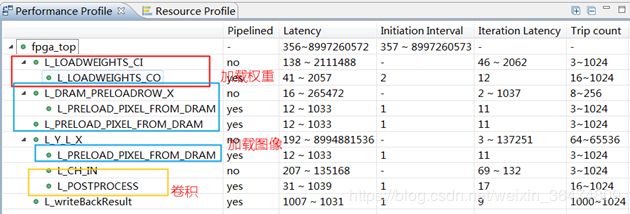
zynqNet的时钟周期如下,基本与卷积IPcore为同一个数量级。
从MACC的次数考虑
zynqNet的MACC次数固定为 : 152,731,648,整个网络运行时间为2s
MTCNN:
从43,543,288 到85,176,568
按照此时间预测,MTCNN的时间为:
From 0.57sec – 1.12sec
空间资源
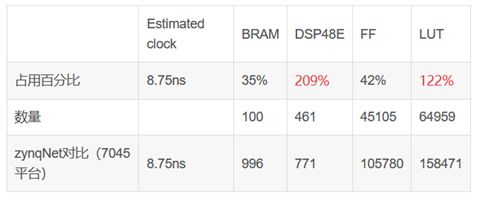
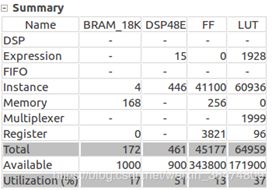
即使占用的资源比zynqNet少很多,但是MIZ7020平台上资源超出预期。
在7035平台上资源够用。
4.4 ARM端工作
ARM端的任务为
- 写数据到DDR上
- 调用FPGA端进行运算
- 运行神经网络

刚开始的MTCNN代码分开的开辟每层的卷积,对于调用IPcore来讲非常耗时。
交叉编译工作
虚拟机交叉编译openCV详细步骤及bug解决详解
虚拟机上安装openCV
zynq7020的ARM单片机编译与运行程序MTCNN
- 所以需要更改为在DDR一次性的开辟所有的内存反复调用。
- 首先交叉编译Open CV,其次交叉编译MTCNN程序,然后可以在FPGA的片上ARM运行
- 注意内存需要一次性开辟,不要像原代码那样,开辟了一系列小内存空间。影响IPcore获得偏移地址。甚至可以从权重文件中一边读取,一边写入DDR,因为ARM的RAM本来就很小,很容易堆栈溢出。
调用IPcore工作
- 然后实现IPcore,可以实现卷积IPcore的单次调用。
- 再用MTCNN程序反复调用卷积IPcore实现相应的卷积。