Ubuntu服务器宕机排查记录
环境 :ubuntu
问题症状:服务器内存占用持续增长,性能低下,并发上不去,网络无法ping通,无法登录、无法操作,输入操作无响应。也就是说系统宕机了。
宕机原因 : 先查看线上服务日志,再通过分析Linux系统日志后,报错perf采样太长,可能是I/O中断或者是网络中断时间太长导致。

排查思路:分析出内存泄露模块,分析出性能瓶颈,调优JVM
系统日志一般在/var/log/下面
1.查看messages日志,看看有没有CPU温度过高这样的日志。(ubuntu里面是查看kern.log)
2.查看cron 日志
3.查看last 命令:查看最后执行的命令
4.查看boot.log是否有异常
5.service --status-all 该命令查看所有服务当前的运行状态。将按照字母的顺序运行所有的 init 脚本
6.chkconfig --list 显示所有运行级系统服务的运行状态信息(on或off)。如果指定了name,那么只显示指定的服务在不同运行级的状态。
使用工具:jconsole、jprofiler
查看是否有异常登录用户或者登录失败的用户
1. w命令
w 命令是显示系统中正在登陆的用户信息的命令,这个命令查看的痕迹日志是/var/run/utmp。
2.who命令
who 命令和 w 命令类似,用于查看正在登陆的用户,但是显示的内容更加简单,也是查看/var/run/utmp 日志。
3. last命令
last 命令是查看系统所有登陆过的用户信息的,包括正在登陆的用户和之前登陆的用户。这个命令查看的是/var/log/wtmp 痕迹日志文件。
4.lastlog 命令
lastlog 命令是查看系统中所有用户最后一次的登陆时间的命令,他查看的日志是/var/log/lastlog文件。
5. lastb 命令
lastb 命令是查看错误登陆的信息的,查看的是/var/log/btmp 痕迹日志
linux(CentOS)服务宕机原因定位
列表查看"/var/log"目录中的各种日志文件及子目录介绍
系统日志介绍
>/var/log/messages:记录Linux内核消息及各种应用程序的公共日志信息,包括启动、IO错误、网络错误、程序故障等。对于未使用独立日志文件的应用程序或服务,一般都可以从该文件获得相关的事件记录信息。
>/var/log/cron:记录crond计划任务产生的事件消息。
>/varlog/dmesg:记录Linux系统在引导过程中的各种事件信息。
>/var/log/maillog:记录进入或发出系统的电子邮件活动。
>/var/log/lastlog:最近几次成功登录事件和最后一次不成功登录事件。
>/var/log/rpmpkgs:记录系统中安装各rpm包列表信息。
>/var/log/secure:记录用户登录认证过程中的事件信息。
>/var/log/wtmp:记录每个用户登录、注销及系统启动和停机事件。
>/var/log/utmp:记录当前登录的每个用户的详细信息。
实例
检查系统日志信息:
# tail -100 /var/log/messages
检查登录的账号和IP地址:
# tail -100 /var/log/secure
检查系统是否有异常,例如发包量过大等:
# dmesg
查找到攻击源,可以使用防火墙将此攻击源屏蔽。
清理后门
在找到并处理植入/修改的文件之后,还需要清理后门,因为黑客为了下次访问方便,必然会在服务器上留有 后门。常见留后门的方法有如下几种:
- 将公钥写入到服务器的authorized_keys文件中
- 创建UID=0的普通用户
解决方法: - 清除authorized_keys文件中黑客上传的key
- cat /etc/passwd将UID为0的普通用户注释掉
查找攻击源
检查系统日志信息:
# tail -100 /var/log/messages
检查登录的账号和IP地址:
# tail -100 /var/log/secure
检查系统是否有异常,例如发包量过大等:
# dmesg
查找到攻击源,可以使用防火墙将此攻击源屏蔽。
常见linux系统入侵原因
服务器被入侵原因通常有几个:系统漏洞、中间件漏洞(程序漏洞)、代码漏洞、安全设置不正确、网络层面 没有限制等。 如果是系统漏洞和中间件漏洞,需要使用没有发现漏洞的系统和中间件进行升级。 如果是程序/代码漏洞,需要修改程序代码进行修改,或者部署waf防火墙。 如果是安全设置不正确,需要进一步检查安全配置。 如果是网络层面没有限制,需要在防火墙和IPS上进行检查。 通过植入文件启动进程的入侵方式,一般户看到类似这种进程或者文件:aa.sh,.sdofafdjja,是通过系 统漏洞或者中间件漏洞入侵的;如果没有发现被植入的文件,但是系统就是有异常,这种一般是通过代码漏洞 来入侵的。
Ubuntu查看日志实例
有两台机器宕机了,分别查看系统日志
1、查看/var/log/dmes日志,查看Linux系统在引导过程中的各种事件信息
#cat /var/log/dmesg
或者
#tail -f /var/log/dmesg
#查看启动日志
#cat /var/log/boot.log
#查看内存日志
#dmesg | tail -200 #打印后200行日志
查看内核的信息: dmesg
$ dmesg |tail
#查看
开机自启动的自检日志
Ubuntu下
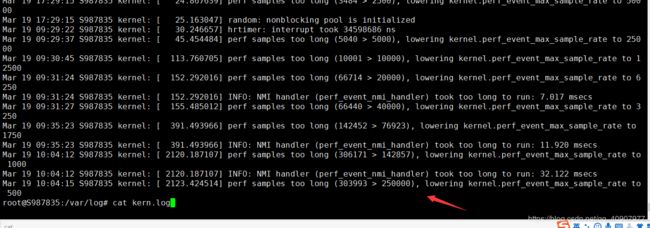
/var/log# cat kern.log
CentOS下
/var/log# cat messages.log
出现报错
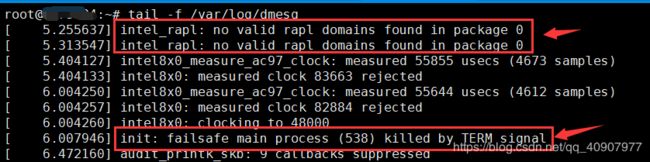
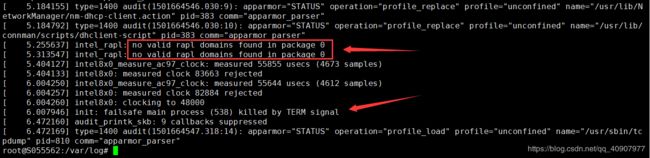
