DABNet: Depth-wise Asymmetric Bottleneck for Real-time Semantic Segmentation
论文地址:https://arxiv.org/pdf/1907.11357.pdf
代码地址:https://github.com/Reagan1311/DABNet
论文利用了depth-wise asymmetric convolution and dilated convolution 设计了DAB module(Depthwise Asymmetric Bottleneck),充分利用了感受视野和上下文信息。
- 关于实时分割的一些处理方法:
Enet----减少卷积filter的数量,减少计算量
ICnet----cascade network with 多尺度分辨率分支
ERFnet----残差连接和因式分解卷积
ESPnet ----esp module(efficient spatial pyramid)
BiSeNet ---- 两个分支信息的融合,语义信息和空间信息
空洞卷积:
Dilated convolution ---- 在不增加参数量的情况下扩大感受视野
deeplab----atrous spatial pyramid pooling (ASPP) module 采集多尺度信息
DenseASPP----concatenate dilated convolution layers 获取密集的多尺度信息
Convolution Factorization:
将普通卷积分解,减少计算量和memory的消耗。
例如inception,xception,mobilenet系列,shufflenet系列
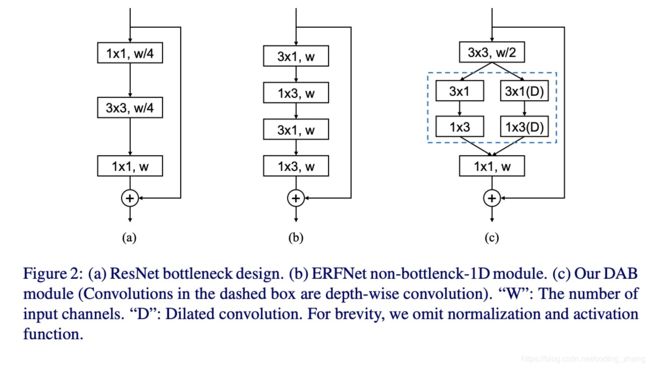
- DAB module
如上图c所示,
1. 作者首先采用了3*3的卷积去减少channel,而不是1*1的卷积。虽然1*1的卷积能够减少计算量。但是1*1的卷积在resnet中采用主要是为了加深网络的深度,但是这里不需要网络深度100层以上。
2. 为了更好的获取空间信息,作者在卷积之后将channel数减少了一般,并没有压缩太多。
3. 由于之前的网路结构已经证实分层的网络会对语义分割任务更有效,所以DAB module也是融合多尺度的信息,感觉也是借鉴了bisenet,采用了双分支的结构。
一个分支获取local information,为了减少计算量,借鉴了erfnet采用了将n*n的卷积分解成n*1深度可分离卷积和1*n的深度可分离卷积。
一个分支为了获取边缘语义信息,采用空洞卷积,在不减少分辨率的情况下。但是空洞卷积随着rate的增大,计算量也会变大。为了解决这个问题,作者将其与depth-wise asymmetric convolution结合。所以叫做depth-wise asymmetric dilated convolution。
激活函数:
作者采用了前置激活的策略(conv之前做激活),参考(Identity mappings in deep residual networks ICCV 2016),并且Mobilenetv2: Inverted residuals and linear bottlenecks中提出了non-linear layers in bottlenecks hurts the performance。所以在1*1的point-wise convolution之删除了non-linearity
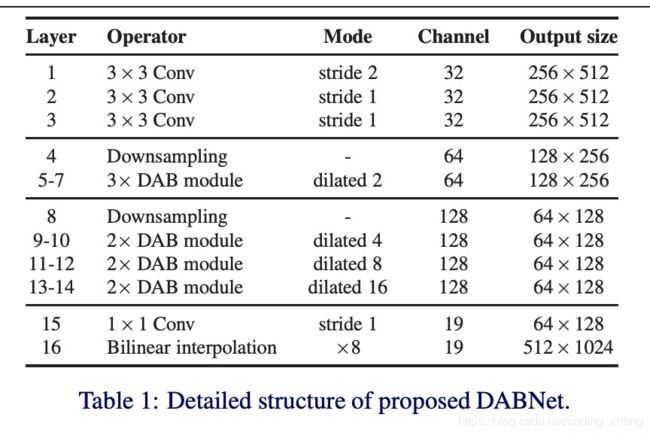
- 网络设计:
Downsampling策略:作者没有像enet一样一上来就下采样而是先用3*3卷积减少通道然后采用enet initial block,之后再经过一次不加max pooling的下采样。借鉴ESPNetv2中的方法,利用了long-range shortcut connection融合原图和downsampling block。
DAB block:做block内的信息融合,采用可空洞卷积。毕竟dense connect的方式效果还是很显著的。
DABnet:无decoder
- 实验分析
参数的一些设置:use mini-batch stochastic gradient descent (SGD) with batch size 8, momentum 0.9 and weight decay 1e −4 in training. We employ the “poly” learning rate policy [5] and the initial learning rate is set to 4.5e −2 with power 0.9.
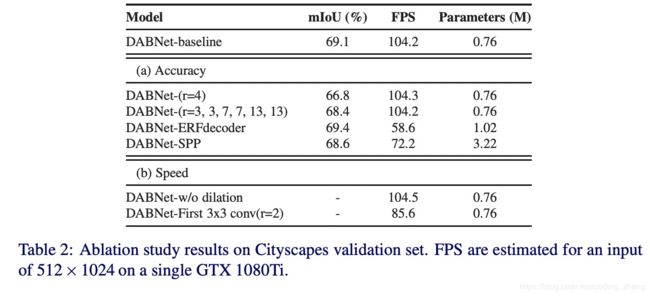

实验结果表明:
1. 空洞卷积rate{3, 3, 7, 7, 13, 13}要比{4, 4, 8, 8, 16, 16}高2.3个点。
2.加上decoder效果提升不大,但是很影响速度。
3.加入spp有效果提升,但是也会影响速度。