SparkStreaming 详解
原文链接:https://www.toutiao.com/i6854493461903901197/
本文主要从以下几个方面介绍SparkStreaming:
一、SparkStreaming是什么
二、SparkStreaming支持的业务场景
三、SparkStreaming的相关概念
四、DStream介绍
五、SparkStreaming的机制
六、SparkStreaming的Demo
一、SparkStreaming是什么
在讲sparkStreaming是什么之前首先讲一下为什么要有SparkStreaming。
Hadoop 的 MapReduce 及 Spark SQL 等只能进行离线计算,无法满足实时性要求较高的业务 需求,例如实时推荐、实时网站性能分析等,流式计算可以解决这些问题。目前有三种比较 常用的流式计算框架,它们分别是 Storm,Spark Streaming 和 fink。它们三个的区别如下:
1、SparkStreaming绝对谈不上比Storm、Flink优秀。这两个框架在实时计算领域中,都很优秀,只是擅长的细分场景并不相同。
2、Spark Streaming在吞吐量上要比Storm优秀。
3、Storm在实时延迟度上,比SparkStreaming就好多了,前者是纯实时,后者是准实时。而且,Storm的事务机制、健壮性/容错性、动态调整并行度等特性,都要比Spark
Streaming更加优秀。
4、Spark Streaming,有一点是Storm绝对比不上的,就是:它位于Spark整个生态技术栈中,因此Spark Streaming可以和Spark Core、SparkSQL、Spark Graphx无缝整合,换句话说,我们可以对实时处理出来的中间数据,立即在程序中无缝进行延迟批处理、交互式查询等操作。这个特点大大增强了Spark
1、SparkStreaming绝对谈不上比Storm、Flink优秀。这两个框架在实时计算领域中,都很优秀,只是擅长的细分场景并不相同。
2、Spark Streaming在吞吐量上要比Storm优秀。
3、Storm在实时延迟度上,比SparkStreaming就好多了,前者是纯实时,后者是准实时。而且,Storm的事务机制、健壮性/容错性、动态调整并行度等特性,都要比Spark
Streaming更加优秀。
4、Spark Streaming,有一点是Storm绝对比不上的,就是:它位于Spark整个生态技术栈中,因此Spark Streaming可以和Spark Core、SparkSQL、Spark Graphx无缝整合,换句话说,我们可以对实时处理出来的中间数据,立即在程序中无缝进行延迟批处理、交互式查询等操作。这个特点大大增强了Spark
Streaming的优势和功能。流处理:
实时流处理:(Storm 、Flink)
每一条记录,都会提交一次计算作业。
每一条记录,一般都被称为一个事件
准实时流处理:(Spark Streaming)
介于批处理和实时流处理之间,是一个较小的时间间隔的数据处理
其底层原理还是基于SparkCore来处理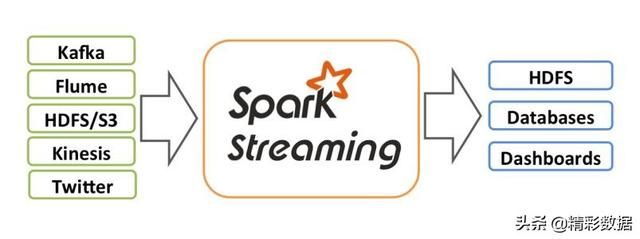
SparkStreaming是一个基于Spark Core之上的实时计算框架,可以从很多数据源消费数据并对数据进行处理.Spark Streaming 是Spark核心API的一个扩展,可以实现高吞吐量的、具备容错机制的实时流数据的处理。支持从多种数据源获取数据,包括Kafk、Flume、Twitter、ZeroMQ、Kinesis 以及TCP sockets,从数据源获取数据之后,可以使用诸如map、reduce、join和window等高级函数进行复杂算法的处理。最后还可以将处理结果存储到文件系统,数据库和现场仪表盘。在“One Stack rule them all”的基础上,还可以使用Spark的其他子框架,如集群学习、图计算等,对流数据进行处理。
二、SparkStreaming支持的业务场景
1、无状态操作:只关注当前的DStream中的实时数据,例如 只对当前DStream中的数据做正确性校验
