关于页面元素定位,可以根据 id、class、name 属性以及 link_text。
其中 id 属性是最理想的定位方式,class 与 name 属性,有时候也还行。
但是,如果要定位的元素,没有上述的属性,或者通过上述属性找到多个元素,该怎么办?
Selenium 提供了2种可以唯一定位的方式:
find_element_by_css_selectorfind_element_by_xpath
find_element_by_css_selector
原理
HTML 中经常要为页面上的元素指定显示效果,比如前景文字颜色是红色,背景颜色是黑色, 字体是微软雅黑,输入框的宽与高等。
以上这一切,都是靠 css 来告诉浏览器:要选择哪些元素, 显示怎样的风格。
如下图,豆瓣上“登陆豆瓣”的按钮,就是 css 告诉浏览器:.account-anonymous .account-form-field-submit .btn 这个按钮,背景颜色是浅绿色,高是34px 等

其中,.account-anonymous .account-form-field-submit .btn 就是 css selector ,也称为 css 选择器。
css selector 语法就是用来选择元素的。
既然 css selector 语法 天生就是浏览器用来选择元素的,Selenium 自然就可以将它运用到自动化中,来定位要操作的元素了。
只要 css selector 的语法是正确的, Selenium 就可以定位到指定的元素。
根据标签(tag)名定位
HTML 中,以下都属于标签:
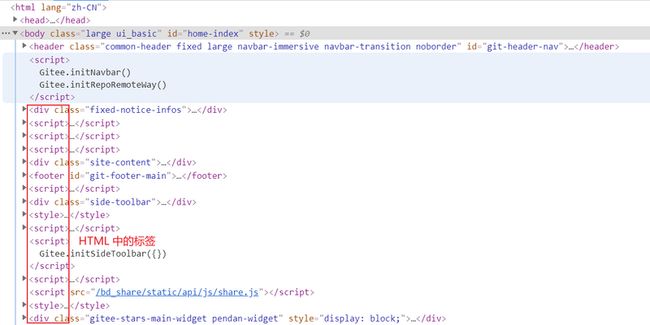
验证与搜索方式:
- 按
F12打开 开发者工具栏 - 按
Ctrl键 和 F 键, 显示搜索框
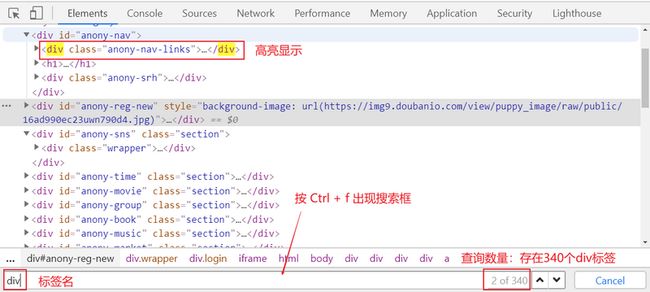
应用:
# find_element_by_css_selector 的应用:根据标签(tag)名定位
from selenium import webdriver # 导入 webdriver 模块
driver = webdriver.Chrome() # 调用 Chrome 浏览器
driver.get('https://www.douban.com/') # 打开豆瓣
element = driver.find_element_by_css_selector("a") # 根据 a 标签定位元素
print(element.text) # 打印 定位元素 的文本
driver.quit() # 关闭浏览器根据 id 定位
根据 id 属性选择元素的语法是,在 id 前面加上一个 "#" 号: #id值

应用:
# find_element_by_css_selector 的应用:根据 id 定位
from selenium import webdriver # 导入 webdriver 模块
from time import sleep # 导入 sleep 模块,可以使程序强制休眠
driver = webdriver.Chrome() # 调用 Chrome 浏览器
driver.maximize_window() # 窗口最大化
driver.get('https://www.baidu.com/') # 打开 百度
sleep(2) # 强制休眠 2 秒
element = driver.find_element_by_css_selector("#kw") # 根据 id 定位元素
element.send_keys("自动化测试") # 输入内容
sleep(3) # 强制休眠 3 秒
driver.quit() # 关闭浏览器根据 class 定位
根据 class 属性选择元素的语法是,在 class 值前面加上一个".": .class值

