【机器学习】CART分类决策树+代码实现
1. 基础知识
CART作为二叉决策树,既可以分类,也可以回归。
分类时:基尼指数最小化。
回归时:平方误差最小化。
数据类型:标值型,连续型。连续型分类时采取“二分法”, 取中间值进行左右子树的划分。
2. CART分类树
特征A有N个取值,将每个取值作为分界点,将数据D分为两类,然后计算基尼指数Gini(D,A), 选择基尼指数小的特征A的取值。然后对于每个特征在计算基尼指数,最后得到最佳的特征的最佳取值作为分支点。
基尼指数表示数据D的不纯度,基尼指数越小不纯度越小。

3. CART回归树
切分数据时依据的误差函数:总方差最小化。
计算属于该节点的所有样本的y的均值 , 接着计算总方差,N为属于该节点的样本数目:
, 接着计算总方差,N为属于该节点的样本数目:

特征A的某个取值val将数据集分成两个数据集,那么分支后的误差为:

每次选择用于分支的特征及其对应的值时:遍历所有的特征,遍历每个特征所有的取值,找出使得误差最小的特征及其取值。
4.模型树
普通回归树:叶子节点上是属于该节点的样本的y值的均值;
模型树:叶子节点上是线性模型。
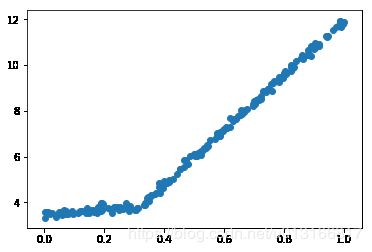
引入模型树的原因:有些样本数据可能用线性模型描述y值比用数值要方便,比如下图,用两个线性函数描述这些数据点更为合适。
5. 构建树的停止条件
误差阈值:误差较于分割前的数据集下降不多;
数据集大小阈值:分割出的数据集所包含的数据过少;
分割后的数据集属于同一类(分类),所有值相等(回归);
6.树的剪枝
预剪枝:边生成树边剪枝,两种方法:其一是设置一些阈值(比如容许误差降低的最小值,叶子节点中含有样本数的最小值),其二利用验证集,计算该节点分支前后误差的变化。缺点:其一对数据的数量级较为敏感,可能需要随时改变阈值大小,其二产生欠拟合。
后剪枝:先用训练集生成尽可能大的树,然后利用验证集(测试集)在这棵树上进行剪枝。
注意:回归树中,生成树时,计算误差用的均值是训练集中属于该个分组的y的均值,但是用测试集剪枝时,均值仍旧是之前的训练集上的均值。
7. 代码实现
参考:《机器学习实战》
源码地址以及数据:https://github.com/JieruZhang/MachineLearninginAction_src
from numpy import *
#加载数据集
def loadData(filename):
dataMat = []
fr = open(filename)
for line in fr.readlines():
line = line.strip().split('\t')
for i in range(len(line)):
line[i] = float(line[i])
dataMat.append(line)
return dataMat
#切分数据集,对于特征属性feature,以value作为中点,小于value作为数据集1,大于value作为数据集2
def binSplitData(data, feature, value):
#nonzero,当使用布尔数组直接作为下标对象或者元组下标对象中有布尔数组时,
#都相当于用nonzero()将布尔数组转换成一组整数数组,然后使用整数数组进行下标运算。
mat1 = data[nonzero(data[:,feature] > value)[0],:]
mat2 = data[nonzero(data[:,feature] <= value)[0],:]
return mat1, mat2
#找到数据切分的最佳位置,遍历所有特征及其可能取值找到使误差最小化的切分阈值
#生成叶子节点,即计算属于该叶子的所有数据的label的均值(回归树使用总方差)
def regLeaf(data):
return mean(data[:,-1])
#误差计算函数:总方差
def regErr(data):
return var(data[:,-1]) * shape(data)[0]
#最佳切分查找函数
def chooseBestSplit(data, leafType=regLeaf, errType=regErr, ops=(1,4)):
#容许的误差下降值
tolS = ops[0]
#切分的最少样本数
tolN = ops[1]
#如果数据的y值都相等,即属于一个label,则说明已经不用再分了,则返回叶子节点并退出
if len(set(data[:,-1].T.tolist()[0])) == 1:
return None, leafType(data)
#否则,继续分
m,n = shape(data)
#原数据集的误差
s = regErr(data)
#最佳误差(先设为极大值),最佳误差对应的特征的index,和对应的使用的切分值
best_s = inf
best_index = 0
best_val = 0
for feat_index in range(n-1):
for val in set(data[:,feat_index].T.A.tolist()[0]):
#根据特征feat_index和其对应的划分取值val将数据集分开