2、有状态操作:对有状态的DStream进行操作时,需要依赖之前的数据 例如 统计网站各个模块总的访问量
3、窗口操作:对指定时间段范围内的DStream数据进行操作,例如 需要统计一天之内网站各个模块的访问数量
三、SparkStreaming的相关概念
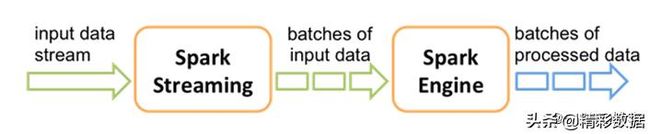
接收实时输入数据流,然后将数据拆分成多个batch,比如每收集1秒的数据封装为一个batch,然后将每个batch交给Spark的计算引擎进行处理,最后会生产出一个结果数据流,其中的数据,也是由一个一个的batch所组成的。
离散流DStream:这是spark streaming对内部持续的实时数据流的抽象描述,即我们处理的一个实时数据,在sparkstreaming中对应一个DStream实例。
批数据:这是化整为零的第一步,将实时数据抽象,以时间片为单位进行分批,将流处理转化为时间片,数据的批处理,随着持续时间的推移,这些处理结果就形成了对应的结果数据流。
时间片或批处时间间隔:人为地对流数据进行定量的标准,以时间片作为我们拆分流数据的依据。一个时间片的数据对应一个 RDD 实例。
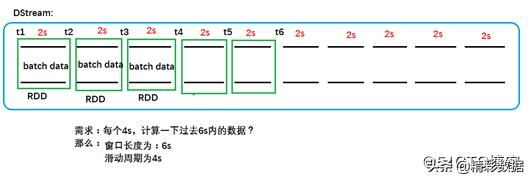
窗口长度:一个窗口覆盖的数据流的时间长度,必须是批处理时间间隔的倍数。
滑动周期:前一个窗口到后一个窗口所经过的时间长度,必须是批处理时间间隔的倍数。
InputDStream:一个 InputDStream 是一个特殊的 DStream,表示第一次被加载到实时数据流中的原始数据。间片的数据对应一个 RDD 实例。
四、DStream介绍
Discretized Stream 是 Spark Streaming 的基础抽象,代表持续性的数据流和经过各种 Spark 原 语操作后的结果数据流。在内部实现上,DStream 是一系列连续的 RDD 来表示。对DStream进行操作实际就是对对RDD进行操作。DStream可以理解为RDD的工厂,该DStream里面生产的都是相同的业务(RDD的逻辑一样,只是对应的数据不同)。DStream 是 连续数据的离散化表示,DStream 中每个离散片段都是一个 RDD,DStream 可以变换成另一 个 DStream。DStream与DStream之间也存在依赖关系,在一个固定的时间点,对存在依赖关系的DStream对应的RDD也存在依赖关系。每个一个固定时间点,其实生产了一个小的DAG,周期性的将小DAG提交到spark集群中进行运行。
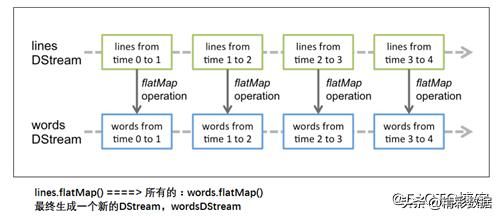
对DStream应用的算子,比如flatmap,其实在底层都会被翻译为DStream中 每个RDD的操作
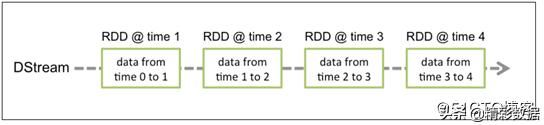
DStream中的每个RDD都包括了一个时间段内的数据
DStream对数据的操作也是按照RDD为单位来进行的:
DStream上的原语与RDD类似,分为:Transformations(转换)和Output Operations(输出,类似于action)。
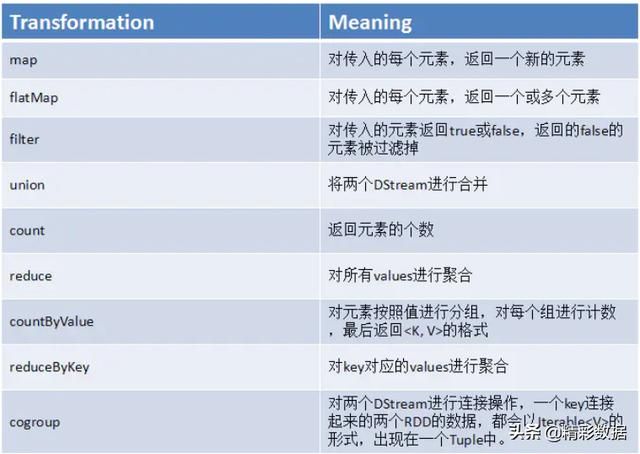
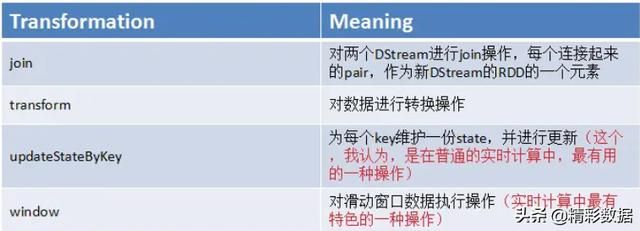
Transformations操作中有几个极为重要的操作:updateStateByKey()、transform()、window()、foreachRDD()
五、SparkStreaming的机制
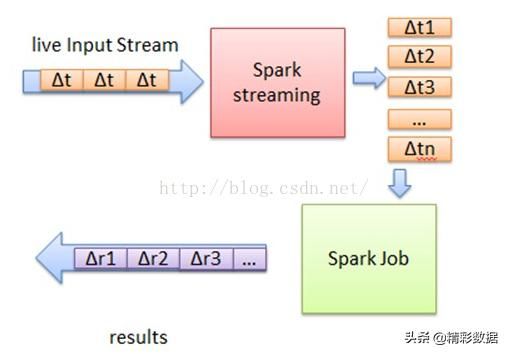
Spark Streaming中,会有一个接收器组件Receiver,作为一个长期运行的task跑在一个Executor上。Receiver接收外部的数据流形成input DStream
DStream会被按照时间间隔划分成一批一批的RDD(准实时性/近实时性(不是100%的实时)
Spark应用程序就使用Spark API处理这些RDD,并且批量返回RDD操作的结果。
六、SparkStreaming的Demo
1、读取scoket数据
package xxx
