Android面试重难点(更新:2020.7.16)
现在分为Android篇和Java篇、还有一些其他人收集的面试题网页地址。关于笔试用 牛客网就可以了
一.Android篇
1.源码分析
Glide源码分析
https://juejin.im/post/5f0ec887e51d45349917c614#heading-0
2.事件分发流程
https://blog.csdn.net/guolin_blog/article/details/9097463
View
如果view可以点击,而且onTouchListener不为空,则执行onTouch函数,返回true,否则执行onTouchEvent,返回其值
public boolean dispatchTouchEvent(MotionEvent event) {
if (mOnTouchListener != null && (mViewFlags & ENABLED_MASK) == ENABLED &&
mOnTouchListener.onTouch(this, event)) {
return true;
}
return onTouchEvent(event);
}
在手指抬起时,如果OnClickListener不为空,则执行onClick,返回true
public boolean onTouchEvent(MotionEvent event) {
switch (event.getAction()) {
case MotionEvent.ACTION_UP:
performClick();
}
public boolean performClick() {
if (mOnClickListener != null) {
mOnClickListener.onClick(this);
return true;
}
return false;
}
3.事件分发冲突解决
http://blog.csdn.net/gdutxiaoxu/article/details/52939127
在VIewGroup里通过onInterceptTouchEvent来控制事件的分发,
在View里则是通过getParent().requestDisallowInterceptTouchEvent(true)来禁止上级ViewGroup拦截事件
因为在ViewGroup里dispatchTouchEvent有以下这段代码
//allowInterceptTouchEvent由requestDisallowInterceptTouchEvent设置
if(!onInterceptTouchEvent(event)||disallowInterceptTouchEvent){
child.dispatchOnTouchEvent(event))
}
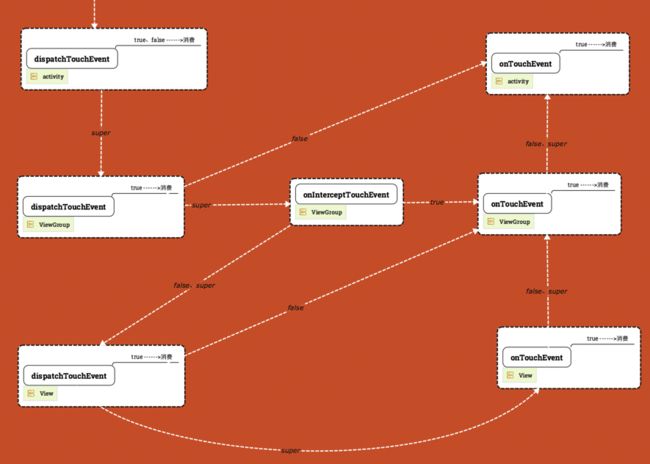
4.Handler的运行机制
https://blog.csdn.net/z979451341/article/details/66472693