mat1, mat2 = binSplitData(data, feat_index, val)
#若某一个数据集大小小于tolN,则停止该轮循环
if (shape(mat1)[0] < tolN) or (shape(mat2)[0] < tolN):
continue
new_s = errType(mat1) + errType(mat2)
if new_s < best_s:
best_s = new_s
best_index = feat_index
best_val = val
#如果最佳的误差相较于总误差下降的不多,则停止分支,返回叶节点
if (s-best_s) < tolS:
return None, leafType(data)
#如果划分出来的两个数据集,存在大小小于tolN的,也停止分支,返回叶节点
mat1, mat2 = binSplitData(data, best_index, best_val)
if (shape(mat1)[0] < tolN) or (shape(mat2)[0] < tolN):
return None, leafType(data)
#否则,继续分支,返回最佳的特征和其选取的值
return best_index, best_val
#创建回归树
def createTree(data, leafType=regLeaf, errType=regErr, ops = (1,4)):
#找到最佳的划分特征以及其对应的值
feat, val = chooseBestSplit(data, leafType, errType, ops)
#若达到停止条件,feat为None并返回数值(回归树)或线性方程(模型树)
if feat is None:
return val
#若未达到停止条件,则根据feat和对应的val将数据集分开,然后左右孩子递归地创建回归树
#tree 存储了当前根节点划分的特征以及其对应的划分值,另外,左右孩子也作为字典存储
rgtree = {}
rgtree['spInd'] = feat
rgtree['spVal'] = val
lset, rset = binSplitData(data,feat,val)
rgtree['left'] = createTree(lset,leafType, errType, ops)
rgtree['right'] = createTree(rset,leafType, errType, ops)
return rgtree
#判断是否为树
def isTree(obj):
return (type(obj).__name__ == 'dict')
#递归函数,找到叶节点平均值,塌陷处理
def getMean(tree):
if isTree(tree['right']):
tree['right'] = getMean(tree['right'])
if isTree(tree['left']):
tree['left'] = getMean(tree['left'])
return (tree[left] + tree[right])/2.0
#剪枝
def prune(tree, testData):
#如果测试数据为空,则直接对原树进行塌陷处理
if shape(testData)[0] == 0:
return getMean(tree)
#如果当前节点不是叶子节点的父节点,将test数据分支,然后递归地对左子树和右子树剪枝
if isTree(tree['left']) or isTree(tree['right']):
lSet, rSet = binSplitData(testData, tree['spInd'], tree['spVal'])
if isTree(tree['left']):
tree['left'] = prune(tree['left'],lSet)
if isTree(tree['right']):
tree['right'] = prune(tree['right'],rSet)
#如果当前节点是叶子节点的父节点,即左右子树都为一个数值而非子树,计算剪枝前后,测试数据在这个父节点出的误差
#根据误差是否降低来判断是否剪枝(合并左右叶子节点到其父节点,使该父节点成为新的叶子节点)
if (not isTree(tree['left'])) and (not isTree(tree['right'])):
lSet, rSet = binSplitData(testData, tree['spInd'], tree['spVal'])
#不剪枝
errorNoMerge = sum(power(lSet[:,-1]-tree['left'],2)) + sum(power(rSet[:,-1]-tree['right'],2))
#剪枝
treeMean = (tree['left'] + tree['right'])/2.0
errorMerge = sum(power(testData[:,-1]-treeMean,2))
if errorMerge < errorNoMerge:
print('merging')
return treeMean
else:
return tree
else:
return tree