python爬取美团评论
文章目录
- 1.抓包分析
- 1.1网页分析
- 1.2如何进行抓包
- 2.美团爬取
- 2.1爬取第一页
- 2.2爬取所有页数内容
- 3.将爬取内容写入CSV文件中
- 4.代码汇总
1.抓包分析
我在美团随便选择了一家花溪大学城评论多的店铺点评信息进行爬取
店铺链接:https://www.meituan.com/meishi/193383554/
1.1网页分析
在爬取网页内容之前,第一件事就是分析它的网页数据的加载方式,再决定我请求服务器的方式。
该店铺评论不需要登录美团便可以看到,评论文字也可以直接看到,文字没有被加密;我们点击下一页时发现网页的URL没有发生改变,可以初步判断它是ajax加载的数据,所以我们可以通过抓包的方式来获取内容。


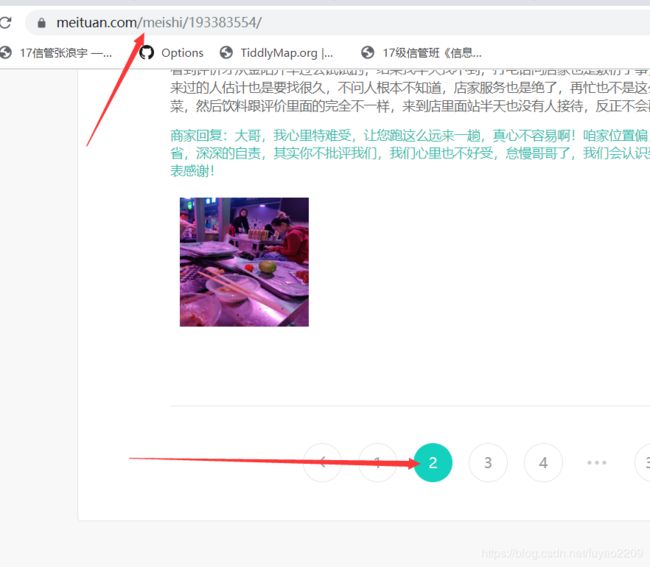
1.2如何进行抓包
1.浏览器的中的每一条信息的加载都离不开 Network ,这就意味着我们可以通过它来查看网页加载出来的内容。
抓包的步骤:
- 鼠标右击,打开检查功能
- 选择Network
- 选择All
- 刷新网页
- 选择文件,查看加载数据

然后我们需要核对一下我们选择的文件是否与上面的网页内容相同,经过比对发现是相同的。
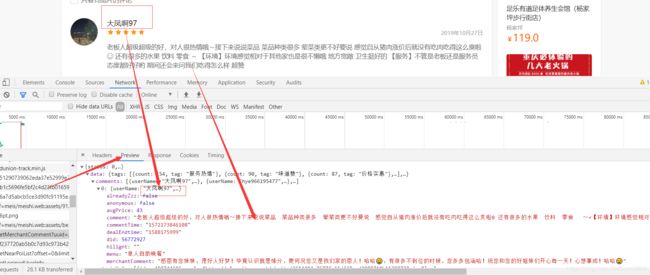
也可以把这些信息复制到一个json数据在线解析的网站上解析一下,就可以看到格式化的内容了


以上就是json解析出来的的内容,我选择的解析网址https://www.json.cn/,可以发现每一页一共有10个用户在评论,说明它每页只加载10个评论与回复。
2.点击第二页,我们会发现,如下图所示多了一个文件,点击打开这个文件,通过检查发现确实是显示第二页的内容。通过同样的方式我们可以获取其他页数的。

