使用selenium和pyquery来爬取淘宝ipad商品信息
使用selenium爬取淘宝ipad商品信息
- 爬取过程中的重点是实现翻页、提取商品信息、存储至数据库
访问淘宝
爬取过程中可以通过扫描二维码的方式来登陆淘宝,要注意的是访问不能过于频繁,否则ip会被限制访问。 防止ip被限制访问可以通过使用代理,或者降低访问的频率
1.获取商品的总页数
- 检查其html源码
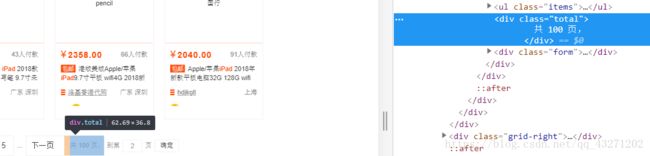
- 可通过CSS选择器来选取总页数,进而获取其总页数
代码如下:
def search(url): # 获取商品的总页数
try:
browser.get(url) # 访问url
browser.maximize_window() # 最大化浏览器
sum = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#mainsrp-pager > div > div > div > div.total')))
# 等待总页数的加载出现
return int(sum.text[1:-2]) # 截取价格的数字部分,第二个元素至倒数第二个元素
# 返回总页数
except TimeoutException:
search(url)
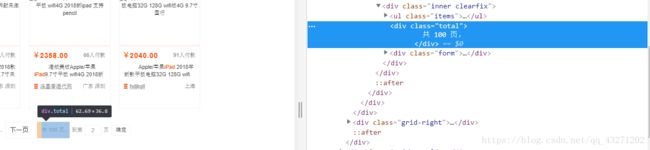
2.实现翻页操作
- 这里通过页数输入框和确定按钮来实现翻页操作,而不是用下一页按钮。因为如果使用下一页按钮的话,需要记录页数,而且如果中间出错的话,无法判别正确页数是哪一个,及后续操作无法进行

- 同样的,通过CSS选择器来选取输入框和确定按钮
input = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > div.form > input')))
# 等待输入框加载出现,并选取
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > div.form > span.btn.J_Submit')))
# 等待确定按钮加载出现(element_to_be_clickable可点击元素,来确定是按钮元素),并选取
- 翻页时,首先清空输入框中的内容,再输入目标页,单击确定按钮,实现翻页
input.clear()
# 清除输入框内容
input.send_keys(page)
# 将要跳转的页数输入到输入框中
submit.click()
# 点击确定按钮
- 翻页之后还需要判断该页是否与我们的目标页是同一页
选取高亮的页码数,与目标页数比较
wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR, '#mainsrp-pager > div > div > div > ul > li.item.active > span'), str(page)))
# 选择高亮的页码数,判断它是否等于我们所跳转的页数(str(page))
接着,在分析源码的时候我们发现,所有的信息都在class值为item的标签之中,所以首先要等在这些源码加载成功,进而在其内通过pyquery提取信息
这里有五个item,内含五个商品的信息(item与之后的内容间隔一个空格,所以选择的时候class属性直接指定为item)
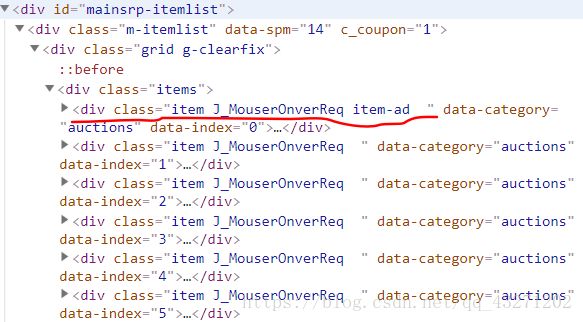
内部信息如下:


提取信息的代码如下:
def get_products():
# 用pyquery解析网页
html = browser.page_source # 获取源码
doc = pq(html) # 生成pyquery对象
items = doc('#mainsrp-itemlist .items .item').items() # items()得到一个可遍历的生成器
for item in items:
product = {
'image': item('.pic').find('img').attr('data-src'), # 提取image
'price': item('.price').text(), # 提取价格
'deal': item('.deal-cnt').text()[:-3], # 截取第一个字符至倒数第三个字符
'location': item('.location').text() # 提取店铺位置
}
print(product) # 打印信息
save_to_mongo(product) # 将提取到的信息存储到MongoDB数据库中
3.将数据存储到MongoDB数据库中
使用pymongo库与MongoDB进行交互
代码如下:
import pymongo
MONGO_URL = 'localhost' # 指定ip地址,localhost本地地址
MONGO_DB = 'taobao' # 指定数据库名
MONGO_TABLE = 'iPad' # 指定数据表名(在mongodb中叫做集合)
client = pymongo.MongoClient(MONGO_URL) # 创建一个MONGODB连接对象
db = client[MONGO_DB] # 连接到MONGO_DB数据库
def save_to_mongo(result): # 将数据导入到数据库中
try:
if db[MONGO_TABLE].insert(result): # 如果在MONGO_DB中插入数据成功,执行print语句
print('保存成功')
except Exception:
print('保存失败')
END…
全部代码如下:
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from pyquery import PyQuery as pq
import time
import pymongo # 导入pymongo库,与mongodb交互
browser = webdriver.Firefox() # 创建火狐浏览器对象
wait = WebDriverWait(browser, 10) # 创建等待对象,最大等待时间10s,超过10s抛出TimeOutException异常
MONGO_URL = 'localhost' # 指定ip地址,localhost本地地址
MONGO_DB = 'taobao' # 指定数据库名
MONGO_TABLE = 'iPad' # 指定数据表名(在mongodb中叫做集合)
def search(url): # 获取商品的总页数
try:
browser.get(url) # 访问url
browser.maximize_window() # 最大化浏览器
sum = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#mainsrp-pager > div > div > div > div.total')))
# 等待总页数的加载出现
return int(sum.text[1:-2])
# 返回总页数
except TimeoutException:
search(url)
def index_page(page): # 换页,跳转正第page页
try:
if page > 1:
input = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > div.form > input')))
# 等待输入框加载出现,并选取
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > div.form > span.btn.J_Submit')))
# 等待确定按钮加载出现(element_to_be_clickable可点击元素,来确定是按钮元素)
input.clear()
# 清除输入框内容
input.send_keys(page)
# 将要跳转的页数输入到输入框中
submit.click()
# 点击确定按钮
wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR, '#mainsrp-pager > div > div > div > ul > li.item.active > span'), str(page)))
# 选择高亮的页码数,判断它是否等于我们所跳转的页数
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#mainsrp-itemlist .items .item')))
# 等待商品信息的加载
get_products() # 获取商品信息
except TimeoutException:
index_page(page)
def get_products():
# 用pyquery解析网页
html = browser.page_source
doc = pq(html)
items = doc('#mainsrp-itemlist .items .item').items() # items()得到一个可遍历的生成器
for item in items:
product = {
'image': item('.pic').find('img').attr('data-src'),
'price': item('.price').text(),
'deal': item('.deal-cnt').text()[:-3], # 截取第一个字符至倒数第三个字符
'location': item('.location').text()
}
print(product)
save_to_mongo(product) # 将提取到的信息存储到MongoDB数据库中
client = pymongo.MongoClient(MONGO_URL) # 创建一个MONGODB连接对象
db = client[MONGO_DB] # 连接到MONGO_DB数据库
# 数据导入数据库中
def save_to_mongo(result):
try:
if db[MONGO_TABLE].insert(result): # 如果在MONGO_DB中插入数据成功,执行print语句
print('保存成功')
except Exception:
print('保存失败')
def main():
try:
url = 'https://s.taobao.com/search?q=iPad'
total = search(url)
for i in range(1, total + 1):
index_page(i)
except Exception: # Exception 异常的父类
print('error!')
if __name__ == '__main__':
main()