Handler:负责发送消息,和处理消息,还可以将Runable对象当做Message发送和运行。
Message:消息,传递信息的载体。它持有Handler,而且还有内部变量Message next,可以作为一个链表的节点使用。
MessageQueue:队列数据结构,先进先出,存放Message。由Looper创建给Handler。
Looper:发动机,不断的从MessageQueue中取出Message给Handler处理。每个线程最多一个Looper,Thread与Looper组成键值对,作为ThreadLocal保持。
5.View绘制
View在Activity中显示出来,要经历测量、布局和绘制三个步骤,分别对应三个动作:measure、layout和draw。
测量:onMeasure()决定View的大小;
布局:onLayout()决定View在ViewGroup中的位置;
绘制:onDraw()决定绘制这个View。
自定义View的步骤:
1. 自定义View的属性;
2. 在View的构造方法中获得自定义的属性;
3. 重写onMeasure(); --> 并不是必须的,大部分的时候还需要覆写
4. 重写onDraw();
6.动画详尽教程
https://github.com/OCNYang/Android-Animation-Set
7.Android 打包过程
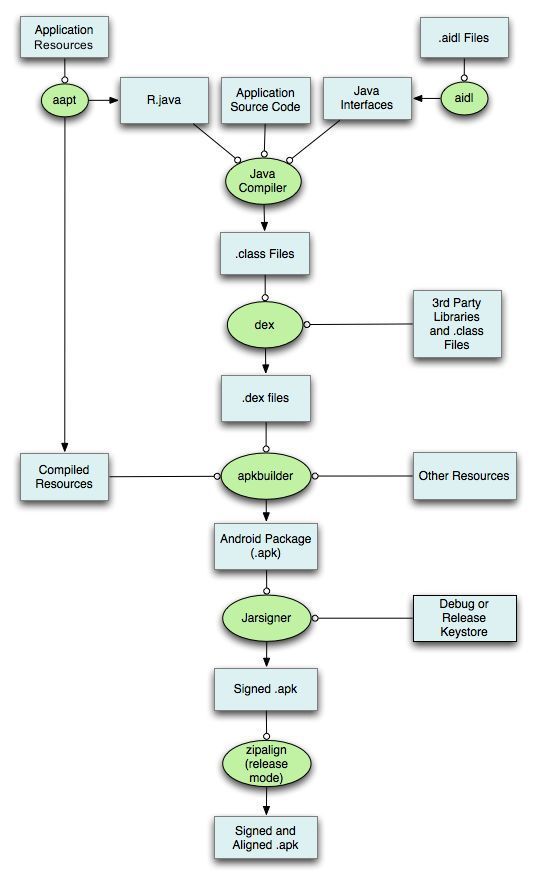
- 通过AAPT工具进行资源文件(包括AndroidManifest.xml、布局文件、各种xml资源等)的打包,生成R.java文件。
- 通过AIDL工具处理AIDL文件,生成相应的Java文件。
- 通过Javac工具编译项目源码,生成Class文件。
- 通过DX工具将所有的Class文件转换成DEX文件,该过程主要完成Java字节码转换成Dalvik字节码,压缩常量池以及清除冗余信息等工作。
- 通过ApkBuilder工具将资源文件、DEX文件打包生成APK文件。
- 利用KeyStore对生成的APK文件进行签名。
- 如果是正式版的APK,还会利用ZipAlign工具进行对齐处理,对齐的过程就是将APK文件中所有的资源文件举例文件的起始距离都偏移4字节的整数倍,这样通过内存映射访问APK文件 的速度会更快。
8.APK的安装流程如下所示:
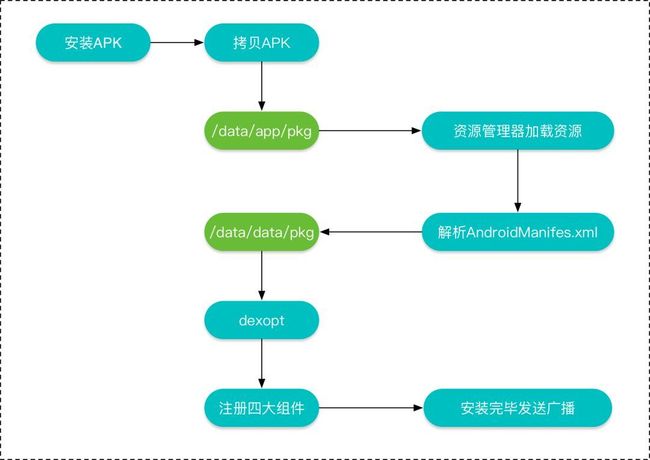
复制APK到/data/app目录下,解压并扫描安装包。
- 资源管理器解析APK里的资源文件。
- 解析AndroidManifest文件,并在/data/data/目录下创建对应的应用数据目录。
- 然后对dex文件进行优化,并保存在dalvik-cache目录下。
- 将AndroidManifest文件解析出的四大组件信息注册到PackageManagerService中。
- 安装完成后,发送广播。
9.当点击一个应用图标以后,都发生了什么,描述一下这个过程?
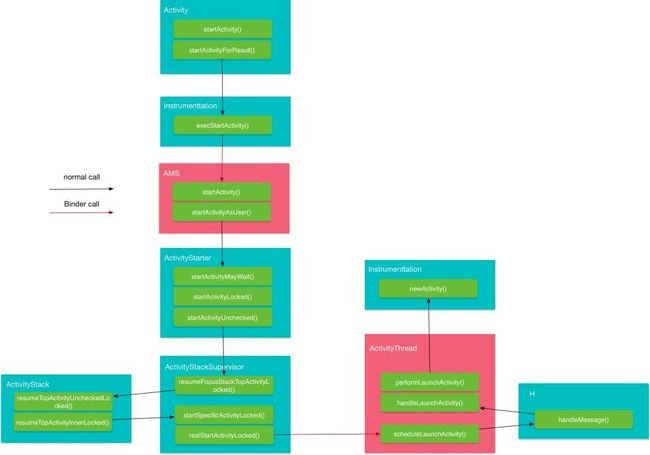
整个流程涉及的主要角色有:
- Instrumentation: 监控应用与系统相关的交互行为。
- AMS:组件管理调度中心,什么都不干,但是什么都管。
- ActivityStarter:Activity启动的控制器,处理Intent与Flag对Activity启动的影响,具体说来有:1 寻找符合启动条件的Activity,如果有多个,让用户选择;2 校验启动参数的合法性;3 返回int参数,代表Activity是否启动成功。
- ActivityStackSupervisior:这个类的作用你从它的名字就可以看出来,它用来管理任务栈。
- ActivityStack:用来管理任务栈里的Activity。
- ActivityThread:最终干活的人,是ActivityThread的内部类,Activity、Service、BroadcastReceiver的启动、切换、调度等各种操作都在这个类里完成。
注:这里单独提一下ActivityStackSupervisior,这是高版本才有的类,它用来管理多个ActivityStack,早期的版本只有一个ActivityStack对应着手机屏幕,后来高版本支持多屏以后,就有了多个ActivityStack,于是就引入了ActivityStackSupervisior用来管理多个ActivityStack。
整个流程主要涉及四个进程:
- 调用者进程,如果是在桌面启动应用就是Launcher应用进程。
- ActivityManagerService等所在的System Server进程,该进程主要运行着系统服务组件。
- Zygote进程,该进程主要用来fork新进程。
- 新启动的应用进程,该进程就是用来承载应用运行的进程了,它也是应用的主线程(新创建的进程就是主线程),处理组件生命周期、界面绘制等相关事情。
有了以上的理解,整个流程可以概括如下:
- 点击桌面应用图标,Launcher进程将启动Activity(MainActivity)的请求以Binder的方式发送给了AMS。
- AMS接收到启动请求后,交付ActivityStarter处理Intent和Flag等信息,然后再交给ActivityStackSupervisior/ActivityStack 处理Activity进栈相关流程。同时以Socket方式请求Zygote进程fork新进程。
- Zygote接收到新进程创建请求后fork出新进程。
- 在新进程里创建ActivityThread对象,新创建的进程就是应用的主线程,在主线程里开启Looper消息循环,开始处理创建Activity。
- ActivityThread利用ClassLoader去加载Activity、创建Activity实例,并回调Activity的onCreate()方法。这样便完成了Activity的启动。
10、drawable文件夹
http://blog.csdn.net/jbscuthua/article/details/51345371
:一部xxhdpi的手机照图片都是先到drawable-xxhdpi的文件夹中寻找的,如果没有就向更高分辨率的文件夹里找,再没有就开始向低分辨率的文件夹里找。所以顺序大概是依次是drawable-xxhdpi ->drawable-xxxhdpi ->drawable-xhdpi -> drawable-hdpi -> drawable-mdpi -> drawable-ldpi。当手机在更高分辨率的文件夹如drawable-xxxhdpi中找到图片时,判断这个图片原来设计是用于drawable-xxxhdpi的,这样的图片对于drawable-xxhdpi来说太大,所以手机会自动将它缩小。同理,当在一个低分辨率的文件夹中发现图片,就会将图片放大。至于缩小放大的倍数可由原文的这个表查找到
| dpi范围 | 密度 |
|---|---|
| 0dpi ~ 120dpi | ldpi |
| 120dpi ~ 160dpi | mdpi |
| 160dpi ~ 240dpi | hdpi |
| 240dpi ~ 320dpi | xhdpi |
| 320dpi ~ 480dpi | xxhdpi |
| 480dpi ~ 640dpi | xxxhdpi |
根据dpi范围的最大值计算倍数,如xhdpi的手机在xxxhdpi的文件夹中找到图片,那么就会将图片缩小到320/640即0.5倍的大小。如果是在mdpi文件夹中发现图片,将放大到320/160即2倍的大小。
最后,因为听说一般的公司不会有很多不同分辨率的图片,所以我们一般将图片放在高分辨率的文件夹下,避免在大分辨率手机上图片被放的太大,占用太多的内存导致OOM。当然小分辨率手机的图片会被缩小,但是显然缩小比放大要让人更容易接受。但是因为市场上xxxhdpi的手机比较少,所以我们一般放在xhdpi的文件夹中就可以了。
11.ANR
ANR源码解释
https://mp.weixin.qq.com/s/4w202K0WnNrazmEHd6grQA
https://www.jianshu.com/p/7fd95bc2a55c
那么哪些场景会造成ANR呢?