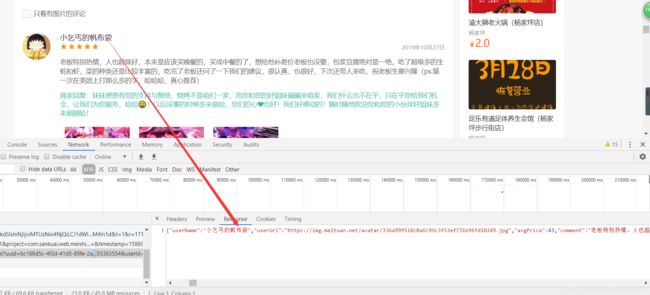
3.选择各页对应的文件,通过如下步骤可以得到对应的链接。


4.我选择了第1、2、3和最后一页的链接进行了比较,它们的参数只有 offset= 不同,并且间隔为10。
2.美团爬取
2.1爬取第一页
1.请求网页
# 请求网页
import requests
ajax_url="https://www.meituan.com/meishi/api/poi/getMerchantComment?uuid=bc168d5c-4f3d-41d5-89fe-2a6c8f1d293d&platform=1&partner=126&originUrl=https%3A%2F%2Fwww.meituan.com%2Fmeishi%2F193383554%2F&riskLevel=1&optimusCode=10&id=193383554&userId=&offset=0&pageSize=10&sortType=1"
#字典型,代理
headers_meituan={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36"
}
response=requests.get(url=ajax_url,headers=headers_meituan)
print(response)
输出结果:
<Response [200]>
返回值为200,请求网页成功,接下来开始进行爬取。
2.获取text内容:
response.text
结果为:
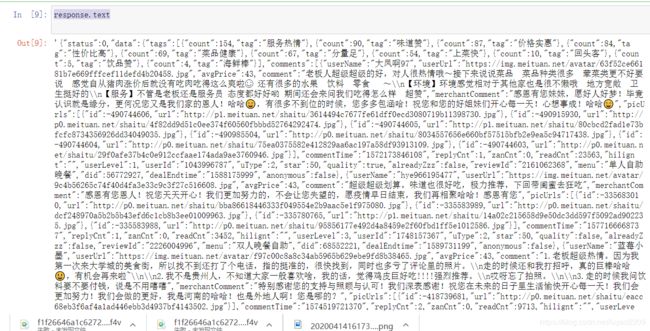
3.获取json内容:
response.json()
结果为:
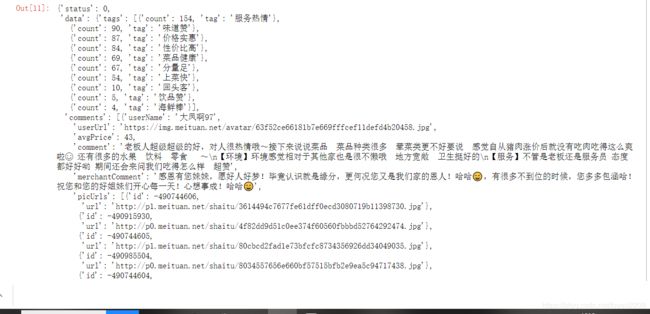
4.获取一级标签data中二级标签comments下的内容

代码:
response.json()["data"]["comments"]
结果为:

5.获取一个用户名
response.json()["data"]["comments"][0]["userName"]
结果:
'大凤啊97'
6.获取本页所有用户名,这里写一个for循环来实现
for item in response.json()["data"]["comments"]:
name=item["userName"]
print(name)
结果:
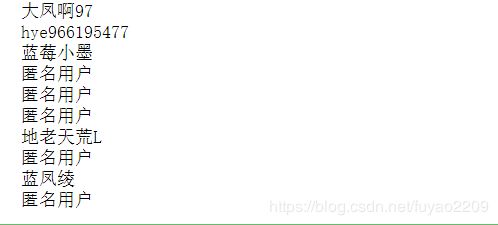
7.获取用户名和评论
for item in response.json()["data"]["comments"]:
name=item["userName"]
comment=item["comment"]
print(name)
print(comment)
结果:

8.获取用户名、用户链接以及评论
for item in response.json()["data"]["comments"]:
name=item["userName"]
comment=item["comment"]
userUrl=item["userUrl"]
print(name)
print(userUrl)
print(comment)
结果:

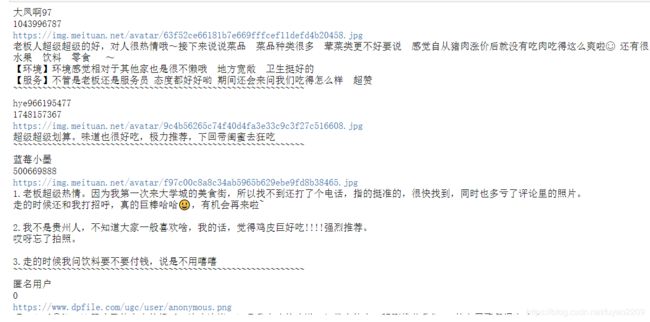
9.获取用户名、用户链接、用户ID以及评论
for item in response.json()["data"]["comments"]:
name=item["userName"]
userId=item["userId"]
comment=item["comment"]
userUrl=item["userUrl"]
print(name)
print(userId)
print(userUrl)
print(comment)
print("~"*60)
结果:
获取其他内容也是一样的方法。
2.2爬取所有页数内容
上面我们有分析过各页文件链接的不同,下面开始爬取。
1.构造链接:
for num in range(0,381,10):
ajax_url="https://www.meituan.com/meishi/api/poi/getMerchantComment?uuid=bc168d5c-4f3d-41d5-89fe-2a6c8f1d293d&platform=1&partner=126&originUrl=https%3A%2F%2Fwww.meituan.com%2Fmeishi%2F193383554%2F&riskLevel=1&optimusCode=10&id=193383554&userId=&offset="+str(num) +"&pageSize=10&sortType=1"
print(ajax_url)
结果:

2.开始爬取,所有代码为:
import requests
#字典型,代理
headers_meituan={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36"
}
for num in range(0,381,10):
ajax_url="https://www.meituan.com/meishi/api/poi/getMerchantComment?uuid=bc168d5c-4f3d-41d5-89fe-2a6c8f1d293d&platform=1&partner=126&originUrl=https%3A%2F%2Fwww.meituan.com%2Fmeishi%2F193383554%2F&riskLevel=1&optimusCode=10&id=193383554&userId=&offset="+str(num) +"&pageSize=10&sortType=1"
print("正在爬取%s条.................."%num)
response=requests.get(url=ajax_url,headers=headers_meituan)
for item in response.json()["data"]["comments"]:
name=item["userName"]
userId=item["userId"]
comment=item["comment"]
userUrl=item["userUrl"]
print(name)
print(userId)
print(userUrl)
print(comment)
print("~"*60)
结果:

3.将爬取内容写入CSV文件中
步骤:
- 打开文件夹
- 放进文件夹
- 关闭文件夹
#导入包
import csv
# 创建文件夹并打开
fp = open("./美团.csv", 'a', newline='', encoding = 'utf-8-sig')
writer = csv.writer(fp) #写入内容
# 写入内容
writer.writerow(( '名称', 'ID', '链接', '评论'))
for item in response.json()["data"]["comments"]:
name=item["userName"]
userId=item["userId"]
comment=item["comment"]
userUrl=item["userUrl"]
result=(name,userId,userUrl,comment)
writer.writerow(result)
#关闭文件
fp.close()
4.代码汇总
import requests
import csv
#字典型,代理
headers_meituan={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36"
}
# 创建文件夹并打开
fp = open("./美团.csv", 'a', newline='', encoding = 'utf-8-sig')
writer = csv.writer(fp) #写入内容
# 写入内容
writer.writerow(( '名称', 'ID', '链接', '评论'))
for num in range(0,381,10):
ajax_url="https://www.meituan.com/meishi/api/poi/getMerchantComment?uuid=bc168d5c-4f3d-41d5-89fe-2a6c8f1d293d&platform=1&partner=126&originUrl=https%3A%2F%2Fwww.meituan.com%2Fmeishi%2F193383554%2F&riskLevel=1&optimusCode=10&id=193383554&userId=&offset="+str(num) +"&pageSize=10&sortType=1"
print("正在爬取%s条.................."%num)
response=requests.get(url=ajax_url,headers=headers_meituan)
for item in response.json()["data"]["comments"]:
name=item["userName"]
userId=item["userId"]
comment=item["comment"]
userUrl=item["userUrl"]
result=(name,userId,userUrl,comment)
writer.writerow(result)
#关闭文件
fp.close()
jupyter结果:

CSV文件截屏:

