CubeMX生成的STM32F4xx MDK工程FPU和DSP库的使用
CubeMX生成的STM32F4xx MDK工程FPU和DSP库的使用
STM32F4xx属于Cortex M4F架构,带有32位的单精度硬件FPU(Float Point Unit),支持浮点指令集,相对比M0和M3架构,浮点运算性能高出数十倍甚至上百倍。FPU和DSP库的使用网上已经有了好多教程,但好多都是基于正点原子代码操作的,在CubeMX生成的工程中如何使用如何使用上述两种功能,并没有针对性的提及。
一、启动硬件FPU
1、启用FPU简介
此处关键在于对两个重要的全局宏定义进行操作:将 _FPU_PRESENT 和 _FPU_USED 都置1,其中宏定义标识符_FPU_PRESENT用来确认处理是否带有FPU功能,标识符_FPU_USED用来确定是否开启FPU功能。实际上,因为STM32F4是带有FPU功能的,所以在stm32f4xxxx.h头文件中,默认定义_FPU_PRESENT为1。

正常按照条件编译,_FPU_USED,应该被置1,但在core_cm4.h中条件编译会并没有将 _FPU_USED 置1,同时还会报错。
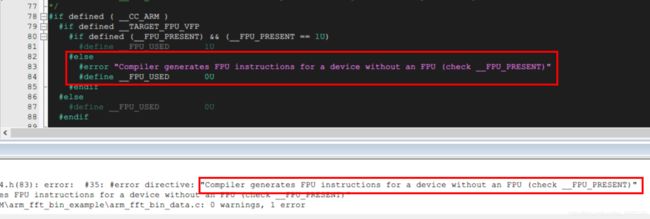
根据条件编译的原理,应该是编译器没有检测到_FPU_PRESENT被定义,于是我将定义_FPU_PRESENT的文件 包含进来,可以看到条件编译已经把 _FPU_USED 置1了
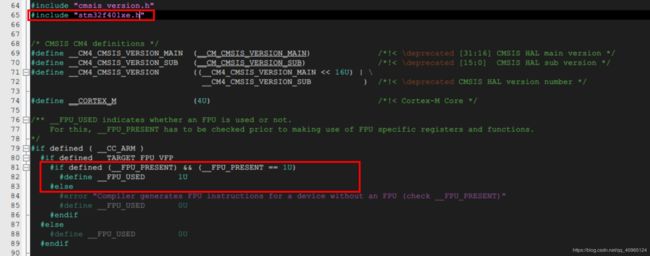
但编译时,不清楚具体的原因会大量报错。下面我就正式讲解一下我解决这个问题的方法。(进入正题)
2、启用FUP方法
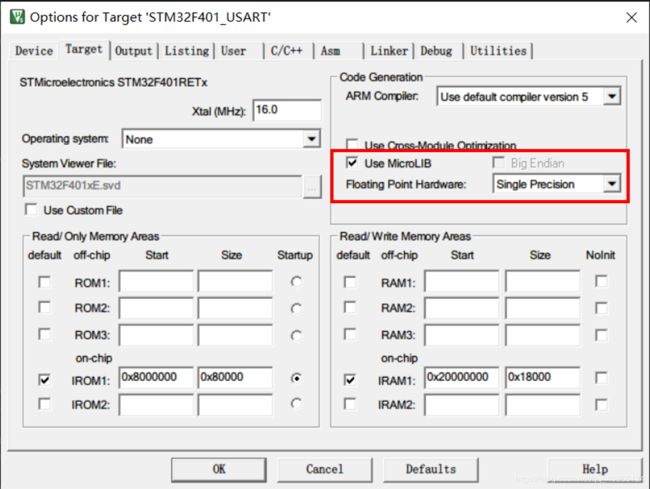
①.首先在Option for Target → Target → Coda Generation中启用FPU。
②.在Option for Target → C/C++ → Define中添加四个宏定义(后三个是用在DSP调用过程中的,此处一并添加了),并将stm32f4xxxx.h头文件中,默认的定义_FPU_PRESENT注释掉。否则__FPU_PRESENT会重复定义。
__FPU_PRESENT=1,__TARGET_FPU_VFP,ARM_MATH_CM4,__CC_ARM
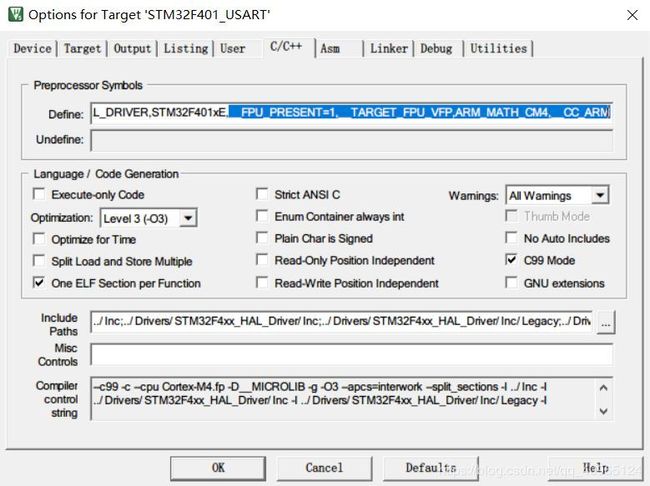
③.编译,到此单片机的硬件FPU便被启用。
二、DSP库的使用
1、DSP库初识
STM32F4的Cortex-M4内核不仅内置硬件FPU单元,还支持DSP多种指令集,比如支持单周期乘加指令(MAC)、优化的单指令多数据指令(SIMD)等。因此Cortex-M4执行所有的DSP指令集都可以在单周期内完成,而Cortex-M3和M0需要多个指令和多个周期才能完成同样的功能。比如开方运算,M3和M0只能通过迭代法(标准数学函数库)计算,而M4F直接调用VSQRT指令完成。
①.DSP库的获取:官网下载,并解压;但使用CubeMX生成MDK工程时,选择添加全部文件,则在生成的工程文件中已将带有DSP的相关文件和库了,不需单独下载。
DSP库路径如下:
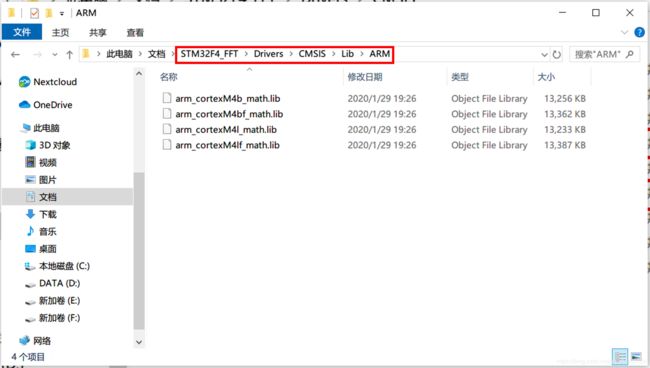
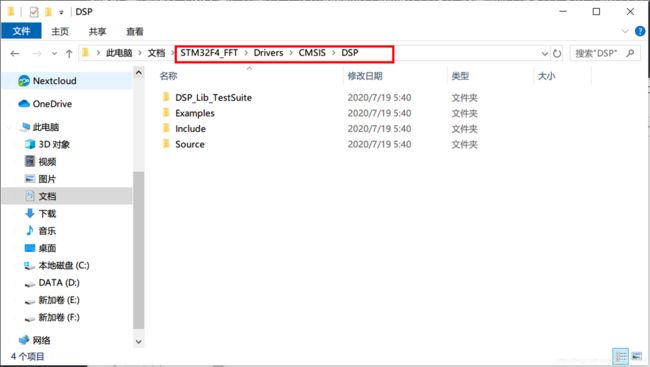
DSP相关文件、例程路径如下:
②.DSP库介绍