- Service Timeout:服务在20s内未执行完成;
- BroadcastQueue Timeout:比如前台广播在10s内未执行完成
- inputDispatching Timeout: 输入事件分发超时5s,包括按键分发事件的超时。
都知道避免ANR,但该如何分析,定位,解决?
https://mp.weixin.qq.com/s/T6EkbLleyPE76FNRkaaJ2w
12.OOM
http://blog.csdn.net/hudfang/article/details/5178199
没有内存了
1.数据库的cursor没有关闭。
2.构造adapter没有使用缓存contentview。
3.调用registerReceiver()后未调用unregisterReceiver().
4.未关闭InputStream/OutputStream。
5.Bitmap使用后未调用recycle()。(Android5.0 自动回收)
6.Context泄漏。
7.static关键字等。
13.Binder
https://www.jianshu.com/p/c7bcb4c96b38
Server是服务器,Client是客户终端,ServiceManager是域名服务器(DNS),驱动是路由器。
14.性能优化
http://blog.csdn.net/gs12software/article/details/51173392
太多了,就不打字了
15.JAVA虚拟机、Dalvik虚拟机和ART虚拟机简要对比
http://blog.csdn.net/jason0539/article/details/50440669
16.内存泄露
https://mp.weixin.qq.com/s/f7wItMhL_xfVUrkCWIHdKg
-
-
常见引发内存泄露原因主要有:
-
-
集合类
-
Static关键字修饰的成员变量
-
非静态内部类 / 匿名类
-
资源对象使用后未关闭
说到内存泄露,就不得不提到内存溢出,这两个比较容易混淆的概念,我们来分析一下。
-
内存泄露:程序在向系统申请分配内存空间后(new),在使用完毕后未释放。结果导致一直占据该内存单元,我们和程序都无法再使用该内存单元,直到程序结束,这是内存泄露。
-
内存溢出:程序向系统申请的内存空间超出了系统能给的。
大量的内存泄露会导致内存溢出(oom)。
非静态内部类 & 匿名内部类都默认持有 外部类的引用
在java中所有非静态的对象都会持有当前类的强引用,而静态对象则只会持有当前类的弱引用。
二.java篇
关于JVM,你必须知道的那些玩意儿
https://juejin.im/post/5edde98de51d457b3c1e6922
1.类的加载机制 类加载器 Java内存模型 GC回收机制
https://juejin.im/post/5edde98de51d457b3c1e6922
2,ArrayBlockingQueue
https://www.hchstudio.cn/article/2019/bf19/
整体是一个队列,先入先出,
由Lock实现的消费者和生产者模式
当 让一个元素入队时,如果当前队列挤满了,就堵塞当前线程,等待队列有空余的空间再入队,当让一个元素出队,如果当前队列没有元素就堵塞当前队列,等待队列里有元素时,再出队。
3,String,StringBuilder,StringBuffer三者的区别
首先说运行速度,或者说是执行速度,在这方面运行速度快慢为:StringBuilder > StringBuffer > String
在线程安全上,StringBuilder是线程不安全的,而StringBuffer是线程安全的
4,ArrayList和LinkedList区别
ArrayList,是顺序存储,元素在内存的地址是连续的,是实现了基于动态数组的数据结构,
LinkedList,是随机存储,每个元素持有下一个元素地址,是基于链表的数据结构;
对于随机访问get和set,ArrayList要优于LinkedList,因为LinkedList要移动指针;
对于添加和删除操作add和remove,当数据比较多时,LinkedList要比ArrayList快,因为ArrayList要移动数据。
5,进程和线程的区别?