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
/**
* 需要在192.168.247.4 主机上先运行 nc -lk 8888命令
*/
object StreamingWordCount {
def main(args: Array[String]): Unit = {
// 离线任务是创建sparkContext
// 实时计算,用StreamingContext
val conf: SparkConf = new SparkConf().setAppName("StreamingWordCount").setMaster("local[*]")
val context = new SparkContext(conf)
// StreamingContext是对SparkContext的包装,包了一层实时的功能
// 第二个参数是小批次产生的时间间隔
val streamContext = new StreamingContext(context, Seconds(5))
// 有了streamContext就可以创建SparkStreaming的抽象DSteam
// 从一个socket端口中读取数据
val lines: ReceiverInputDStream[String] = streamContext.socketTextStream("192.168.247.4", 8888)
// 对DStream进行操作,这个抽象类似于RDD
val words: DStream[String] = lines.flatMap(line => {
line.split(" ")
})
val wordAndOne: DStream[(String, Int)] = words.map(word => {
(word, 1)
})
val reduced: DStream[(String, Int)] = wordAndOne.reduceByKey((a, b) => {
a + b
})
// action操作
reduced.print()
// 启动sparkstreaming程序
streamContext.start()
// 等待优雅的退出
streamContext.awaitTermination()
}
}
2、读取kafka中的数据
package xxx
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* 读取kafka中的数据
*/
object KafkaWordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("KafkaWordCount").setMaster("local[*]")
val ssc = new StreamingContext(conf, Seconds(5))
val zkQuorum = "slave2:2181,slave3:2181,slave4:2181" // zookeeper集群
val groupId = "g1" // kafka的消费者分组
val topic = Map[String, Int]("test1" -> 1) // topic
//创建DStream,需要KafkaDStream
val data: ReceiverInputDStream[(String, String)] = KafkaUtils.createStream(ssc, zkQuorum, groupId, topic, StorageLevel.MEMORY_AND_DISK_SER)
//对数据进行处理
//Kafak的ReceiverInputDStream[(String, String)]里面装的是一个元组(key是写入的key,value是实际写入的内容)
val lines: DStream[String] = data.map(_._2)
//对DSteam进行操作,操作这个抽象(代理,描述),就像操作一个本地的集合一样,类似于RDD
val words: DStream[String] = lines.flatMap(_.split(" "))