intel_rapl: no valid rapl domains found in package 0
init: failsafe main process (538) killed by TERM signal

解决办法 :
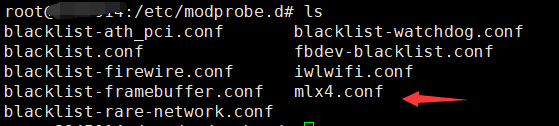
#vi /etc/modprobe.d/blacklist.conf
blacklist intel_rapl
重启服务器:
reboot
或者
方法二、
在 /etc/modprobe.d/mlx4.conf后面加入:blacklist intel_rapl
报错信息 :
init: failsafe main process (538) killed by TERM signal
解决办法 :
此报错是上次关机时为正确关机造成的,关机时需要停掉服务,使用shutdown -h now 关机重启后正常了
查看日志管理工具
journalctl -xb
报错信息 :
3月 10 19:16:39 S251045.domain kernel: No AGP bridge found
3月 10 19:16:39 S251045.domain kernel: Calgary: detecting Calgary via BIOS EBDA area
3月 10 19:16:39 S251045.domain kernel: Calgary: Unable to locate Rio Grande table in EBDA - bailing!
3月 10 19:16:41 S251045.domain kernel: intel_rapl: no valid rapl domains found in package 0
3月 10 19:16:42 S251045.domain kernel: intel_rapl: no valid rapl domains found in package 0
Skipping profile in /etc/apparmor.d/disable: usr.sbin.rsyslogd
3月 10 19:16:44 S251045.domain ntpdate[532]: name server cannot be used: Temporary failure in name resolution (-3)
please try ‘cgroup_disable=memory’ option if you don't want memory cgroups
3月 10 11:16:57 S251045.domain kernel: random: nonblocking pool is initialized
3月 10 11:16:58 S251045.domain kernel: perf samples too long (14968 > 10000), lowering kernel.perf_event_max_sample_rate to 12500
3.11内核:perf采样太长(2501> 2500),将kernel.perf_event_max_sample_r降低到50000

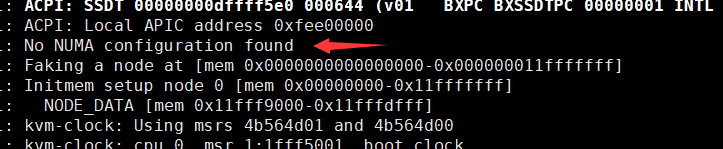





单独打印内存日志
# dmesg | grep -i memory
实时监控dmesg日志输出
tail -f /var/log/dmesg
报错原因 : 编译内核报错(打了LXC补丁)
http://blog.chinaunix.net/uid-434226-id-3433276.html
报错
#tail -f /var/log/dmesg
3月 10 11:16:58 S251045.domain kernel: perf samples too long (14968 > 10000), lowering kernel.perf_event_max_sample_rate to 12500
编译
3.11内核:perf采样太长(14968> 10000),将kernel.perf_event_max_sample_r降低到12500
解决办法:
[root@localhost kernel]#vi /etc/sysctl.conf #最后添加
kernel.perf_event_max_sample_rate = 2559126
kernel.perf_cpu_time_max_percent = 0
[root@localhost kernel]# cat /etc/sysctl.conf|grep per
kernel.perf_event_max_sample_rate = 2559126
kernel.perf_cpu_time_max_percent = 0
或者
#echo 0 > /proc/sys/kernel/perf_cpu_time_max_percent
#echo 2559126 > /proc/sys/kernel/perf_event_max_sample_rate
https://blog.csdn.net/cqcaj40400/article/details/100317578


报错原因 :
解决办法 :
1、intel_rapl:no valid rapl domains found in package 0错误解决办法
修改 /etc/modprobe.d/blacklist.conf 内容,加入 blacklist intel_rapl

报错信息:
fail to add MMCONFIG information, can't access extended PCI configuration space under this bridge.
