(干货)Ai音箱和Linux音频驱动小谈
一、音频基础
(1)采样率(samplerate)
采样就是把模拟信号数字化的过程,不仅仅是音频需要采样,所有的模拟信号都需要通过采样转换为可以用0101来表示的数字信号,示意图如下所示:
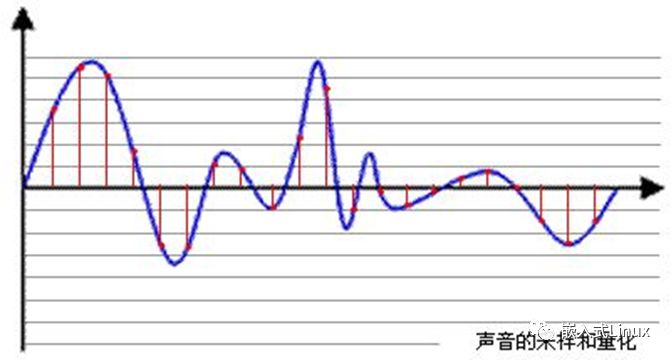
蓝色代表模拟音频信号,红色的点代表采样得到的量化数值。采样频率越高,红色的间隔就越密集,记录这一段音频信号所用的数据量就越大,同时音频质量也就越高。
根据奈奎斯特理论,采样频率只要不低于音频信号最高频率的两倍,就可以无损失地还原原始的声音。
通常人耳能听到频率范围大约在20Hz~20kHz之间的声音,为了保证声音不失真,采样频率应在40kHz以上。常用的音频采样频率有:8kHz、11.025kHz、22.05kHz、16kHz、37.8kHz、44.1kHz、48kHz、96kHz、192kHz等。
(2)量化精度(位宽)
上图中,每一个红色的采样点,都需要用一个数值来表示大小,这个数值的数据类型大小可以是:4bit、8bit、16bit、32bit等等,位数越多,表示得就越精细,声音质量自然就越好,当然,数据量也会成倍增大。
常见的位宽是:8bit 或者 16bit
(3)声道数(channels)
由于音频的采集和播放是可以叠加的,因此,可以同时从多个音频源采集声音,并分别输出到不同的扬声器,故声道数一般表示声音录制时的音源数量或回放时相应的扬声器数量。单声道(Mono)和双声道(Stereo)比较常见,顾名思义,前者的声道数为1,后者为2
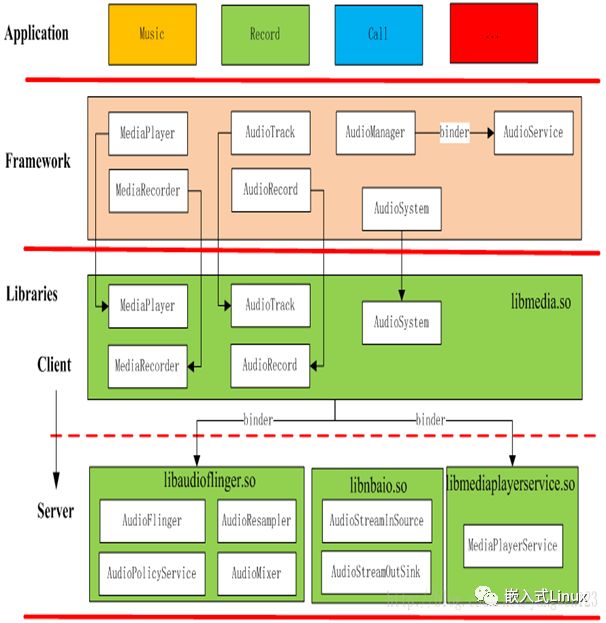
二、Android Audio框架
Android用的是C/S的框架,就是一个client,一个service,中间是一个HAL作为统一的接口,HAL往下就会到tinyalsa,tinyalsa是alsa的裁剪版本,后面对应的就是驱动层了。

三、I2S接口介绍
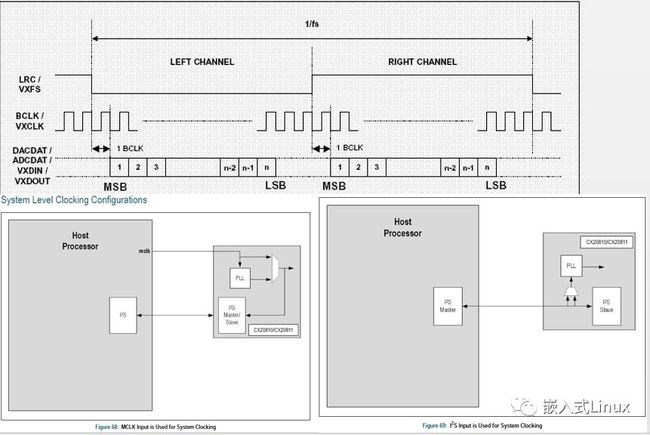
I2S总线标准:I2S(Inter-IC Sound Bus)是飞利浦公司为数字音频设备之间的音频数据传输而制定的一种总线标准。在飞利浦公司的I2S标准中,既规定了硬件接口规范,也规定了数字音频数据的格式。I2S有3个主要信号:
串行时钟 SCLK:也叫做位时钟BCLK,即对应数字音频的每一位数据,SCLK的频率=2×采样频率×采样位数 ,现在问题来了,有人会问这些东西到底是什么意思呢?其实,I2S一般是传输立体声,有两个声道channel,采样频率指得是采样数率,多久去采集一个点,每个点是几个bit组成。
帧时钟LRCK:用于切换左右声道的数据,LRCK为“0”表示正在传输的是左声道的数据,为“1”表示正在传输的是右声道的数据。LRCLK == FS,就是采样频率
串行数据SDATA:就是用二进制补码表示的音频数据,有时为了使系统间能够更好的同步,还需要另外传输一个信号MCLK,称为主时钟,也叫系统时钟(System Clock),是采样频率的256或384倍
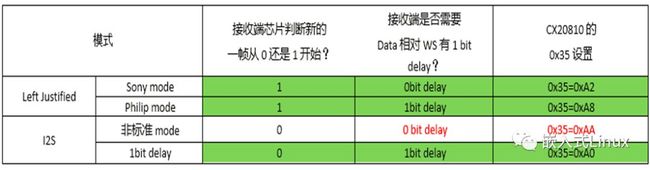
I2S不同的标准介绍:I2S主要是针对ADC和主控,如果ADC设置的I2S标准和主控的不一致,那么录音肯定是要出问题的,正常使用的时候,会涉及1bit delay,大家在量I2S波形的时候也可以看出来
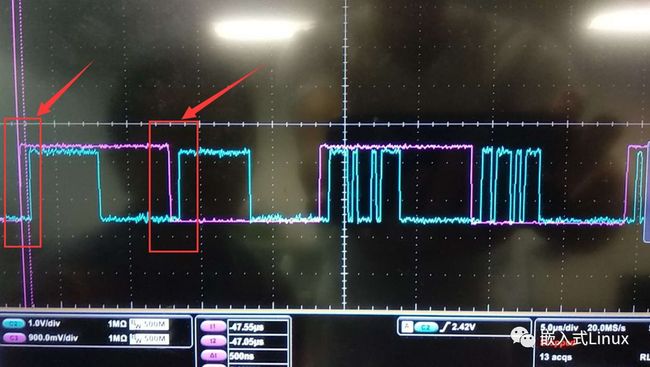
BCLK计算:BCLK = LRCLKxbitsxch,Ch 默认是2,我们现在用的是8ch的数据,但是我们用的是4个数据线,这时候计算的时候ch还是用2来计算
BCLK = 16K x 32bitsx2ch = 1.024M
注意:我们在使用CX20810 ADC芯片的时候,CX20810现在是市面上做AI音响用的主流芯片,像叮咚叮咚就是用这个,里面介绍一个TDM 模式,这个也是一个I2S的标准,不过这个标准是一个DATA线传8ch的数据
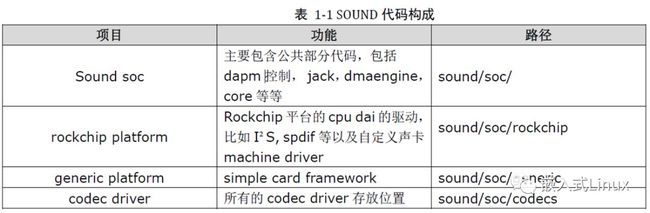
四、TINYALSA子系统
(1)代码介绍
目前linux中主流的音频体系结构是ALSA(Advanced Linux Sound Architecture),ALSA在内核驱动层提供了alsa-driver,在应用层提供了alsa-lib,应用程序只需要调用alsa-lib(libtinyalsa.so)提供的API就可以完成对底层硬件的操作。说的这么好,但是Android中没有使用标准的ALSA,而是一个ALSA的简化版叫做tinyalsa。Android中使用tinyalsa控制管理所有模式的音频通路,我们也可以使用tinyalsa提供的工具进行查看、调试。
tinycap.c 实现录音相关代码 tinycap
Tinyplay.c 实现放音相关代码 tinyplay
Pcm.c 与驱动层alsa-driver调用接口,为audio_hw提供api接口
Tinymix 查看和设置混音器 tinymix
Tinypcminfo.c 查看声卡信息tinypcminfo
(2)音频帧(frame)
这个概念在应用开发中非常重要,网上很多文章都没有专门介绍这个概念。
音频跟视频很不一样,视频每一帧就是一张图像,而从上面的正玄波可以看出,音频数据是流式的,本身没有明确的一帧帧的概念,在实际的应用中,为了音频算法处理/传输的方便,一般约定俗成取2.5ms~60ms为单位的数据量为一帧音频。
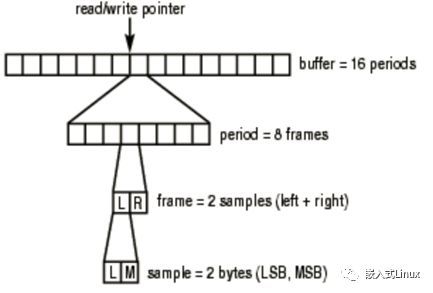
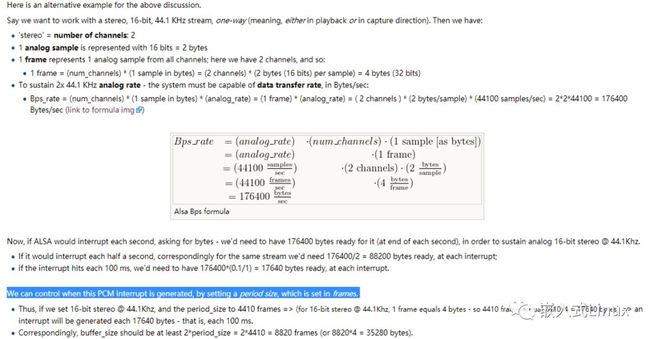
这个时间被称之为“采样时间”,其长度没有特别的标准,它是根据编解码器和具体应用的需求来决定的,我们可以计算一下一帧音频帧的大小:
假设某音频信号是采样率为8kHz、双通道、位宽为16bit,20ms一帧,则一帧音频数据的大小为:
int size = 8000 x 2 x 16bit x 0.02s = 5120 bit = 640 byte
音频帧总结
period(周期):硬件中断间的间隔时间。它表示输入延时。
声卡接口中有一个指针来指示声卡硬件缓存区中当前的读写位置。只要接口在运行,这个指针将循环地指向缓存区中的某个位置。
frame size = sizeof(one sample) * nChannels
alsa中配置的缓存(buffer)和周期(size)大小在runtime中是以帧(frames)形式存储的。
period_bytes = pcm_format_to_bits 用来计算一个帧有多少bits,实际应用的时候经常用到
下面有个老外的讲的音频帧,很多解释都是从这里翻译来的,大家自行体味一下
https://www.alsa-project.org/main/index.php/FramesPeriods
五、CODEC介绍
(1)专用术语
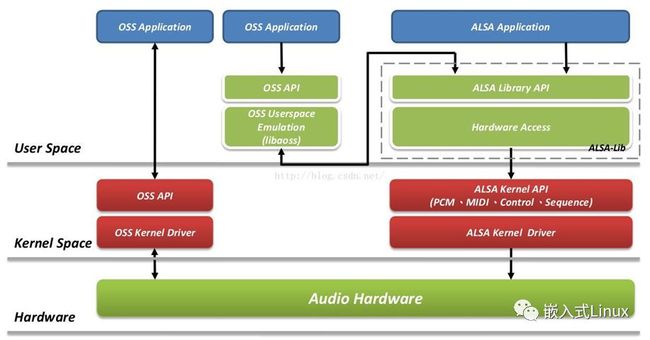
ASLA - Advanced Sound Linux Architecture
OSS - 以前的Linux音频体系结构,被ASLA取代并兼容
Codec - Coder/Decoder
I2S/PCM/AC97 - Codec与CPU间音频的通信协议/接口/总线
DAI - Digital Audio Interface 其实就是I2S/PCM/AC97
DAC - Digit to Analog Conversion
ADC - Analog to Digit Conversion
DSP - Digital Signal Processor
Mixer - 混音器,将来自不同通道的几种音频模拟信号混合成一种模拟信号
Mute - 消音,屏蔽信号通道
PCM - Pulse Code Modulation 脉冲调制编码,一种从音频模拟信号转换成数字信号的技术,区别于PCM音频通信协议
SSI - Serial Sound Interface
DAPM - Dynamic Audio Power Management
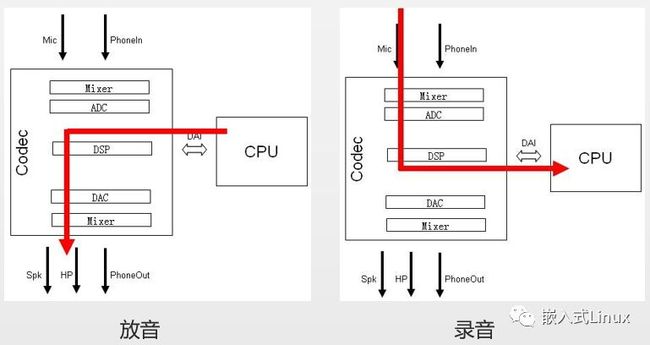
(2)放音录音框图
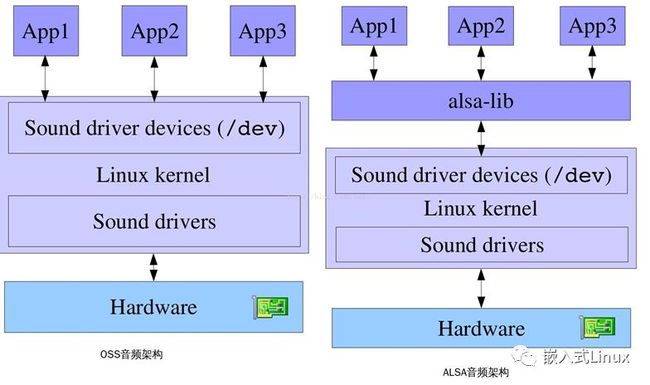
(3) OSS和ALSA比较
a.OSS的优点(对用户来说)
b.OSS的优点(对开发者来说)于使用。支持用户空间的声音驱动。
c.ALSA的优点
https://blog.csdn.net/longwang155069/article/details/53256751
d.调用接口
alsa是多了一个alsa-lib接口,但是OSS是直接操作设备文件的,这个差异还是很大的,不过幸运的是,alsa出来后为了兼容oss,也是做了一些修改。
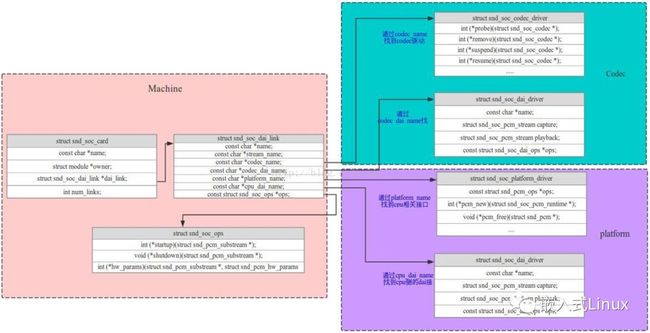
(4)ASOC介绍
