SQL引发的惨案
问题的产生:
之前说过COUNT(id)怎么就成慢SQL了?如果没看的可以看下点击这里
看下面两张图对比:(先图,后SQL)
超时SQL:

SELECT ID, ACTIVITY_ID, APPLICANT, NAME, APPLICANT_TYPE
, APPLY_TAG, SYNC_STATUS, EXT, ERP_PIN, PRINCIPAL
, STATUS, CREATED, MODIFIED
FROM gold_pocket_applicant
WHERE 1 = 1
AND ACTIVITY_ID = 706617
AND PRINCIPAL = 'XXX'
AND STATUS = 0
ORDER BY ID DESC
LIMIT 0, 10
这个时候你是否有疑问,这个SQL看起来没什么问题啊?平时不就是这么写的么?是不是因为数据量大导致的查询超时呢?
现在注意看我的截图,上面的查询时间5.296s,而我们通常接触过性能优化的,都知道为了提升数据库性能,以及高并发场景,我们会将0.1s作为数据库响应的标准值,超过0.1s的则会被认为是需要优化的SQL,即为慢SQL.
如果还没有看出原因,那么你需要跟着我的节奏来挖掘知识点了。敲黑板了,,,,迷糊的要醒醒了。。。
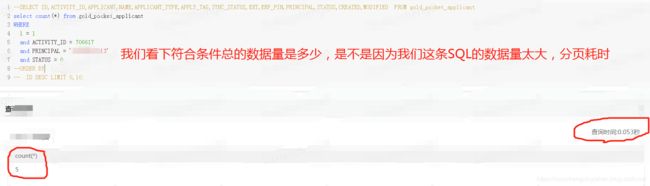
--SELECT ID,ACTIVITY_ID,APPLICANT,NAME,APPLICANT_TYPE,APPLY_TAG,SYNC_STATUS,EXT,ERP_PIN,PRINCIPAL,STATUS,CREATED,MODIFIED FROM gold_pocket_applicant
select count(*) from gold_pocket_applicant
WHERE
1 = 1
and ACTIVITY_ID = 706617
and PRINCIPAL = 'XXXX'
and STATUS = 0
--ORDER BY
-- ID DESC LIMIT 0,10;
补充:如果这个时候你问为什么不用count(id),或者count某个字段的话?出门左拐或者点击这里
对比结果:
很明显的看到的就是真实的,一共5条数据,查询SQL耗时5.296s。而我们几乎认为这条SQL没问题,非常符合我们平时的写作手法,就如同自己写的一样。(这个时候给自己给鄙视的眼神,自己咋就这么low还是当时教我们的老师low?)如果之前可以怪老师,那么现在你不了解,就怪你自己不学习啦。接着跟着我走吧。
开始分析:
从SQL上看符合语法,也能查出问题,SQL没什么问题,那么问题是超时,那么我们需要分析的就是如何优化SQL。
再来背一下基础,如何优化SQL(面试BATJ/TMD必问的问题)
1、索引
- 主键ID索引唯一
- 联合索引(最左原则)
- 三星索引
- 冗余索引和索引限制
2、查询字段全局覆盖
3、一些耗时的not in ,*,like,join等关键字(不会的,点击这里)
4、减少随机IO
- 主键ID有序
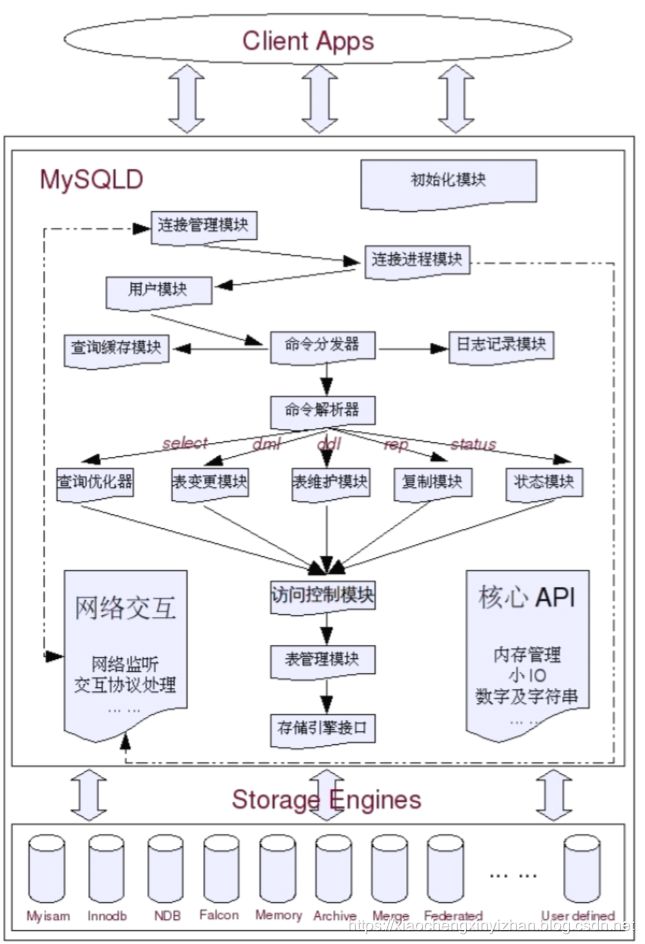
根据上面的流程我们知道我们的SQL是在命令解析器的时候进行处理的。
那么我们拆解下SQL命令看下有什么不同?
SQL解析原理:
这是我们目前的SQL格式:
sql格式:select, where, order by,limit
select xx from xx where xx and xx and xx order by xx desc limit xx;
1、 那么我们知道首先解析的顺序为,锁定了该表,发出信号确认是否有该表,这里没问题。
from xx
2、第一颗星需要取出所有等值谓词中的列,作为索引开头的最开始的列(任意顺序);不只是将等值谓词的列加入索引,它的作用是减少索引片的大小以减少需要扫描的数据行,这里的我们也没有问题。
where xx and xx and xx
3、第二颗星需要将 ORDER BY 列加入索引中;避免排序,减少磁盘 IO 和内存的使用问题是这里么?
order by xx desc
4、第三颗星需要将查询语句剩余的列全部加入到索引中;避免每一个索引对应的数据行都需要进行一次随机 IO 从聚集索引中读取剩余的数据;这里也可以看到没有问题
limit xx
5、过滤因子筛选出符合条件的,这里查询的全部字段,也没有问题,当然这里是可以优化到只要自己需要的字段减少过滤因子的访问IO次数。但是我们这里目前是需要全部字段,所以也不叫问题。
select xx
我们思考下,第二颗星原则,是否是这里存在了问题。我们现在把limit去掉。进行测试下,验证我们的猜想。