![]()

解决办法 :
报错信息
[ 1077.804015] INFO: NMI handler (arch_trigger_all_cpu_backtrace_handler) took too long to run: 8.840 msecs
[ 1213.520015] INFO: NMI handler (perf_event_nmi_handler) took too long to run: 20.811 msecs
# dmesg | tail -200
[ 13.665560] cgroup: new mount options do not match the existing superblock, will be ignored
[ 19.932639] ip_tables: (C) 2000-2006 Netfilter Core Team
[ 34.954130] random: nonblocking pool is initialized
[ 939.674829] INFO: NMI handler (perf_event_nmi_handler) took too long to run: 1.265 msecs
[ 1028.627390] hrtimer: interrupt took 13461441 ns
[ 1077.804015] INFO: NMI handler (arch_trigger_all_cpu_backtrace_handler) took too long to run: 8.840 msecs
[ 1213.520015] INFO: NMI handler (perf_event_nmi_handler) took too long to run: 20.811 msecs
[ 2593.266220] INFO: NMI handler (perf_event_nmi_handler) took too long to run: 25.754 msecs
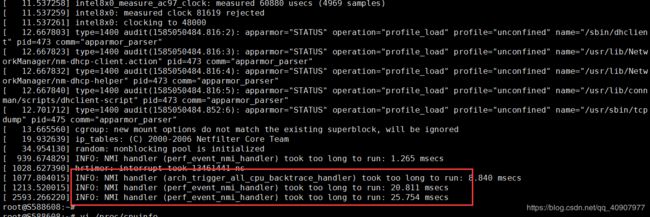
报错原因 :服务器CPU降频
解决办法 :
#vi /proc/cpuinfo
model name : Intel(R) Xeon(R) CPU E5-2650 0 @ 2.00GHz
stepping : 7
microcode : 0x1
cpu MHz : 1999.999
cache size : 4096 KB
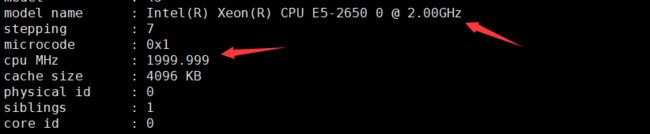
可以看出跟CPU频率
查看系统内核
注意:
所谓lockup,是指某段内核代码占着CPU不放。Lockup严重的情况下会导致整个系统失去响应。Lockup有几个特点:
- 首先只有内核代码才能引起lockup,因为用户代码是可以被抢占的,不可能形成lockup(只有一种情况例外,就是SCHED_FIFO优先级为99的实时进程即使在用户态也可能使[watchdog/x]内核线程抢不到CPU而形成soft
lock,参见《Real-Time进程会导致系统Lockup吗?》) - 其次内核代码必须处于禁止内核抢占的状态(preemption
disabled),因为Linux是可抢占式的内核,只在某些特定的代码区才禁止抢占,在这些代码区才有可能形成lockup。
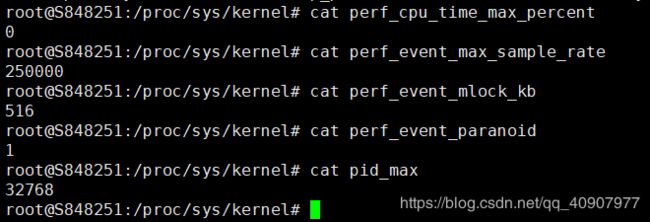
查看内核配置
/proc/sys/kernel# cat perf_cpu_time_max_percent
0
/proc/sys/kernel# cat perf_event_max_sample_rate
250000
/proc/sys/kernel# cat perf_event_mlock_kb
516
/proc/sys/kernel# cat perf_event_paranoid
1
/proc/sys/kernel# cat pid_max
32768
更多介绍:https://blog.csdn.net/zhuyong006/article/details/84666491?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task
查看日志配置文件"/etc/syslog.conf’中的内容
1.使用last -F |grep carsh
查看宕机记录
2.访问/var/logmessage日期查看宕机前的系统日志,查看是否有告警信息,根据告警信息具体检查
查看dmesg查看内核日志
查看/var/log/secure查看安全日志判断是否有人恶意攻击服务器
3.2中未查到错误信息
使用sar -r -f /var/log/sa/sa日期|more sar -u -f /var/log/sa/sa日期|more查看宕机当时的cpu内存情况
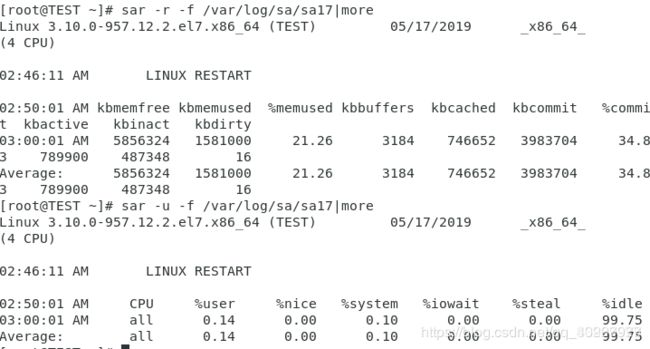
top查看负荷,free -m 查看内存情况
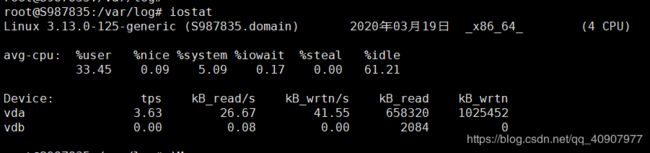
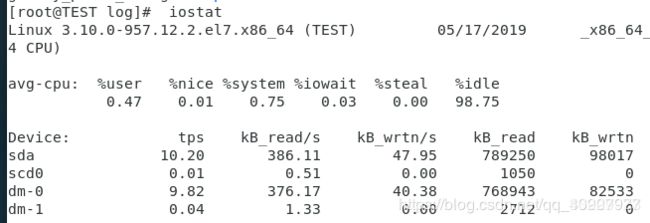
4. 磁盘IO性能
可以先检查一下服务器的性能,使用iostat vmstat top等这些命令。
命令 iostat 可得到相应的数值
#iostat 2 10 2s一次,测试10次
好:iowait%<20%
坏:iowait% = 35%
糟糕:iowait%>=50%
#vmstat 2 10 #每隔2秒打印一次,打印10次。
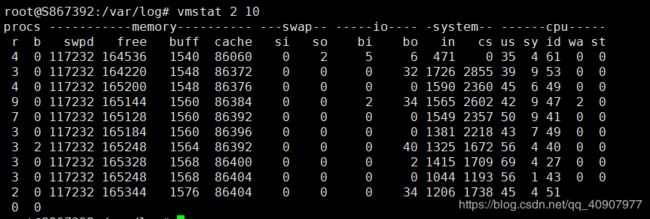
uptime查看服务器运行重启情况
5.查看是否有硬件告警
服务器排查以及优化
清理内存
#1.【推荐】释放网页缓存(To free pagecache),
sync
echo 1 > /proc/sys/vm/drop_caches
#2.释放目录项和索引(To free dentries and inodes)
sync
echo 2 > /proc/sys/vm/drop_caches
#3.释放网页缓存,目录项和索引(To free pagecache, dentries and inodes):
sync
echo 3 > /proc/sys/vm/drop_caches
选择适合自己的方式清理,再执行查看内存情况,就可以看到内存已经有很大空闲空间;
扩展
CentOS下查看cpu温度
检查是否安装:rpm -q lm_sensors
如果没有:yum install -y lm_sensors安装
sh -c "yes|sensors-detect"检测传感器
sensors-detect
chkconfig --list | grep ‘lm_sensors’
sensors查看cpu温度

mesg 命令的使用范例
‘dmesg’命令设备故障的诊断是非常重要的。在‘dmesg’命令的帮助下进行硬件的连接或断开连接操作时,我们可以看到硬件的检测或者断开连接的信息。‘dmesg’命令在多数基于Linux和Unix的操作系统中都可以使用。
列出所有被检测到的硬件
要显示所有被内核检测到的硬盘设备,你可以使用‘grep’命令搜索‘sda’关键词,如下:
[root@tecmint.com ~]# dmesg | grep sda
注解 ‘sda’表示第一块 SATA硬盘,‘sdb’表示第二块SATA硬盘。若想查看IDE硬盘搜索‘hda’或‘hdb’关键词。
3. 只输出dmesg命令的前20行日志
在‘dmesg’命令后跟随‘head’命令来显示开始几行,‘dmesg | head -20′命令将显示开始的前20行。
[root@tecmint.com ~]# dmesg | head -20
4. 只输出dmesg命令最后200行日志
在‘dmesg’命令后跟随‘tail’命令(‘ dmesg | tail -200’)来输出‘dmesg’命令的最后200行日志,当你插入可移动设备时它是非常有用的。
[root@tecmint.com ~]# dmesg | tail -200
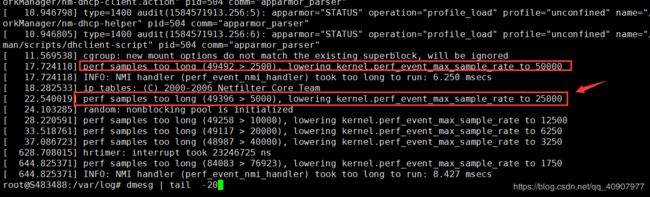
报错信息 :
root@S483488:/var/log# dmesg | tail -20
[ 11.569538] cgroup: new mount options do not match the existing superblock, will be ignored
[ 17.724118] perf samples too long (49492 > 2500), lowering kernel.perf_event_max_sample_rate to 50000
[ 17.724118] INFO: NMI handler (perf_event_nmi_handler) took too long to run: 6.250 msecs
[ 18.282533] ip_tables: (C) 2000-2006 Netfilter Core Team
[ 22.540019] perf samples too long (49396 > 5000), lowering kernel.perf_event_max_sample_rate to 25000
[ 24.103285] random: nonblocking pool is initialized
[ 28.220591] perf samples too long (49258 > 10000), lowering kernel.perf_event_max_sample_rate to 12500
[ 33.518761] perf samples too long (49117 > 20000), lowering kernel.perf_event_max_sample_rate to 6250
[ 628.708015] hrtimer: interrupt took 23246725 ns
[ 644.825371] perf samples too long (84083 > 76923), lowering kernel.perf_event_max_sample_rate to 1750
[ 644.825371] INFO: NMI handler (perf_event_nmi_handler) took too long to run: 8.427 msecs
解决办法 :
cgroup: new mount options do not match the existing superblock, will be ignored
编译
cgroup:新的装入选项与现有的超级块不匹配,将被忽略
#cat /etc/fstab
5. 搜索包含特定字符串的被检测到的硬件
由于‘dmesg’命令的输出实在太长了,在其中搜索某个特定的字符串是非常困难的。因此,有必要过滤出一些包含‘usb’ ‘dma’ ‘tty’ ‘memory’等字符串的日志行。grep 命令 的‘-i’选项表示忽略大小写。
[root@tecmint.com log]# dmesg | grep -i usb
[root@tecmint.com log]# dmesg | grep -i dma
[root@tecmint.com log]# dmesg | grep -i tty
[root@tecmint.com log]# dmesg | grep -i memory
6. 清空dmesg缓冲区日志
我们可以使用如下命令来清空dmesg的日志。该命令会清空dmesg环形缓冲区中的日志。但是你依然可以查看存储在‘/var/log/dmesg’文件中的日志。你连接任何的设备都会产生dmesg日志输出。
[root@tecmint.com log]# dmesg -c
7. 实时监控dmesg日志输出
在某些发行版中可以使用命令‘tail -f /var/log/dmesg’来实时监控dmesg的日志输出。
[root@tecmint.com log]# watch "dmesg | tail -20"
结论:dmesg命令在系统dmesg记录实时更改或产生的情况下是非常有用的。你可以使用man dmesg来获取更多关于dmesg的信息。
8、由于‘dmesg’命令的输出实在太长了,在其中搜索某个特定的字符串是非常困难的。因此,有必要过滤出一些包含‘usb’ ‘dma’ ‘tty’ ‘memory’等字符串的日志行。grep 命令 的‘-i’选项表示忽略大小写
# dmesg | grep -i memory #查看内存日志
9、实时监控dmesg日志输出
tail -f /var/log/dmesg
错误一
end_request:I/O error,dev fd0,sector 0
- 出现这个错误的原因如果在一般的主机和虚拟机的关系中,表示系统加载“软驱”(fd0表示软驱,在etc目录中)出错,那么可以将fd0目录删除,或者直接禁用,即可解决。
- 但如果这种问题出现在了以集群为平台的虚拟机中,由于在创建虚拟机的时候并没有给虚拟机分配相关的光驱或者软驱,那么出现这种问题的原因就是由于不正常关机导致的系统目录加载出错,网上其他的解决方案也称之为“硬盘挂载”出错。相应的解决方案就是恢复系统默认设置,直接键入:systemctl default,然后回车。等待系统自行重启完毕之自动进入default mode后即可。
- 注:由于处于emergency mode时,默认的设置还是最后一次“正确”配置,所以直接使用systemctl reboot是无法解决问题的。
错误二
Error getting authority: Error initializing authority: Could not connect: No such file or directory
- 出现这个错误的原因也是由于磁盘挂在错误导致的,如果在fstab中修改无效的话,同样使用systemctl default恢复默认设置即可。(注:在键入这个命令之后可能会报错,但是不用关心这个错误,紧接着用命令重启机器即可解决)
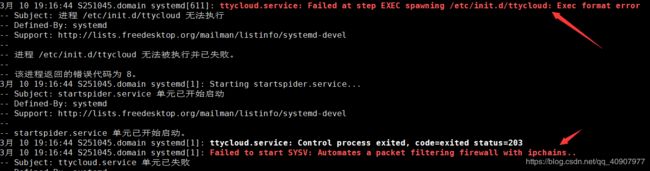
Ubuntu服务器死机
报错信息 :
Failed to start SYSV: Automates a packet filtering firewall with ipchains..