应用:
# find_element_by_css_selector 的应用:根据 class 定位
from selenium import webdriver # 导入 webdriver 模块
from time import sleep # 导入 sleep 模块,可以使程序强制休眠
driver = webdriver.Chrome() # 调用 Chrome 浏览器
driver.maximize_window() # 窗口最大化
driver.get('https://www.baidu.com/') # 打开 百度
sleep(2) # 强制休眠 2 秒
element = driver.find_element_by_css_selector(".s-top-login-btn") # 根据 class 定位元素
element.click() # 点击定位元素
sleep(3) # 强制休眠 3 秒
driver.quit() # 关闭浏览器根据子元素与后代元素定位
HTML中, 元素内部可以包含其他元素, 比如 下面的 HTML片段:
内层11
内层12
内层21
子元素
如果 元素2 是 元素1 的 直接子元素, css selector 选择直接子元素的语法是:
/* 一个层级 */
元素1 > 元素2
/* 多个层级 */
元素1 > 元素2 > 元素3 > 元素4
/* layer1 是 container 的直接子元素 */
#container > #layer1
/* inner11 是 layer1 的直接子元素,是 container 的后代元素 */
#layer1 > #inner11
#container > #layer1 > #inner11
/* span1 是 inner11 的直接子元素,是 layer1 与 container 的后代元素 */
#inner11 > #span1
#layer1 > #inner11 > #span1
#container > #layer1 > #inner11 > #span1实际应用:

# find_element_by_css_selector 的应用:根据 子元素 定位
from selenium import webdriver # 导入 webdriver 模块
from time import sleep # 导入 sleep 模块,可以使程序强制休眠
driver = webdriver.Chrome() # 调用 Chrome 浏览器
driver.maximize_window() # 窗口最大化
driver.get('https://www.baidu.com/') # 打开 百度
sleep(2) # 强制休眠 2 秒
element = driver.find_element_by_css_selector(".s_ipt_wr > #kw") # 根据 子元素 定位元素
element.send_keys("自动化测试") # 输入内容
sleep(3) # 强制休眠 3 秒
driver.quit() # 关闭浏览器后代元素
如果元素2是元素1的后代元素(后代元素包含子元素), css selector 选择后代元素的语法是:
/* 一个层级 */
元素1 元素2
/* 多个层级 */
元素1 元素2 元素3 元素4
/* layer1 是 container 的直接子元素 */
#container #layer1
/* inner11 是 layer1 的直接子元素,是 container 的后代元素 */
#layer1 #inner11
#container #inner11
/* span1 是 inner11 的直接子元素,是 layer1 与 container 的后代元素 */
#inner11 #span1
#layer1 #span1
#container #span1实际应用:

# find_element_by_css_selector 的应用:根据 后代元素 定位
from selenium import webdriver # 导入 webdriver 模块
from time import sleep # 导入 sleep 模块,可以使程序强制休眠
driver = webdriver.Chrome() # 调用 Chrome 浏览器
driver.maximize_window() # 窗口最大化
driver.get('https://www.baidu.com/') # 打开 百度
sleep(2) # 强制休眠 2 秒
element = driver.find_element_by_css_selector("#form #kw") # 根据 后代元素 定位元素
element.send_keys("自动化测试") # 输入内容
sleep(3) # 强制休眠 3 秒
driver.quit() # 关闭浏览器根据属性定位
在 HTML 中,id 与 class 是常用的属性,当然,一个标签内可以包含多个属性,同时属性名称也可以是自定义的,如下面的 HTML 代码段所示:
职位订阅
css selector 支持通过任何属性来选择元素,语法是用一个方括号 []。
/* li 标签含有的属性:id */
[id="quick-entrance"]
/* 加上标签名限制 */
li[id="quick-entrance"]
/* a 标签含有的属性:href、data-lg-webtj-_address_id、data-lg-webtj-_seq、rel */
a[href="https://www.lagou.com/s/subscribe.html"]
a[data-lg-webtj-_address_id="1nny"]
a[data-lg-webtj-_seq="1"]
a[rel="nofollow"]另外,css selector 根据属性值定位,还支持模糊匹配:
- 包含关系
*=:a[href*="lagou.com/s/"] - 匹配开头
^=:a[href^="https://www.lagou"] - 匹配结尾
$=:a[href$="lagou.com/s/subscribe.html"]
如果一个元素具有多个属性,css selector 还可以同时限制多个属性:
a[rel="nofollow"][data-lg-webtj-_seq="1"]
实际应用:

# find_element_by_css_selector 的应用:根据 属性 定位
from selenium import webdriver # 导入 webdriver 模块
from time import sleep # 导入 sleep 模块,可以使程序强制休眠
driver = webdriver.Chrome() # 调用 Chrome 浏览器
driver.maximize_window() # 窗口最大化
driver.get('https://www.baidu.com/') # 打开 百度
sleep(2) # 强制休眠 2 秒
element = driver.find_element_by_css_selector("input[id='kw']") # 根据 属性 定位元素
# element = driver.find_element_by_css_selector("input[class='s_ipt']") # 根据 属性 定位元素
# element = driver.find_element_by_css_selector("input[name='wd']") # 根据 属性 定位元素
element.send_keys("自动化测试") # 输入内容
sleep(3) # 强制休眠 3 秒
driver.quit() # 关闭浏览器联合使用
css selector 支持选择语法的联合使用。如下面的 HTML 代码段:
/*
选择语法联合使用
定位目标:版权
*/
/*第一种方法 标签+class+子元素*/
div.footer1 > span.copyright
/*第二种方法 属性+后代元素*/
div[id='bottom'] span[class='copyright']
/*第三种方法 属性+后代元素*/
#bottom .copyright
.footer1 .copyright根据次序选择子节点
父元素的第n个子节点
使用 nth-child(n),可以指定选择父元素的第几个子节点。

注意:
- 这里的排序,是所有的子元素一起排序,而不是按标签分类后再排序
- 下标的开始值是 1
父元素的倒数第n个子节点
使用 nth-last-child(n),可以倒过来,选择的是父元素的倒数第几个子节点。

父元素的第几个某类型的子节点
使用 nth-of-type(n),可以指定选择的元素是父元素的第几个某类型的子节点。
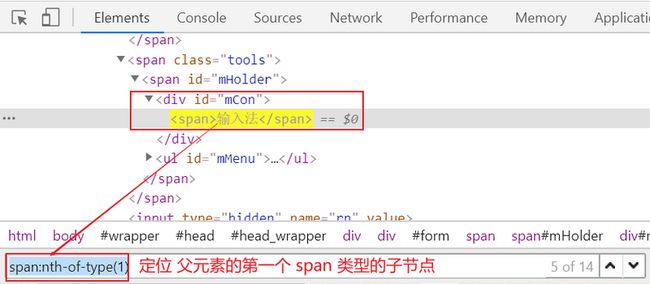
父元素的倒数第几个某类型的子节点
使用 nth-last-of-type(n),可以倒过来, 选择父元素的倒数第几个某类型的子节点。
奇数节点和偶数节点
如果要选择的是父元素的偶数节点,使用 nth-child(even)

如果要选择的是父元素的奇数节点,使用 nth-child(odd)
如果要选择的是父元素的某类型偶数节点,使用 nth-of-type(even)

如果要选择的是父元素的某类型奇数节点,使用 nth-of-type(odd)
根据兄弟节点选择
相邻兄弟节点选择
使用方法:标签类型1 + 标签类型2,两者为兄弟标签(同级标签),定位到紧跟 标签类型1 后的第1个 标签类型2 的元素,如下图所示:
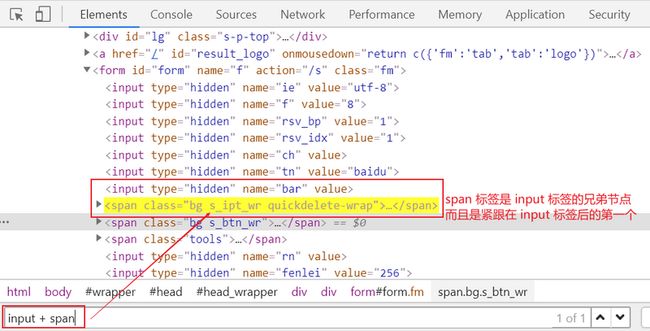
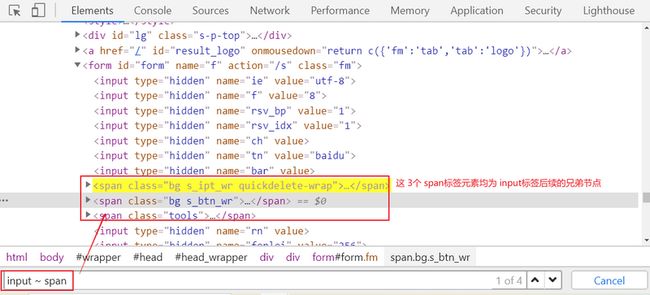
后续所有兄弟节点选择
使用方法:标签类型1 ~ 标签类型2,选择 标签类型1 后续兄弟节点中所有的 标签类型2 的元素,如下图所示:
总结