(1)进程是资源的分配和调度的一个独立单元,而线程是CPU调度的基本单元
(2)同一个进程中可以包括多个线程,并且线程共享整个进程的资源(寄存器、堆栈、上下文),一个进程至少包括一个线程。
(3)进程的创建调用fork或者vfork,而线程的创建调用pthread_create,进程结束后它拥有的所有线程都将销毁,而线程的结束不会影响同个进程中的其他线程的结束
6.死锁
http://blog.csdn.net/jyy305/article/details/70077042
死锁产生的四个必要条件
- 互斥条件:资源是独占的且排他使用,进程互斥使用资源,即任意时刻一个资源只能给一个进程使用,其他进程若申请一个资源,而该资源被另一进程占有时,则申请者等待直到资源被占有者释放。
- 不可剥夺条件:进程所获得的资源在未使用完毕之前,不被其他进程强行剥夺,而只能由获得该资源的进程资源释放。
- 请求和保持条件:进程每次申请它所需要的一部分资源,在申请新的资源的同时,继续占用已分配到的资源。
- 循环等待条件
7.Java 引用,栈 堆 的理解
http://blog.csdn.net/chenyongtu110/article/details/49339783
1、栈: 存放基本数据类型及对象变量的引用,对象本身不存放于栈中而是存放于堆中
1)、基础类型 byte (8位)、boolean (1位)、char (16位)、int (32位)、short (16位)、float (32位)、double (64位)、long (64位)
2)、java代码作用域中定义一个变量时,则java就在栈中为这个变量分配内存空间,当该变量退出该作用域时,java会自动释放该变量所占的空间
2、堆: new操作符的对象
1)、new创建的对象和数组
2)、在堆中分配的内存,由Java虚拟机的自动垃圾回收器来管理
3、静态域: static定义的静态成员变量
4、常量池: 存放常量
1 String a = "hello"; //先在栈中创建一个对String类的对象引用变量a,然后通过符号引用去字符串常量池里找有没有"hello",如果没有,则将"hello"存放进字符串常量池 ,并令a指向"hello",如果已经有"hello"则直接将a指向"hello" --> 产生1个对象及1个引用
2 String b = "hello"; //先在栈中创建一个对String类的对象引用变量b,然后通过符号引用去字符串常量池里找有没有"hello",因为之前在常量池中已经有"hello",所以直接将b指向"hello" --> 因为不需要在常量池产生"hello",所以只是在栈中产生1个引用
3 String newA = new String("hello"); //先在栈中创建一个对String类的对象引用变量newA,然后new()操作会在heap堆中产生一个新的对象"hello",并将newA指向堆中的"hello",同时检查String pool常量池中是否有对象"hello",如果没有也产生一个对象"hello",如果有则不产生,因为这里之前已经在常量池中产生过了,所以 --> 只需要产生1个对象及1个引用
4 String newB = new String("hello"); //因为new每次都会保证在heap堆内存中产生新的对象,并将栈中的引用指向对应的堆中的地址,所以此语句同上一条的处理 String a = "hello"; //先在栈中创建一个对String类的对象引用变量a,然后通过符号引用去字符串常量池里找有没有"hello",如果没有,则将"hello"存放进字符串常量池 ,并令a指向"hello",如果已经有"hello"则直接将a指向"hello" --> 产生1个对象及1个引用
2 String b = "hello"; //先在栈中创建一个对String类的对象引用变量b,然后通过符号引用去字符串常量池里找有没有"hello",因为之前在常量池中已经有"hello",所以直接将b指向"hello" --> 因为不需要在常量池产生"hello",所以只是在栈中产生1个引用
3 String newA = new String("hello"); //先在栈中创建一个对String类的对象引用变量newA,然后new()操作会在heap堆中产生一个新的对象"hello",并将newA指向堆中的"hello",同时检查String pool常量池中是否有对象"hello",如果没有也产生一个对象"hello",如果有则不产生,因为这里之前已经在常量池中产生过了,所以 --> 只需要产生1个对象及1个引用
4 String newB = new String("hello"); //因为new每次都会保证在heap堆内存中产生新的对象,并将栈中的引用指向对应的堆中的地址,所以此语句同上一条的处理
8,==、equals与hashCode的区别
Object类中默认的实现方式是 : return this == obj 。那就是说,只有this 和 obj引用同一个对象,才会返回true。
而我们往往需要用equals来判断 2个对象是否等价,而非验证他们的唯一性。这样我们在实现自己的类时,就要重写equals.
