pointnet 系列论文总结
目录
- pointnet
- pointnet++
- voxelnet
- frustum-pointnet
- frustum proposal
- 3D instance segmentation
- amodal 3D box estimation
- votenet
- reference
本文旨在对之前看的 pointnet 系列点云目标检测论文进行总结,包括 pointnet, pointnet++, frustum-pointnet, voxelnet, votenet。虽然 voxelnet 不属于 pointnet 系列,但其中特征提取的模块跟 pointnet 还是很类似的,这里也就一并介绍了。下面就按照论文的时间顺序依次进行总结。
pointnet
本文主要的创新点在于仔细研究了点云的结构特点,提出了一种面向原始点云的端到端网络。这里总结的点云结构特点主要有两个:
- 点的
顺序无关性 - 点云的
刚体变换不变性
这里的顺序无关性是指每个点存放在数组中的位置是任意的,因为最终将其映射到三维空间中起作用的是点的 xyz 维度,最终得到的点云是一样的,跟其在数组中的下标是没有关系的。而在传统的处理图像的 CNN 中,像素的下标是很重要的,因为那里主要就是通过下标得到相邻像素的,而不是通过像素在图像中的 uv 位置。
刚体变换不变性比较容易理解了,我们对点云进行旋转平移,其内部的结构是不变的。
实现刚体变换不变性,我们可以先将点云减去质心,然后训练一个 spatial transformer network 得到一个归一化旋转矩阵,将其施加在点云上就可以了。而要想实现顺序无关性,我们只要能找到一个与输入数据顺序无关的对称函数就行了,文章里用的是 maxpool。
网络的主体结构如下所示:
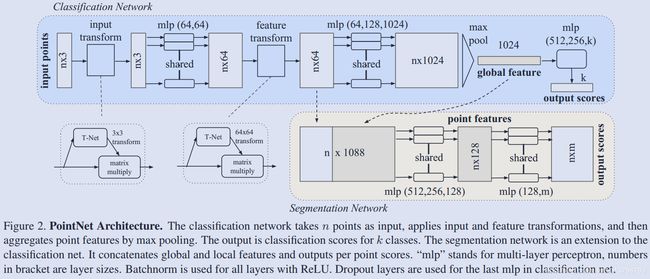
可以看到网络结构还是比较简单的,特征提取主要就是依靠两组 mlp,总共 5 层,其中会训练两个 T-Net 进行旋转归一化,然后直接 max-pool 得到 global feature,继续两层 mlp 然后全连接分类。分割网络也比较简单,就是将 global feature 连接到每个点上,然后再来两组 mlp 进行 pointwise 的分类。
文章还有一系列的训练和数据增强技巧,这里就先不写了。其中在训练 T-Net 的时候还增加了旋转矩阵是正交矩阵的正则项约束。
pointnet++
pointnet++ 主要是解决了 pointnet 没有考虑点云局部结构的问题,这可能导致网络在识别一个细粒度的 pattern 时泛化能力不够,另一方面 pointnet 在训练时会对点云进行均匀采样,着同样会对细粒度的 parttern 有消极的影响。作者提出的解决方法就是增加一个采样分组网络,将点云聚类成 K 个点云簇,也就是说通过点与点之间的空间距离对点云的局部特征进行归类,然后对每个点云簇使用 pointnet 进行特征提取,这样我们就得到了点云在局部的特征了。并且通过组合多层这样的采样/分组/pointnet(set abstraction)网络,set abstraction 的感知野也越来越大,这对提取局部特征是有帮助的。
文中点簇的 centroid 的选取是通过 farthest point sampling 算法选取的。
最终的网络结构如图所示:

可以看到在分类网络上,相当于是将 pointnet 前期的两组 mlp 特征提取用 hierarchical point set feature learning (两组 set abstraction)网络替换掉了;在分割网络上,是将 centroid 的特征分别连接到对应点簇中点云的特征后面,文章说是插值,其实跟之前 pointnet 的做法是类似的。
具体的 centroid 选取和 grouping 操作也有一些不同的效果,作者也做了很多实验,这里就不一一介绍了。其中 multi-scale grouping 是作者最终使用的 grouping 方法,具体操作就是对点簇设置不同的 dropout ratio,然后按照这个 dropout ratio 对点簇中的点进行随机采样,这样就得到了该 dropout ratio 对应的尺度的特征,然后将多个尺度的特征 concatenate 作为该 centroid 的 multi-scale feature。