ASOC--ALSA System on Chip (即ALSA在片选系统上的应用),是建立在标准ALSA驱动层上,为了更好地支持嵌入式处理器和移动设备中的音频Codec的一套软件体系。在ASoc出现之前,内核对于SoC中的音频已经有部分的支持,不过会有一些局限性
Codec类: Codec即编解码芯片的驱动,此Codec驱动是和平台无关,包含的功能有: 音频的控制接口,音频读写IO接口,以及DAPM的定义等。如果需要的话,此Codec类可以在BT,FM,MODEM模块中不做修改的使用。因此Codec就是一个可重复使用的模块,同一个Codec在不同的SOC中可以使用。对应ak7755.c
Platform类: 可以理解为某款SOC平台,平台驱动中包括音频DMA引擎驱动,数字接口驱动(I2S, AC97, PCM)以及该平台相关的任何音频DSP驱动。同样此Platform也可以重用,在不同的Machine中可以直接重复使用。
Machine类: Machine可以理解为是一个桥梁,用于在Codec和Platform之间建立联系。此Machine指定了该机器使用那个Platform,那个Codec,最终会通过Machine建立两者之间的联系。
https://blog.csdn.net/longwang155069/article/details/53321464
https://wiki.archlinux.org/index.php/Advanced_Linux_Sound_Architecture_(%E7%AE%80%E4%BD%93%E4%B8%AD%E6%96%87)
https://www.linuxjournal.com/article/6735
六、音频相关调试技巧
在调试录音和放音的时候,我们先使用tinyalsa的调试命令来进行调试,比如tinycap、tinyplay、tinypcminfo
Proc下的音频调试介绍:
https://alsa.opensrc.org/Proc_asound_documentation#The_.2Fproc.2Fasound.2Foss.2F_directory
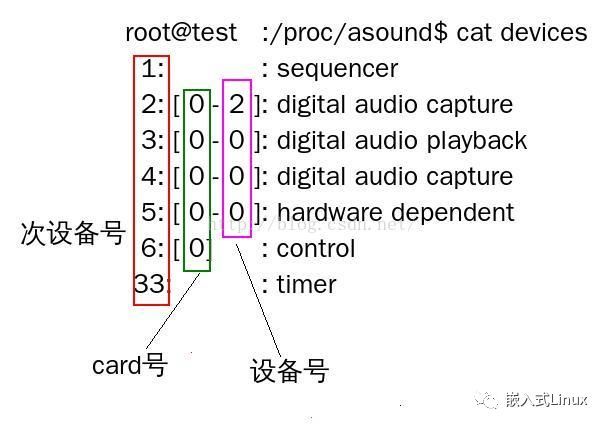
(1)通过命令确认声卡是否注册成功
rk3399_mid:/ $ ls /proc/asound/
card0 cards hwdep rockchipak7755c timers
card1 devices pcm rockchipi2sdmic version
$ ls /dev/snd/
(2)xrun debug
我们在调试音频的时候,难免会遇到underrun或者overrun,出现此两者情况时内核会打印log协助问题分析,Menuconfig中需要开启如下选项:
[*] Advanced Linux Sound Architecture --->
[*] Debug [*] More verbose debug