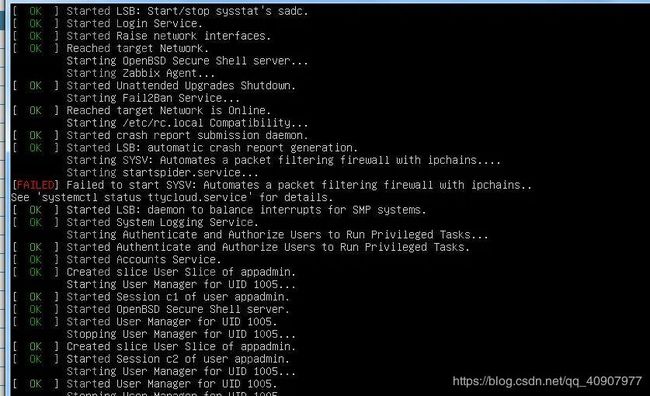
原因 :
解决办法:
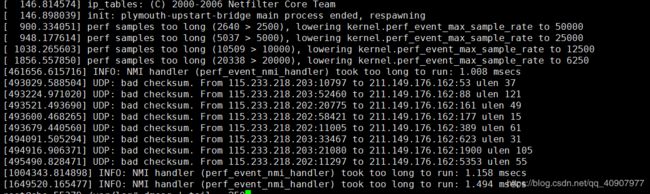
查看日志信息 :tail -f /var/log/dmesg
#dmesg | tail -200 #查看日志前200行
[ 146.898039] init: plymouth-upstart-bridge main process ended, respawning
[ 900.334051] perf samples too long (2640 > 2500), lowering kernel.perf_event_max_sample_rate to 50000
[ 948.177614] perf samples too long (5037 > 5000), lowering kernel.perf_event_max_sample_rate to 25000
[ 1038.265603] perf samples too long (10509 > 10000), lowering kernel.perf_event_max_sample_rate to 12500
[ 1856.557850] perf samples too long (20338 > 20000), lowering kernel.perf_event_max_sample_rate to 6250
[461656.615716] INFO: NMI handler (perf_event_nmi_handler) took too long to run: 1.008 msecs
[493029.588504] UDP: bad checksum. From 115.233.218.203:10797 to 211.149.176.162:53 ulen 37
[493224.971020] UDP: bad checksum. From 115.233.218.203:52460 to 211.149.176.162:88 ulen 121
[493521.493690] UDP: bad checksum. From 115.233.218.202:20775 to 211.149.176.162:161 ulen 49
[495490.828471] UDP: bad checksum. From 115.233.218.202:11297 to 211.149.176.162:5353 ulen 55
[1004343.814898] INFO: NMI handler (perf_event_nmi_handler) took too long to run: 1.158 msecs
[1649520.165477] INFO: NMI handler (perf_event_nmi_handler) took too long to run: 1.494 msecs
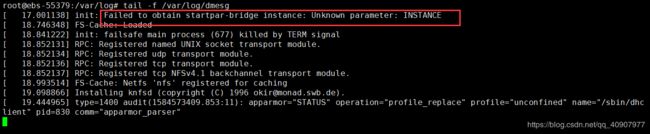
修改内核参数:
# cat /etc/sysctl.conf|grep per
kernel.perf_event_max_sample_rate = 12500
kernel.perf_cpu_time_max_percent = 0
#vi /etc/modprobe.d/blacklist.conf
blacklist intel_rapl
Ubuntu入侵检测
1.查看异常进程活动-查找是否有异常进程和端口占用
1.1查找占用cpu最多的进程,相关命令:运行top命令后,键入大写字母P按cpu排序;
1.2查找占用内存最多的进程,相关命令:运行top命令后,键入大写字母M
ps aux | sort -k4nr
1.3查找进程文件:
ls -la /proc/$pid/exe
1.4跟踪异常进程运行情况:
strace -tt -T -e trace=all -p $pid
1.5查看进程打开的文件
lsof -p $pid
1.6 查看进程端口情况
netstat -anltp | grep $pid
2.查看账号安全
2.1查看是否有存在新增异常账号:
a.查找特权用户
awk -F ":" '$3==0{print $1}' /etc/passwd
b.查找可以远程登录的账号信息
awk '/\$1|\$6/{print $1}' /etc/shadow
c.查找sudo权限账户
cat /etc/sudoers | grep -v "^#\|^$" | grep "ALL=(ALL)"
2.2 查看是否有账号异常登录情况:
a.查看当前登录用户和其行为
w
b.查看所有用户最后一次登录的时间
lastlog
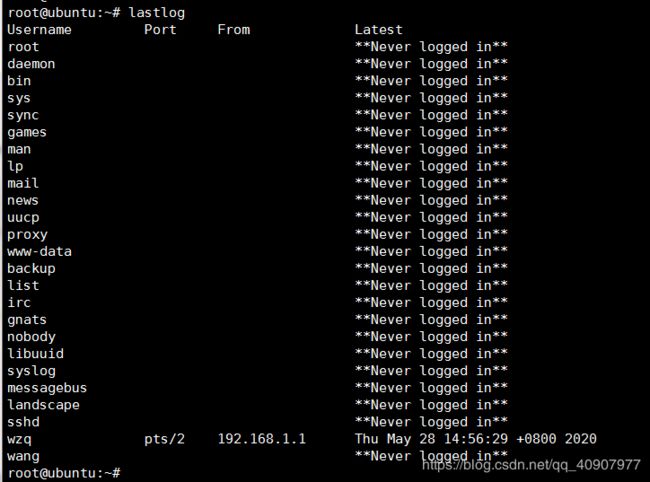
c.查看所有用户的登录注销信息及系统的启动、重启及关机事件
last
d.查看登录成功的日期、用户名及ip
grep "Accepted " /var/log/secure* | awk '{print $1,$2,$3,$9,$11}'
e.查看试图爆破主机的ip
grep refused /var/log/secure* | awk {'print $9'} | sort | uniq -c |sort -nr | more
grep "Failed password" /var/log/secure* | grep -E -o "(([0-9]{1,3})\.([0-9]{1,3})\.([0-9]{1,3})\.([0-9]{1,3}))" | uniq -c
f.查看有哪些ip在爆破主机的root账号
grep "Failed password for root" /var/log/secure | awk '{print $11}' | sort
g.查看爆破用户名字典
grep "Failed password" /var/log/secure | awk {'print $9'} | sort | uniq -c | sort -nr
3.查找异常文件
3.1 查找cron文件中是否存在恶意脚本
/var/spool/cron/*