重写equals,也必须重写hashCode。具体后面介绍。
第一:在某个运行时期间,只要对象的(字段的)变化不会影响equals方法的决策结果,那么,在这个期间,无论调用多少次hashCode,都必须返回同一个散列码。
第二:通过equals调用返回true 的2个对象的hashCode一定一样。
第三:通过equasl返回false 的2个对象的散列码不需要不同,也就是他们的hashCode方法的返回值允许出现相同的情况。
总结一句话:等价的(调用equals返回true)对象必须产生相同的散列码。不等价的对象,不要求产生的散列码不相同。
9.Java对象的四种引用类型
强引用、软引用、弱引用、虚引用
https://blog.csdn.net/m0_37700275/article/details/79820814
11.Thread
interrupt,调用该方法的线程的状态将被置为"中断"状态。注意:线程中断仅仅是设置线程的中断状态位,不会停止线程。需要用户自己去监视线程的状态为并做处理。支持线程中断的方法。中断状态将会根据传入的ClearInterrupted参数值确定是否重置”。所以,静态方法interrupted将会清除中断状态(传入的参数ClearInterrupted为true),而实例方法isInterrupted则不会(传入的参数ClearInterrupted为false)。
join() 的作用
让主线程等待子线程结束之后才能继续运行。
在Java当中,线程通常都有五种状态,创建、就绪、运行、阻塞和死亡。
第一是创建状态。在生成线程对象,并没有调用该对象的start方法,这是线程处于创建状态。
第二是就绪状态。当调用了线程对象的start方法之后,该线程就进入了就绪状态,但是此时线程调度程序还没有把该线程设置为当前线程,此时处于就绪状态。在线程运行之后,从等待或者睡眠中回来之后,也会处于就绪状态。
第三是运行状态。线程调度程序将处于就绪状态的线程设置为当前线程,此时线程就进入了运行状态,开始运行run函数当中的代码。
第四是阻塞状态。线程正在运行的时候,被暂停,通常是为了等待某个时间的发生(比如说某项资源就绪)之后再继续运行。sleep,suspend,wait等方法都可以导致线程阻塞。
第五是死亡状态。如果一个线程的run方法执行结束或者调用stop方法后,该线程就会死亡。对于已经死亡的线程,无法再使用start方法令其进入就绪。
12.ReentrantLock
https://www.jianshu.com/p/96c89e6e7e90
1)可中断锁:两个线程使用一个变量,一个线程使用中,另一个线程等着,而可以让另一个线程不等了。
2)公平锁:几个线程等着用一个变量,如果是开了公平锁,会先给等着最久的线程使用。
3)读写锁:对一个变量开读锁,多个线程都可以同时读取到最新的值,开了写锁,多个线程必须排队进行写操作。
13.HashMap的工作原理
https://blog.csdn.net/qq_27093465/article/details/52209789
https://blog.csdn.net/qq_27093465/article/details/52209814
HashMap本身就是一个动态数组,也就是ArrayList,然后这个arraylist每个元素里放的是一个LinkedList,这个LinkedList放的是entry对象(属性:key,value,hash,next),通过hash%arraylistlength算出entry在arraylist里的位置,如果原来的arraylist元素里又称为bucket桶里linkedlist有了一个entry对象,他会把新的entry放在linkedlist的首部,get获取键值对的时候,会通过hash计算entry在哪个桶,然后通过key的equels方法判断哪个entry对象是他要的。
红黑树
对于HashMap的查找操作来说,如果数据足够分散,则查找效率是非常高的(时间复杂度O(1))。但是再优秀的hash算法也没法保证不发生哈希冲突,而且随着数据量的增大冲突会越发严重。由于在1.8之前是将冲突节点连成一个链表,所以在最坏情况下查找的时间复杂度会变为O(N),红黑树的引入就是为了优化这一部分,当一个桶中的元素个数大于TREEIFY_THRESHOLD时,HashMap会将链表转变为红黑树结构,从而将操作的复杂度降为O(logN)。
