CVPR2019顶会论文解读:3DN: 3D Deformation Network
虚拟现实和增强现实中的应用程序要求快速创建和轻松访问大量3D模型。 解决此需求的有效方法是基于参照物,例如非常容易获取的2D图像,对现有3D模型进行编辑或变形。 给定这样的源3D模型和目标(可以是2D图像,3D模型或作为深度扫描获取的点云),我们引入了3DN,这是使源模型变形以类似于源3D的端到端网络。 目标。 我们的方法会推断每个顶点的偏移位移,同时保持源模型的网格连接固定。 我们提出了一种训练策略,该策略使用一种新颖的可微分运算,网格采样运算符,在网格密度不同的源模型和目标模型之间推广我们的方法。 网格采样运算符可以无缝集成到网络中,以处理具有不同拓扑的网格。 定性和定量结果表明,与基于学习的基于3D形状的最新学习方法相比,我们的方法可产生更高质量的结果。
1.介绍:
用于编辑3D模型以匹配参考目标的传统方法依赖于基于优化的方法,该方法要么需要用户交互[32],要么依赖于分段3D模型组件数据库的存在[9]。 3D深度学习方法[17、2、31、28、10]的发展激发了更有效的替代方法来处理3D数据。 实际上,在过去几年中,已经提出了使用深度学习进行3D形状生成的多种方法。 但是,由于神经网络中网格和网格连接性的表示仍然是开放的,因此许多方法都使用体素[33、5、37、29、24、30、34、27]或基于点的表示[3]。
最近一些使用网格表示的方法对固定拓扑进行了假设[7,25],这限制了其方法的灵活性。
本文介绍了3DN,这是一种3D变形网络,可根据目标2D图像,3D网格或3D点云(例如,使用深度传感器获取)使源3D网格变形。 与先前的工作假设所有示例均使用固定的拓扑网格不同,我们利用源模型的网格结构。 这意味着我们可以使用任何现有的高质量网格模型来生成新模型。 具体来说,给定任何源网格和目标,我们的网络会估计顶点位移矢量(3D偏移)以使源模型变形,同时保持其网格连通性。此外,在变形过程中明确保留了许多人造对象表现出的全局几何约束,以增强输出模型的合理性。
我们的网络首先从源和目标输入中提取全局特征。 这些输入到偏移解码器以估计每个顶点的偏移。 由于获取源与目标之间的地面真实对应关系非常困难,因此我们使用无监督损失函数(例如,倒角和地球移动器的距离)来计算变形源模型与目标的相似度。 测量网格之间相似性的一个困难是不同模型之间网格密度的变化。 想象一个仅由4个顶点和2个三角形表示的平面,而不是一组密集的平面三角形。 即使这些网格表示相同的形状,基于顶点的相似度计算也可能会产生较大的误差。 为了克服这个问题,我们采用点云中间表示。 具体来说,我们在变形的源网格和目标模型上都采样了一组点,并确定了所得点集之间的损失。 该措施引入了可微分的网格采样算子,该算子以可微分的方式将特征(例如,偏移量)从顶点传播到点。
我们评估我们针对各种目标的方法,包括3D形状数据集以及真实图像和局部点扫描。 定性和定量比较表明,与以前的基于学习的方法相比,我们的网络可以学习执行更高质量的网格变形。 我们还展示了几种应用,例如形状插值。 总之,我们的贡献如下:
•我们提出了一个端到端网络来预测3D变形。 通过保持源的网格拓扑固定并保留诸如对称性之类的属性,我们能够生成合理的变形网格。
•我们建议使用可区分的网格采样算子,以使我们的网络体系结构能够适应源模型和目标模型中变化的网格密度。
2.方法
给定源3D网格和目标模型(表示为2D图像或3D模型),我们的目标是使源网格变形,使其与目标模型尽可能接近。 我们的变形模型使源网格的三角形拓扑保持固定,并且仅更新顶点位置。 我们引入了端到端3D变形网络(3DN),以预测源网格的每个顶点位移。
我们将源网格表示为S =(V,E),其中V∈RNV×3是顶点的(x,y,z)位置,E∈ZNE×3是三角形的集合,并使用 顶点的骰子。 NV和NE分别表示顶点和三角形的数量。 目标模型T是H×W×3图像或3D模型。 在T是3D模型的情况下,我们将其表示为3D点T∈RNT×3的集合,其中NT表示T中的点数。
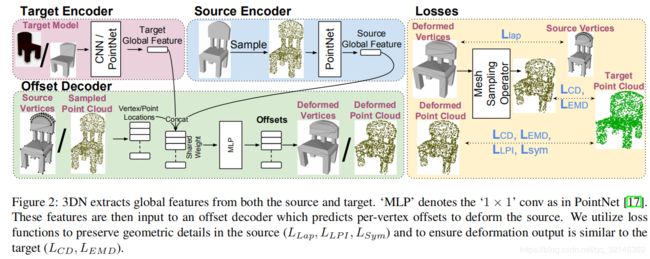
如图所示,3DN以S和T作为输入和输出每个顶点的位移,即偏移量O∈RNV×3。
最终变形的网格为S0 =(V 0,E),其中V 0 = V +O。此外,当我们用采样点云替换输入源顶点时,可以扩展3DN以产生每点位移。 3DN由 target and a source encoder组成,目标编码器分别从源模型和目标模型中提取全局特征,偏移解码器则利用这些特征来估计形状变形。 接下来,我们将详细描述每个组件。
偏移解码器的架构类似于PointNet分段网络[17]。 但是,与原始的PointNet体系结构将全局形状特征向量与每个点的特征连接在一起不同,我们将原始点的位置连接到全局形状特征。 我们发现这可以更好地捕获源中的顶点和点位置分布,并产生有效的变形结果。 我们的网络可以灵活地处理具有不同数量顶点的源模型和目标模型。
那么p的位置是