不是这里的问题。。。limit的问题么???

是不是发现也不是limit问题?那么是哪里出的问题呢?别卖关子了,不说打你了。。。好的那我们从他这个组合来看下。
发生了什么?
我们来看下这个存储引擎Innodb的原理,都做了什么?
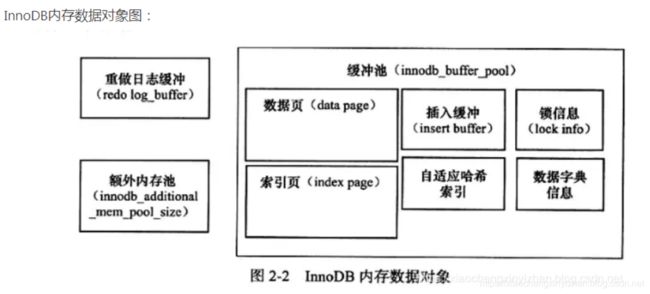
这里提到了数据页和索引页,而我们的要查的字段信息就是在数据页,而key,id就是在索引页。
这里的知识点可以在之前的文章这里看到,点击这里
我们说下查询的流程:
查询有两种方式,一种是索引查询(根据主键或者联合索引),一种是排序查询(order by)。
这里走的是索引查询,那么我们再回忆下之前的文章提到的重点:原文内容点击这里
关键点:
非覆盖索引------》回表
顺序不一致------》两次排序
这个时候如果你细心会发现,咦去掉id主键时间缩短了。哦哦哦这里还有个缓存的概念,如果你查到的是缓存中有的,那么立即返回,会节省一些性能时间。因为上面已经查过一次了。




回表时间,我们可以看到之前是5.296s,现在是3.995s,也就是说回表损耗了1.3s多吧。根据我们之前提到的0.1s,这个时候已经提升了13倍。
那么还有那么多的时间的损耗,两次排序时间。
我们通过索引排序默认是正序排列,order by id desc 是倒序排列。

现在我们已经提升了相比较之前的接近一半的性能。
那么依然离我们的期望值很远,我们希望的是SQL不能超过0.1s。
这个时候我发现了,关键的一点,
那么问题知道了,我们将他去掉。

总结下:重点知识必须背住的
当我们在执行SQL的时候,我们的SQL解析过程(没有记住看上面),
1、锁定表(from)
2、发出信号确认表的存在 (table)
3、根据谓词判断走聚族索引查询还是非聚族索引查询(where )(不会的,点击这里)
4、根据索引还是order by进行排序,如果是一致最好,如果不一致,两次排序(order by)
5、limit 进行结果分页(limit)
6、根据select 过滤因子 进行page页数据的处理。(select)
而我们这里再强调下3/4/6这三个步骤,也是引发这里问题的核心。
首先这个sql千不该万不该利用了两个没有索引的字段进行等值谓词查询,导致了回表查询聚族索引,这里的随机IO消耗时间被该表6656126(现在数据库的行数)个key影响。

可以看到只count(*)我们都消耗了1.619s了。别说我们的mysql哥哥还做了那么多筛选。下图是我们监控超时报告,是之前的数字。

优化SQL,给出解决方案
第一种解决方案:

第二种解决方案:

第三种解决方案:

第四种解决方案:

第五种解决方案:
由于目前还在刷数据验证,没有截图,但是可以给principal加上冗余索引,因为不经常用。但是从索引的限制来考虑其实也不是那么好,因为该SQL用的比较少,所以不建议为了偶尔的用,加上索引。
第六种提示:
千万不能再加上limit分页或者排序。

所以上面需要背住的大家需要背住了哦哦哦!吃晚饭去。。。好饿!