红黑树有5个原则:
1,每个节点是红色或者黑色的
2,根节点必须是黑色的
3,每个叶子节点都是黑色的空节点(NIL节点),即叶子节点不存储数据
4,红色节点的两个子节点必须都是黑色的(即路径中不能存在两个连续的红色节点)
5,从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
14.HashTable
https://blog.csdn.net/jinhuoxingkong/article/details/52022999
Hashtable和HashMap到底有哪些不同呢
(1)基类不同:HashTable基于Dictionary类,而HashMap是基于AbstractMap。Dictionary是什么?它是任何可将键映射到相应值的类的抽象父类,而AbstractMap是基于Map接口的骨干实现,它以最大限度地减少实现此接口所需的工作。
(2)null不同:HashMap可以允许存在一个为null的key和任意个为null的value,但是HashTable中的key和value都不允许为null。
(3)线程安全:HashMap时单线程安全的,Hashtable是多线程安全的。
(4)遍历不同:HashMap仅支持Iterator的遍历方式,Hashtable支持Iterator和Enumeration两种遍历方式。
15.LinkedList
https://blog.csdn.net/gongchuangsu/article/details/51527042
LinkedList是一个继承于AbstractSequentialList的双向链表。它也可以被当作堆栈、队列或双端队列进行操作。LinkedList实现List接口,能进行队列操作。LinkedList实现Deque接口,即能将LinkedList当作双端队列使用。ArrayList底层是由数组支持,而LinkedList是由双向链表实现的,其中的每个对象包含数据的同时还包含指向链表中前一个与后一个元素的引用。
17.Integer和int有什么区别
https://blog.csdn.net/login_sonata/article/details/71001851
18数据结构
https://blog.csdn.net/ztchun/article/details/52017290
List特点:元素有放入顺序,元素可重复
Map特点:元素按键值对存储,无放入顺序
Set特点:元素无放入顺序,元素不可重复(注意:元素虽然无放入顺序,但是元素在set中的位置是有该元素的HashCode决定的,其位置其实是固定的)
List接口有三个实现类:LinkedList,ArrayList,Vector
LinkedList:底层基于链表实现,链表内存是散乱的,每一个元素存储本身内存地址的同时还存储下一个元素的地址。链表增删快,查找慢
ArrayList和Vector的区别:ArrayList是非线程安全的,效率高;Vector是基于线程安全的,效率低
Set接口有两个实现类:HashSet(底层由HashMap实现),LinkedHashSet
SortedSet接口有一个实现类:TreeSet(底层由平衡二叉树实现)
Query接口有一个实现类:LinkList
Map接口有三个实现类:HashMap,HashTable,LinkeHashMap
HashMap非线程安全,高效,支持null;HashTable线程安全,低效,不支持null
SortedMap有一个实现类:TreeMap
其实最主要的是,list是用来处理序列的,而set是用来处理集的。Map是知道的,存储的是键值对
set 一般无序不重复.map kv 结构 list 有序
网络篇
全面了解HTTP和HTTPS(开发人员必备)
https://mp.weixin.qq.com/s/adZC0N5Fd4X9FjxUrdlS1w
其他人收集的面试题网页地址
https://github.com/guoxiaoxing/android-interview
https://github.com/AweiLoveAndroid/CommonDevKnowledge