DSP库主要包含以下几个分库:
- BasicMathFunctions – 基本数学函数:提供浮点数的各种基本运算函数,如向量加减乘除等运算。
- ommonTables –arm_common_tables.c文件提供位翻转或相关参数表。
- ComplexMathFunctions –复杂数学功能,如向量处理,求模运算的。
- ControllerFunctions –控制功能函数。包括正弦余弦,PID电机控制,矢量Clarke变换,矢量Clarke逆变换等。
- astMathFunctions –快速数学功能函数。提供了一种快速的近似正弦,余弦和平方根等相比CMSIS计算库要快的数学函数。
- ilteringFunctions –滤波函数功能,主要为FIR和LMS(最小均方根)等滤波函数。
- MatrixFunctions –矩阵处理函数。包括矩阵加法、矩阵初始化、矩阵反、矩阵乘法、矩阵规模、矩阵减法、矩阵转置等函数。
- StatisticsFunctions –统计功能函数。如求平均值、最大值、最小值、计算均方根RMS、计算方差/标准差等。
- SupportFunctions –支持功能函数,如数据拷贝,Q格式和浮点格式相互转换,Q任意格式相互转换。
- TransformFunctions –变换功能。包括复数FFT(CFFT)/复数FFT逆运算(CIFFT)、实数FFT(RFFT)/实数FFT逆运算(RIFFT)、和DCT(离散余弦变换)和配套的初始化函数。
2、DSP库的添加
①.在工程中选中DSP库,并添加。 ST提供了.lib格式的文件,方便使用这些库。这些.lib文件就是由Source文件夹下的源码编译生成的,如果想看某个函数的源码,可以在:工程文件夹 → Drivers → CMSIS → DSP → Source文件夹下面查找。
.lib格式文件路径:工程文件夹 → Drivers → CMSIS → Lib。共有四个文件,其中:
arm_cortexM4bf_math.lib(浮点Cortex-M4大端模式)
arm_cortexM4lf_math.lib(浮点Cortex-M4小端模式)
STM32F4的内核CortexM4F采用小端模式,所以选择:arm_cortexM4lf_math.lib(浮点Cortex-M4小端模式)。
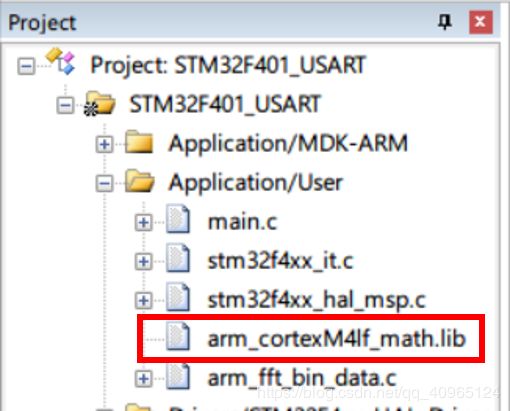
②.添加头文件:路径:工程文件夹 → Drivers → CMSIS → DSP → Include

③.编译,DSP库环境搭建成功,可以调用相关函数进行数字信号处理。