JVM垃圾回收机制(2)--垃圾收集算法
前言
Github:https://github.com/yihonglei/jdk-source-code-reading(java-jvm)
JVM内存结构
JVM类加载机制
JVM内存溢出分析
HotSpot对象创建、内存、访问
JVM垃圾回收机制(1)--如何判定对象可以回收
JVM垃圾回收机制(2)--垃圾收集算法
JVM垃圾回收机制(3)--垃圾收集器
JVM垃圾回收机制(4)--内存分配和回收策略
这里主要分析"标记-清除"算法、"复制"算法、"标记-整理"算法、"分代收集"算法的思想、优缺点和应用场景。
一 标记-清除算法
1、算法思路
"标记-清除"(Mark-Sweep)算法是最基础的收集算法,之所以叫做最基础的收集算法,是因为很多收集算法都是
基于这种该算法思想对其不足进行改进得到的。顾名思义,"标记-清除"算法分为"标记"和"清除"两个阶段实现。
1)标记
首先标记出所有需要回收的对象,要宣告一个对象死亡,至少要经历两次标记过程。
第一次标记
如果对象在进行可达性分析后发现没有与GC Roots相连接的引用链,那它将会被第一次标记
并且进行一次筛选,筛选的条件是此对象是否有必要执行finalize()方法。当对象没有覆盖finalize()方法,
或者finalize()方法已经被虚拟机调用过,虚拟机将这两种情况都视为"没有必要执行"。
如果这个对象被判定为有必要执行finalize()方法,那么这个对象将会被放置在一个叫做F-Queue的
队列中,并在稍后由一个虚拟机自动建立的、低优先级的Finalizer线程去触发这个方法。
第二次标记
GC将对F-Queue队列中的对象进行第二次小规模标记;finalize()方法是对象逃脱死亡的最后一次机会:
如果对象在其finalize()方法中重新与引用链上任何一个对象建立关联,第二次标记时会将其移出"即将回收"的集合;
如果对象没有,也可以认为对象已死,可以回收了;
2)清除
两次标记后,还在"即将回收"集合的对象将被统一回收;
回收执行示意图
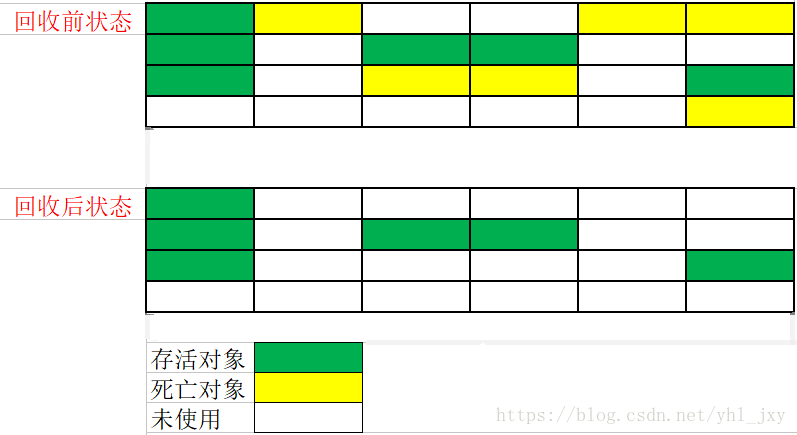
2、算法优点
实现简单。
3、算法缺点
该算法主要有两个缺陷,一个是效率问题,另外一个空间问题。
1)效率问题
标记和清除两个过程的效率都不高。
2)空间问题
标记清除之后会产生大量的不连续的内存碎片,空间碎片太多可能导致以后在程序运行过程中需要分配
较大对象时,无法找到足够的连续内存而不得不提前触发另外一次垃圾收集动作。
4、算法应用场景
针对CMS收集器使用。
二 复制算法
"复制"(Copying)算法的出现,是为了解决"标记-清除"算法的效率问题。
1、算法思路
1)将可用内存按照容量划分为大小相等的两块,每次只使用其中一块。
2)当一块内存用完后,就将还存活着的对象复制到另外一块上面,然后再把已使用多的内存空间一次清掉。
这样使得每次都对整个半区进行内存回收,内存分配时也就不用考虑内存碎片等复杂情况,只要移动堆顶
指针,按顺序分配内存即可,实现简单,运行高效。
复制算法示意图
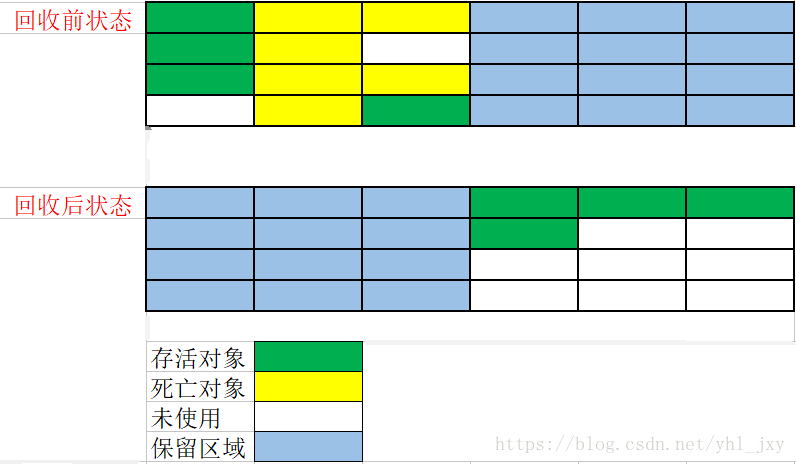
2、算法优点
不会产生内存碎片,内存分配实现简单,高效。
3、算法缺点
1)空间浪费
可用内存缩减为原来的一半,太过浪费(解决:可以改良,不按1:1比例划分);
2)效率随对象存活率升高而变低
当对象存活率较高时,需要进行较多复制操作,效率将会变低;
4、算法应用场景
现在商业虚拟机都采用这种收集算法来回收新生代,用该算法的垃圾收集器比较多,
如Serial收集器、ParNew收集器、Parallel Scavenge收集器、G1(从局部看)。
5、HotSpot对空间浪费的改良算法
1)弱代理论