/etc/crontab
/etc/cron.d/*
/etc/cron.daily/*
/etc/cron.hourly/*
/etc/cron.monthly/*
/etc/cron.weekly/
/etc/anacrontab
/var/spool/anacron/*
3.2 查看最近一段时间内被修改的系统文件
find /etc/ /usr/bin/ /usr/sbin/ /bin/ /usr/local/bin/ -type f -mtime -T | xargs ls -la
3.3 按时间排序,确认最近是否有命令被替换,可以结合rpm -Va命令
ls -alt /usr/bin /usr/sbin /bin /usr/local/bin
rpm -Va>rpm.log
3.4 确认是否有异常开机启动项
cat /etc/rc.local
chkconfig --list
4.借助工具查杀病毒和rootkit
4.1 查杀rootkit
chkrootkit (下载地址-http://www.chkrootkit.org)
rkhunter (下载地址-http://rkhunter.sourceforge.net)
4.2 查杀病毒
clamav(下载地址-http://www.clamav.net/download.html)
4.3 查杀webshell
cloudwalker(下载地址-http://github.com/chaitin/cloudwalker)
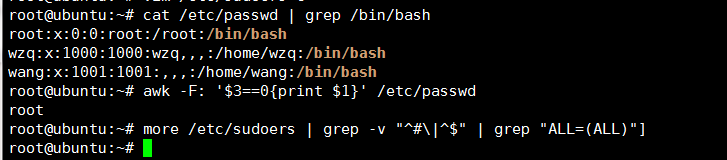
5、排查passwd 文件,重点排查如下内容:
- 哪些用户不能登录,shell却为/bin/bash —> 修改建议:将shell修改为/sbin/nologin
- 哪些普通用户的UID=0 —> 修改建议:禁用该用户或删除该用户
- 是否多出了不明用户。
# 查看可登录用户:
cat /etc/passwd | grep /bin/bash
# 查看UID=0的用户
awk -F: '$3==0{print $1}' /etc/passwd
# 查看sudo权限的用户
more /etc/sudoers | grep -v "^#\|^$" | grep "ALL=(ALL)"
6、排查端口进程
使用top命令查看进程,然后按c。
# 使用ls -l命令查看某个进程的可执行文件的完整路径
例如:查看 PID=842的SSH进程的可执行文件
# ls -l /proc/842/exe
lrwxrwxrwx 1 root root 0 Jan 7 19:06 /proc/842/exe -> /usr/sbin/sshd
# 如果找不到任何可疑文件,文件可能被删除,这个可疑的进程已经保存到内存中,是个内存进程。这时需要查找PID 然后kill掉。
#lsof 命令查看进程打开的文件
➜ ~ lsof -p 7502
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
zsh 7502 root cwd DIR 253,0 4096 33574977 /root
zsh 7502 root rtd DIR 253,0 224 64 /
zsh 7502 root txt REG 253,0 740496 50878051 /usr/bin/zsh
zsh 7502 root mem REG 253,0 11488 43685 /usr/lib64/zsh/5.0.2/zsh/regex.sozsh 7502 root mem REG 253,0 70280 279590 /usr/lib64/zsh/5.0.2/zsh/computil.so
# 或者通过服务名查看该进程打开的文件
lsof -c sshd
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
sshd 6590 root cwd DIR 253,0 224 64 /
sshd 6590 root rtd DIR 253,0 224 64 /
sshd 6590 root txt REG 253,0 853040 551331 /usr/sbin/sshd
# 通过端口号查看进程
➜ ~ lsof -i :22
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
sshd 6590 root 3u IPv4 35947 0t0 TCP *:ssh (LISTEN)
sshd 7500 root 3u IPv4 37659 0t0 TCP localhost.localdomain:ssh->192.168.5.2:cspmulti (ESTABLISHED)
# 查看进程的启动时间点
➜ ~ ps -p 6590 -o lstart
STARTED
Wed May 27 17:23:44 2020
# 可以通过时间点来判断该进程是否是可疑进程
# 使用netstat -pantu | grep [PID] 通过进程id来查看端口的连接情况
➜ ~ netstat -pantu | grep 6590
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 6590/sshd
# 使用fuser -n [tcp/udp] [端口号] 来查看端口对应的进程
➜ ~ fuser -n tcp 22
22/tcp: 6590 7500
# 使用ps命令查看进程
➜ ~ ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 17:23 ? 00:00:01 /usr/lib/systemd/systemd --switched-rooroot 2 0 0 17:23 ? 00:00:00 [kthreadd]
root 3 2 0 17:23 ? 00:00:00 [ksoftirqd/0]
root 5 2 0 17:23 ? 00:00:00 [kworker/0:0H]
root 7 2 0 17:23 ? 00:00:00 [migration/0]
root 8 2 0 17:23 ? 00:00:00 [rcu_bh]