同时文章也提到了非欧尺度空间的点云分类问题,这在识别行人和动物的时候比较有用,因为这些物体并不是刚性的,做法就是增加一些传统方法获取的非欧特征(intrinsic feature)。
voxelnet
这篇文章是苹果公司的员工发表的,用的方法是 pointnet 作者 diss 的 volumetric CNN 方法,这里也将其介绍一下是因为它的特征提取模块跟 pointnet 思想比较类似,同时里面一些针对自动驾驶的训练技巧和数据增强技巧也值得一学。还有一点是 pointnet 和 pointnet++ 都是在 1k 左右的点云规模上进行训练的,而 lidar 点云一般都在 20k ~ 100k 之间,因此本文也解决了大规模 3D 点云特征学习和检测任务的问题。其网络结构如图所示:

先来介绍下它的 feature learning network,可以看到它首先是将点云按照 voxel 进行分组,随机采样,然后对每个组内的点云(没有归一化到局部,而是将归一化坐标增强到点的特征中)使用 VFE layer 增加每个点云的特征维度,重复多次这个步骤,最后进行一次全连接和 maxpool 得到每个 voxel 的特征。之后就是针对这些 voxel 进行 3D 的 CNN 和 RPN 得到类别和 box了。
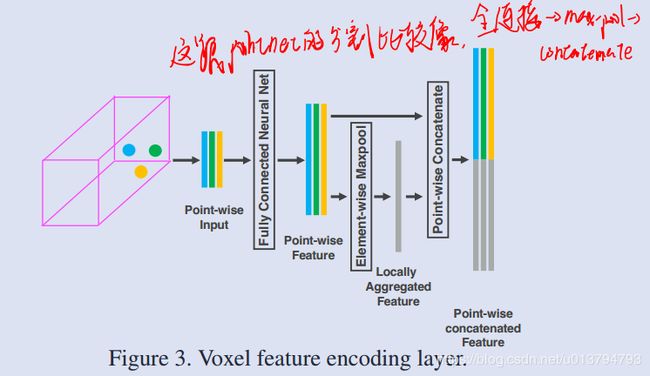
VFE 的结构如上图所示,可以看到跟 pointnet 还是很类似的,就是全连接-maxpool-concatenate,也是比较精简的。
文中的 loss function 也是比较新颖的,通过 box 对角线长度对 center loss 进行了归一化。具体的网络细节、训练技巧和数据增强技巧这里就先不介绍了。
frustum-pointnet
这篇文章思路就比较简单了,只要做过摄像头和激光雷达数据融合的人都很容易能够理解。这篇文章也是作者与 Nuro 公司的员工合作发表的,因此是面向自动驾驶的,最后也是用的 kitti 数据集。同时也利用了很多自动驾驶中的先验信息,例如只关心物体的 yaw 轴朝向。
首先大致的 pipeline 和网络结构如下图所示:
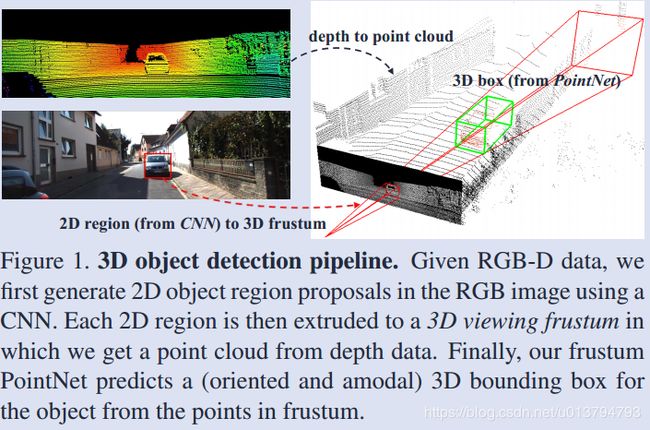
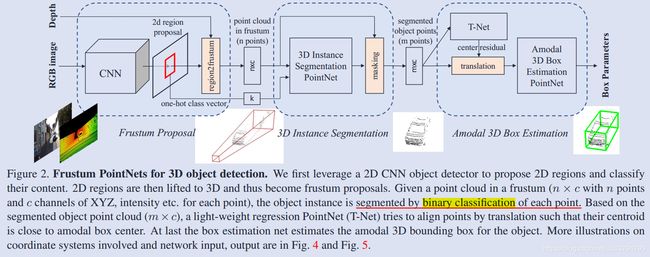
- 利用成熟的图像目标检测将物体检测出来
- 通过相机的投影模型将该 2D bounding box 对应的视锥框出来,框出来的目的就是将对该视锥内部的点云进行二分类,找到属于该物体的点云
- 计算 3D box。这里在计算 3D box 时提到了一个 amodal 的概念比较有意思,就是说人仅通过感知物体的一部分就是能感知出物体的整体。这对激光点云的 3D box 计算是很有帮助的,因为不管是这里的视锥划分还是激光雷达的固有特性,一个被扫描的物体注定只有一部分表面能呈现在点云中,如果只根据这些点云划分 box 很可能是不对的。例如,只有车头被雷达扫描到的 box 可能只包含了车头,但我们应该通过 amodal 的方法将 box 延长一部分,即使延长的这一部分中可能没有该物体的点云。
所以这篇文章的网络有两个,一个用来分割,一个用来回归 bounding box。下面分别简单介绍下 pipleline 中的各个模块。
frustum proposal
这没什么好介绍的,就是图像目标检测,然后将视锥中的点云提取出来,提取出来之后会进行旋转归一化,如下图 b 所示:
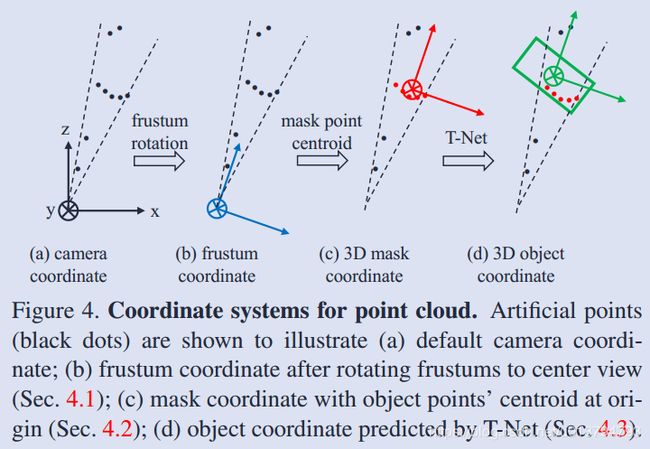
3D instance segmentation
这里提到为什么直接在深度图上用 2D CNN 回归物体位置不可取,因为前景遮挡和背景 clutter 问题,所以这里还是用的 3D segmentation。分割也是用的 pointnet,在分割时利用了上阶段的物体类别信息,就是 concatenate 一个 one-hot class vector。然后将分割的点云进行坐标归一化,如上图 c 所示,文中提到,实验发现上节的旋转归一化和本节的坐标归一化是很重要的
amodal 3D box estimation