val wordAndOne: DStream[(String, Int)] = words.map((_, 1))
val reduced: DStream[(String, Int)] = wordAndOne.reduceByKey(_+_)
//打印结果(Action)
reduced.print()
//启动sparksteaming程序
ssc.start()
//等待优雅的退出
ssc.awaitTermination()
}
}3、在上面两个Demo中,实现wordcount程序时,word的计数是针对本次时间片的计数。
例如,0-5的数据:aa aa bb b 5-10秒的数据:aa b 那么这两次的计数结果为:0-5:(aa,2)(bb,1) (b,1) 5-10:(aa,1)(b,1).
并没有将之前时间片段的的计数结果累加起来。
可以累加之前时间片的程序:
package xxx
import org.apache.spark.{HashPartitioner, SparkConf}
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
*读取kafka数据,累加历史结果
*/
object StatefulKafkaWordCount {
/**
* 迭代器中的第一个参数:聚合的key,就是单词
* 迭代器中的第二个参数:当前批次产生批次该单词在每一个分区出现的次数
* 迭代器中的第三个参数:初始值或累加的中间结果
*/
val updateFunc = (iter: Iterator[(String, Seq[Int], Option[Int])]) => {
iter.map{ case(x, y, z) => (x, y.sum + z.getOrElse(0))}
}
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("StatefulKafkaWordCount").setMaster("local[*]")
val ssc = new StreamingContext(conf, Seconds(10))
//如果要使用课更新历史数据(累加),那么就要把终结结果保存起来
ssc.checkpoint("./ck")
val zkQuorum = "slave2:2181,slave3:2181,slave4:2181"
val groupId = "g100"
val topic = Map[String, Int]("test1" -> 1)
//创建DStream,需要KafkaDStream
val data: ReceiverInputDStream[(String, String)] = KafkaUtils.createStream(ssc, zkQuorum, groupId, topic)
//对数据进行处理
//Kafak的ReceiverInputDStream[(String, String)]里面装的是一个元组(key是写入的key,value是实际写入的内容)
val lines: DStream[String] = data.map(_._2)
//对DSteam进行操作,你操作这个抽象(代理,描述),就像操作一个本地的集合一样
val words: DStream[String] = lines.flatMap(_.split(" "))
val wordAndOne: DStream[(String, Int)] = words.map((_, 1))
// 累加的聚合,更新函数,分区器,接下来是否还使用这个分区器
val reduced: DStream[(String, Int)] = wordAndOne.updateStateByKey(updateFunc, new HashPartitioner(ssc.sparkContext.defaultParallelism), true)
//打印结果(Action)
reduced.print()
//启动sparksteaming程序
ssc.start()
//等待优雅的退出
ssc.awaitTermination()
}
}