其中w1 + w2 + w3 = 1是p的重心坐标。 给定原始顶点的任何典型特征,在我们的情况下,每个顶点的偏移量ov1,ov2,ov3,p的偏移量为
![]()
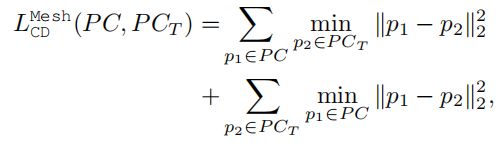
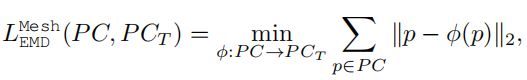

![]()
鉴于上述所有损失,我们训练3DN的综合损失为
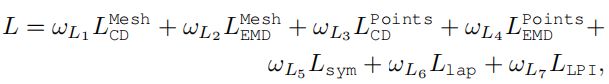
3.实验
在本节中,我们对从3D目标模型以及单视图重构中的形状重构进行定性和定量比较。 我们还对我们的方法进行了消融研究,以证明偏移解码器架构的有效性以及所采用的不同损耗函数。 最后,我们提供了几个应用程序来演示我们方法的灵活性。 在补充材料中可以找到更多的定性结果和实施细节。
数据集。 在我们的实验中,我们使用ShapeNet Core数据集[1],其中包括13个形状类别和正式的训练/测试拆分。 对于潜在的源网格,我们使用与[11]中相同的模型模板集。 该模板集中每个类别有30种形状。 在训练基于2D图像的目标模型时,我们使用Choy等人提供的渲染视图。 [2]。我们在所有类别中训练了一个网络。
模板选择。 为了采样3DN的源和焦油获取模型对,我们训练了一个基于PointNet的自动编码器来学习3D形状的嵌入。 具体来说,我们将每个3D形状表示为一组统一采样的点。 编码器将这些点编码为特征向量,而解码器根据该特征向量预测点的位置。给定由编码器提取的特征组成的嵌入,对于每个目标模型候选者,我们选择该嵌入中最接近的邻居作为源模型。 源模型是从上述模板集中选择的。 在此过程中不需要类别标签信息,但是,在同一类别中查询最近的邻居。 给定目标2D图像进行测试时,如果未给出所需的源模型,则使用点集生成网络PSGN [3]生成初始点云,并在我们的嵌入中使用其最近的邻居作为源模型。
评估指标。 给定一个源模型和目标模型对(S,T),我们在定量评估中利用三个指标来比较变形输出S0和焦油得到T:1)在S0上采样的点云之间的倒角距离(CD) 和T,2)地球移动者的距离(EMD)在S0和T上采样的点云之间,3)S0和T的实体素化之间的联合相交(IoU)。我们将方法的输出和以前的工作标准化 在计算这些指标之前将其放入一个单位多维数据集。 我们还通过提供大量定性示例来评估我们的结果在视觉上的合理性。
比较我们将我们的方法与最新的重建方法进行比较。 具体而言,我们比较了三类方法:1)基于学习的表面生成,2)基于学习的变形预测以及3)传统的表面重建方法。 我们想指出的是,我们要解决的问题与表面生成方法根本不同。 即使使源网格开始看起来似乎是有利的,但眼前的问题并不容易,因为我们的目标不仅是生成类似于目标的网格,而且还保留源的某些属性。 此外,我们的源网格来自一组固定的模板,每个类别仅包含30个模型
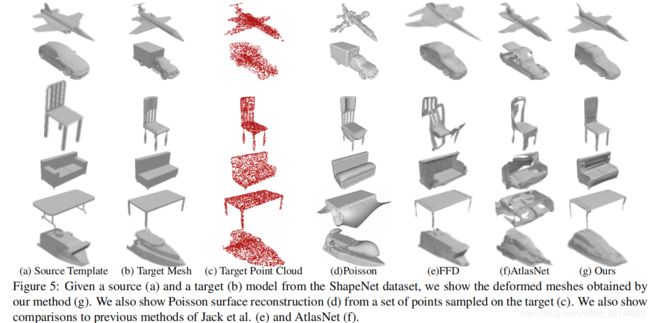
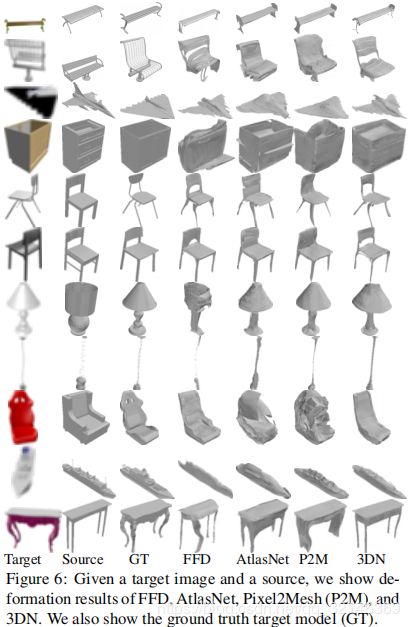


4.总结
我们介绍了3DN,这是一种用于网格变形的端到端网络体系结构。 给定源网格和目标可以采用2D图像,3D网格或3D点云的形式,3DN通过推断每个顶点的位移来变形源,同时保持源网格的连接性固定。 我们将我们的方法与基于最近学习的表面生成和变形网络进行了比较,并显示了优异的结果。 但是,我们的方法并非没有局限性。 确实,某些变形确实需要更改源网格拓扑,例如,将不带手柄的椅子变形为带手柄的椅子时。 如果源模型或目标模型中都存在大孔,则由于可能生成许多错误的点对应关系Chamfer and Earth Mover’s distances很难计算。