这里先通过 T-Net 回归了 amodal box center,如图 4.c 所示,然后再通过一个 amodal 3D box estimation pointnet 来回归 box,如图 5 所示。这里在回归 box 时还是利用了物体物理模型的先验信息,也就是 pre-define NS 个 size 模板和 NH 个朝向模板。并且对物体按照高度、宽度、长度划分成 NS 类,对朝向划分 NH 类。最终网络的输出维度为 3 + 4 * NS + 2 * NH。文中还提到了训练这些 multi-task loss 的技巧,就是增加了一个 corner loss 正则项,将原本独立的 center、长宽高和朝向 loss 联系起来,方法就是构造 NS * NH 个 anchor boxes,然后根据回归的 center 将这些 anchor box 的 corner 旋转平移到 center 对应的 box 上,度量这 8 个 corner 与 ground truth 的 corner 的距离,如下图所示:

其中 δ i j \delta_{ij} δij 表示 ij 的 size/heading 为 ground truth 时为 1,否则为 0;min 函数防止 box flipped 导致的错误 loss。
votenet
这篇文章还是思考的点云物体检测所存在的问题,问题跟 frustum pointnet 里提到的 amodal box 问题比较类似,不过这里不是通过划分多个模板然后将 box 分类到不同的模板中,而是利用霍夫投票这个老方法来解决这里的新问题。不过为了将这个老方法整合到端到端的网络中,作者也对其进行了重新设计。
首先还是看下网络的结构:
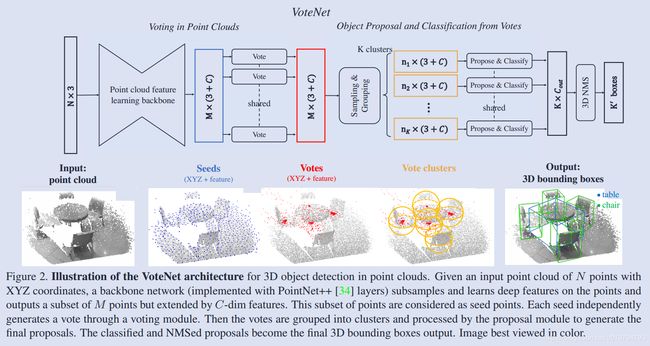
- 使用 pointnet 选取一些 seed 并学习其局部特征,类似 set abstraction layer,每个 seed 产生一个 vote;
- 使用 deep network 产生 votes;
- 对 votes 进行聚类、box proposal 和分类;
- 最后进行一个 3D NMS 得到 box 输出。
文章也介绍了为什么要用霍夫投票:1. 投票比较适合稀疏集合,而点云正是空间稀疏的;2. 投票是自底向上的,局部的信息通过投票聚合成关于物体的全局信息,而神经网络虽然从一个更大的感知野聚合信息,但点云在物体的 amodal center 附近是很少的,直接进行 context aggregation 的话是不好的。
具体的投票网络这里就不仔细介绍了。
reference
- Qi C R, Su H, Mo K, et al. Pointnet: Deep learning on point sets for 3d classification and segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 652-660.
- Qi C R, Yi L, Su H, et al. Pointnet++: Deep hierarchical feature learning on point sets in a metric space[C]//Advances in neural information processing systems. 2017: 5099-5108.
- Qi C R, Liu W, Wu C, et al. Frustum pointnets for 3d object detection from rgb-d data[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 918-927.
- Qi C R, Litany O, He K, et al. Deep Hough Voting for 3D Object Detection in Point Clouds[J]. arXiv preprint arXiv:1904.09664, 2019.
- Zhou Y, Tuzel O. Voxelnet: End-to-end learning for point cloud based 3d object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 4490-4499.