--------------------------------------以下省略-----------------------------------------------------------
# 使用[]括起来的进程一般是正常的系统进程,黑客的进程通常是.sshd,aa.sh,.sdofafdjja等。这些文件通常是隐藏文件,都是以【.】开头,要查找到这些文件,需要在ls命令后面加-a参数。
# 按照CPU使用率从高到低排序
➜ ~ ps -ef --sort -pcpu
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 17:23 ? 00:00:01 /usr/lib/systemd/systemd --switched-rooroot 2 0 0 17:23 ? 00:00:00 [kthreadd]
root 3 2 0 17:23 ? 00:00:00 [ksoftirqd/0]
root 5 2 0 17:23 ? 00:00:00 [kworker/0:0H]
root 7 2 0 17:23 ? 00:00:00 [migration/0]
root 8 2 0 17:23 ? 00:00:00 [rcu_bh]
--------------------------------------以下省略-----------------------------------------------------------
# 按照内存使用率从高到低排序
➜ ~ ps -ef --sort -pmem
UID PID PPID C STIME TTY TIME CMD
root 7502 7500 0 17:51 pts/1 00:00:06 -zsh
root 6046 1 0 17:23 ? 00:00:15 /usr/bin/vmtoolsd
root 6045 1 0 17:23 ? 00:00:00 /usr/bin/VGAuthService -s
root 7500 6590 0 17:51 ? 00:00:00 sshd: root@pts/1
--------------------------------------以下省略-----------------------------------------------------------
常见网络相关的内核参数调整
1 net.ipv4.tcp_max_tw_buckets
对于tcp连接,服务端和客户端通信完后状态变为timewait,假如某台服务器非常忙,连接数特别多的话,那么这个timewait数量就会越来越大。毕竟它也是会占用一定的资源,所以应该有一个最大值,当超过这个值,系统就会删除最早的连接,这样始终保持在一个数量级。
这个数值就是由net.ipv4.tcp_max_tw_buckets这个参数来决定的。CentOS7系统,你可以使用sysctl -a |grep tw_buckets来查看它的值,默认为32768,你可以适当把它调低,比如调整到8000,毕竟这个状态的连接太多也是会消耗资源的。
但你不要把它调到几十、几百这样,因为这种状态的tcp连接也是有用的,如果同样的客户端再次和服务端通信,就不用再次建立新的连接了,用这个旧的通道,省时省力。
2 net.ipv4.tcp_tw_recycle = 1
该参数的作用是快速回收timewait状态的连接。上面虽然提到系统会自动删除掉timewait状态的连接,但如果把这样的连接重新利用起来岂不是更好。所以该参数设置为1就可以让timewait状态的连接快速回收,它需要和下面的参数配合一起使用。
#3 net.ipv4.tcp_tw_reuse = 1
该参数设置为1,将timewait状态的连接重新用于新的TCP连接,要结合上面的参数一起使用。
4 net.ipv4.tcp_syncookies = 1
tcp三次握手中,客户端向服务端发起syn请求,服务端收到后,也会向客户端发起syn请求同时连带ack确认,假如客户端发送请求后直接断开和服务端的连接,不接收服务端发起的这个请求,服务端会重试多次。
这个重试的过程会持续一段时间,当这种状态的连接数量非常大时,服务器会消耗很大的资源,从而造成瘫痪,正常的连接进不来,这种恶意的半连接行为其实叫做syn flood攻击。
设置为1,是开启SYN Cookies,开启后可以避免发生上述的syn flood攻击。开启该参数后,服务端接收客户端的ack后,再向客户端发送ack+syn之前会要求client在短时间内回应一个序号,如果客户端不能提供序号或者提供的序号不对则认为该客户端不合法,于是不会发ack+syn给客户端,更涉及不到重试。
5 net.ipv4.tcp_max_syn_backlog
该参数定义系统能接受的最大半连接状态的tcp连接数。客户端向服务端发送了syn包,服务端收到后,会记录一下,该参数决定最多能记录几个这样的连接。我的CentOS7系统,默认是256,当有syn flood攻击时,这个数值太小则很容易导致服务器瘫痪,实际上此时服务器并没有消耗太多资源(cpu、内存等),所以可以适当调大它,比如调整到30000。
6 net.ipv4.tcp_syn_retries
该参数适用于客户端,它定义发起syn的最大重试次数,默认为5,建议改为2。
7 net.ipv4.tcp_synack_retries
该参数适用于服务端,它定义发起syn+ack的最大重试次数,默认为5,建议改为2,可以适当预防syn flood攻击。
8 net.ipv4.ip_local_port_range
该参数定义端口范围,系统默认保留端口为1024及以下,以上部分为自定义端口。这个参数适用于客户端,当客户端和服务端建立连接时,比如说访问服务端的80端口,客户端随机开启了一个端口和服务端发起连接,这个参数定义随机端口的范围。默认为32768 61000,建议调整为1025 61000。
9 net.ipv4.tcp_fin_timeout
tcp连接的状态中,客户端上有一个是FIN-WAIT-2状态,它是状态变迁为timewait前一个状态。该参数定义不属于任何进程的该连接状态的超时时间,默认值为60,建议调整为6。