分代垃圾收集基于弱代理论(weak generational hypothesis),具体描述如下:
.大多数分配了内存的对象并不会存活太长时间,在处于年轻代时就会死掉;
.很少有对象会从老年代变成年轻代;
IBM研究表明:新生代中98%的对象都是"朝生夕死",所以不需要按照1:1的比例来划分内存空间;
2)HotSpot虚拟机新生代内存布局及算法
.将新生代内存分为一块较大的Eden空间和两块较小的Survivor空间;
.每次使用Eden和其中一块Survivor;
.当回收时,将Eden和使用中的Survivor中还存活的对象一次性复制到另外一块Survivor;
.而后清理掉Eden和使用过的Survivor空间;
.然后就就接着使用Eden和那一块Survivor空间,每次重复回收时逻辑;
注意:HotSpot默认虚默认Eden和Survivor的大小比例是8:1,也就是每次新生代中可用内存空间为整个
新生代容量的90%(Eden 80% + 一个Survivor 10%),只有10%的内存会被"浪费"掉。
3)分配担保
如果另一块Survivor空间没有足够空间存放上一次新生代收集下来的存活对象时,
这些对象将直接通过分配担保机制(Handle Promotion)进入老年代;
三 标记-整理算法
复制收集算法在对象存活率较高时就要进行较多的复制操作,效率会降低。更关键的是,如果不想浪费50%
的空间,就需要额外的空间进行分配担保,以应对被使用的内存中所有对象都100%存活的极端情况,所以在
老年代一般不直接选用这种算法。
1、算法思路
"标记-整理"(Mark-Compact)算法的标记过程仍然与"标记-清除"算法一样,但后续步骤不是直接对回收对象进
行清理,而是让所有存活的对象都向一端移动,然后清理掉端边界以外的内存,"标记-整理"算法的执行示意图如下:
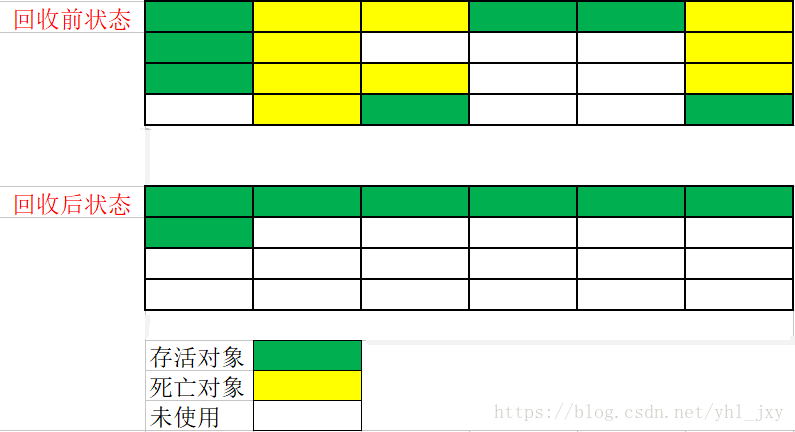
2、算法优点
1)不会像复制算法,效率随对象存活率升高而变低。
老年代特点:
对象存活率高,没有额外的空间可以分配担保;所以老年代一般不能直接选用复制算法;而选用标记-整理算法;
2)不会像标记-清除算法,产生内存碎片因为清除前,进行了整理,存活对象都集中到空间一侧;
3、算法缺点
主要是效率问题:除像标记-清除算法的标记过程外,还多了需要整理的过程,效率更低;
4、算法应用场景
很多垃圾收集器采用这种算法来回收老年代;如Serial Old收集器、G1(从整体看);
四 分代收集算法
"分代收集"(Generational Collection)算法结合不同的收集算法处理不同区域。
1、算法思路
当前虚拟机的垃圾收集都采用"分代收集"算法,这种算法并没有什么新的思想,只是根据对象的
存活申请周期的不同将内存划分为几块,这样就可以根据各个年代的特点采用最适当的收集算法。
java堆分为新生代和老年代。
1)新生代
在新生代中,每次垃圾收集都发现有大批量对象死去,只有少量存活,就选用复制算法,
只需要付出少量的存活对象的复制成本就可以完成收集。
2)老年代
在老年代中对象存活率高、没有额外空间对它进行分配担保,就必须使用"标记-清除"或"标记-整理"算法
来进行回收。
HotSpot虚拟机对新生代和老年代一般的内存划分示意图:

2、算法优点
可以根据各个年代的特点采用最适当的收集算法;
3、算法缺点
仍然不能控制每次垃圾收集的时间;
4、算法应用场景
目前几乎所有商业虚拟机的垃圾收集器都采用分代收集算法;如HotSpot虚拟机中全部垃圾收集器:
Serial、ParNew、Parallel Scavenge、Serial Old、Parallel Old、CMS、G1(也保留);
参考文献
《深入理解Java虚拟机》 (第二版) 周志明 著;