[*] Enable PCM ring buffer overrun/underrun debugging
然后在对应声卡/proc/asound/card0/xrun中写入相应的值,值如下:
#define XRUN_DEBUG_BASIC (1<<0)
#define XRUN_DEBUG_STACK (1<<1) /* dump also stack */
#define XRUN_DEBUG_JIFFIESCHECK (1<<2) /* do jiffies check */
比如 echo 1 > xrun或者echo 3 > xrun 或者 echo 7 > xrun
开启所有debug信息检测。
Xrun主要是读写速度不一致引起的音频录音播放异常,之前遇到一个这样的问题是因为DMA引起的,在注册声卡设备时会申请一个period_size,这个size是不能随意更改大小的,所以大家在写代码的时候要注意。
七、AI智能音响核心点
这部分讲的没一点内容都是非常核心的,直接影响到AI音箱的整体效果,包括声源定位,回声消除,有很多人反馈为什么我的音箱声源定位不好,为什么我的回声消除效果很差,我们就要从下面几个问题点去排查
(1)、音频部分
1、做到有效采样16bits 32bits,(失真、截幅)、软件端对多通道数据可以编码
多通道数据采样同步,采样率同步,采样时钟同步,比如不能出现录音的时候出现失真情况。
2、录音的采样深度理论是越大是越好的,采样频率要跟算法部分确认好,讯飞要求的是16K的采样音频送给他们的算法
3、播放不能有失真,电声部分一定要通过严格的测试要求,整个扫频阶段都不能出现问题,比如不能出现播放高频的时候发现喇叭有低频的声音此类问题
(2)、结构部分
1、MIC开孔深度、孔径、构型符合标准;
2、内部音腔隔离,密封性能;
3、结构震动隔离;震音非常关键,测试的时候会发现,装上机构后的回声消除比没有结构时候差很多,大多是由于增加了结构,震音结构影响很大。
4、喇叭与MIC的距离,不能太近;
(3)、回声消除注意
作用:
抑制产品(喇叭)本身发出的声音,使得产品在播放音频时依然可以进行语音交互;
注意点:
1、需要接参考信号,信号采样需要符合要求;
做到有效采样
使用硬采集方案
参考信号采样尽量与mic采集到的回声同步,至少不晚于回声;
2、结构方面需要特别注意;
内部音腔隔离
震动隔离
喇叭与MIC的相对位置;
3、硬件选型方面需要注意;
4、整个采样系统中的延时要稳定;
彩蛋:
•ASR(automaticspeech recognition)把语音转换成文字,AI算法说的是自我学习算法,所以学习是一个非常复杂的过程,下面是一个链接,有开源的一些模型,感兴趣的可以自己拿去学习
https://github.com/kaldi-asr/kaldi
https://shiweipku.gitbooks.io/chinese-doc-of-kaldi/content/index.html

添加极客助手微信,加入技术交流群


长按,扫码,关注公众号