10 net.ipv4.tcp_keepalive_time
tcp连接状态里,有一个是keepalived状态,只有在这个状态下,客户端和服务端才能通信。正常情况下,当通信完毕,客户端或服务端会告诉对方要关闭连接,此时状态就会变为timewait,如果客户端没有告诉服务端,并且服务端也没有告诉客户端关闭的话(例如,客户端那边断网了),此时需要该参数来判定。
比如客户端已经断网了,但服务端上本次连接的状态依然是keepalived,服务端为了确认客户端是否断网,就需要每隔一段时间去发一个探测包去确认一下看看对方是否在线。这个时间就由该参数决定。它的默认值为7200(单位为秒),建议设置为30。
11 net.ipv4.tcp_keepalive_intvl
该参数和上面的参数是一起的,服务端在规定时间内发起了探测,查看客户端是否在线,如果客户端并没有确认,此时服务端还不能认定为对方不在线,而是要尝试多次。该参数定义重新发送探测的时间,即第一次发现对方有问题后,过多久再次发起探测。
默认值为75秒(单位为秒),可以改为3。
12 net.ipv4.tcp_keepalive_probes
第10和第11个参数规定了何时发起探测和探测失败后再过多久再发起探测,但并没有定义一共探测几次才算结束。该参数定义发起探测的包的数量。默认为9,建议设置2。
扩展
/proc虚拟文件系统与系统内核参数修改方法
/proc 虚拟文件系统用作查看和配置系统内核参数的接口。
常用的/proc虚拟文件
/proc/cpuinfo CPU与系统架构信息。
/proc/meminfo 空闲的与已经分配使用的物理内存,虚拟内存信息。
/proc/net 存放网络信息的目录。
/proc/mounts 所有已挂载的文件系统。
/proc/diskstats 每一个磁盘的I/O 统计信息。
/proc/devices PCI 设备。
/proc/filesystems 编译进内核的文件系统。
/proc/sys 存放与系统内核相关变量的目录。其中的一些变量可以通过sysctl 设置。
/proc/cmdline 在启动的时候传递给内核的参数。
/proc/version 操作系统版本信息。
查看服务器异常宕机日志
运维检查宿主机日志未发现异常情况。建议按最近操作日志的时间,检查下主机在该时间点前的日志,看是否有异常进程引起关机。
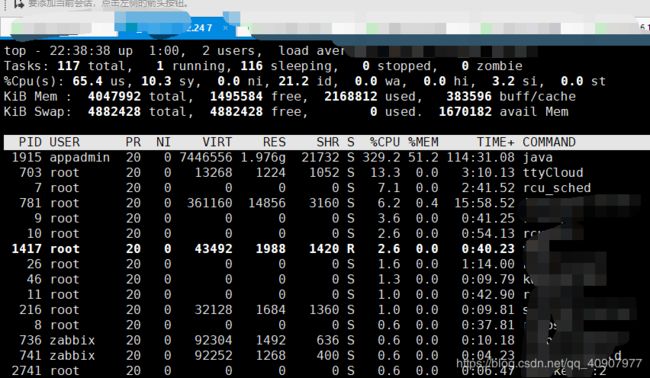
查看异常进程
#top
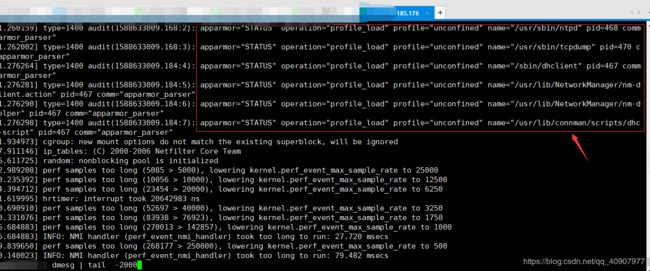
查看系统日志
#cat /var/log/dmesg |tail 200
参考链接 :
内核参数说明 :http://www.cnblogs.com/tolimit/p/5065761.html
https://blog.csdn.net/zdy0_2004/article/details/50379422?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task
intel_rapl:no valid rapl domains found in package 0错误解决办法 : https://blog.csdn.net/chenhuihuanhuan/article/details/51521033
https://blog.csdn.net/benpaodexin_l/article/details/78999732
https://www.kernel.org/doc/html/latest/trace/events-nmi.html
Linux服务器中网站数据库宕机的自动检测及重启脚本(MYSQL数据库) :https://www.jianshu.com/p/832fd59109af
解决拒绝服务攻击DDos脚本(DenyIP.sh) :
https://www.jianshu.com/p/5427f5d5fc36
linux下查看cpu温度 : https://blog.csdn.net/qq_33229923/article/details/90293213?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task
linux故障分析 : https://blog.csdn.net/xi_weina/article/details/7068475?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task
linux服务宕机原因定位 : https://blog.csdn.net/qq_33229923/article/details/90294159
【Linux】非正常关机启动报错-解决方案 : https://blog.csdn.net/SugaryoTT/article/details/76713983?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task
Centos下查看cpu、磁盘、内存使用情况以及如何清理内存 : https://blog.csdn.net/mynamepg/article/details/79226402
服务器宕机排查记录 : https://blog.csdn.net/weixin_30916125/article/details/95561458?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task
Lubuntu 16.04引导缓慢( cgroup: 新挂载选项与现有的超级块不匹配,将被忽略) : https://www.helplib.com/c/mutia_162437
记一次解决业务系统生产环境宕机问题! :https://mp.weixin.qq.com/s/X2F0WH_qnGlSkeDSh9XCPA
Linux 应急响应 : https://www.jianshu.com/p/4e1186b38e5c
常见网络相关的内核参数调整 :https://mp.weixin.qq.com/s/F3XzPITHIuHnNsckK8NDsw