others-regex正则表达式
title: others-regex正则表达式
categories: Others
tags: [regex, 记录]
date: 2018-11-29 18:16:18
comments: false
mathjax: true
toc: true
按照一定的 规则 去 搜索/查找/捕获/替换, 写工具非常好使. 我最常使用于 Python 写工具, 其次是 csharp, lua, c++. 不同语言的写法大同小异, 只是换个语言工具去写而已.
前篇
-
语法参考 - http://www.runoob.com/regexp/regexp-syntax.html
-
练习测试正则的网站 - https://regex101.com/
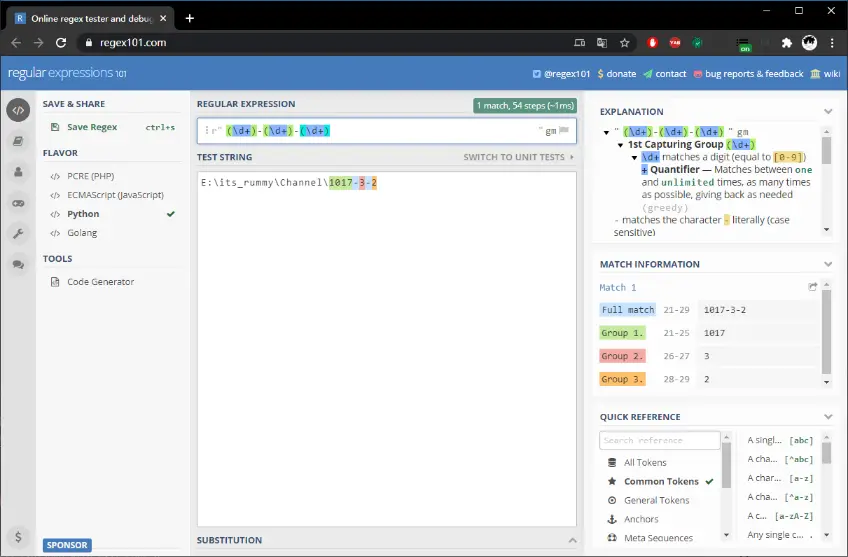
非打印字符
非打印字符也可以是正则表达式的组成部分。下表列出了表示非打印字符的转义序列:
| 字符 | 描述 |
|---|---|
| \cx | 匹配由x指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 ‘c’ 字符。 |
| \f | 匹配一个换页符。等价于 \x0c 和 \cL。 |
| \n | 匹配一个换行符。等价于 \x0a 和 \cJ。 |
| \r | 匹配一个回车符。等价于 \x0d 和 \cM。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。注意 Unicode 正则表达式会匹配全角空格符。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \t | 匹配一个制表符。等价于 \x09 和 \cI。 |
| \v | 匹配一个垂直制表符。等价于 \x0b 和 \cK。 |
特殊字符
所谓特殊字符,就是一些有特殊含义的字符,如上面说的 runoo*b 中的 ,简单的说就是表示任何字符串的意思。如果要查找字符串中的 * 符号,则需要对 * 进行转义,即在其前加一个 : runo*ob 匹配 runoob。
许多元字符要求在试图匹配它们时特别对待。若要匹配这些特殊字符,必须首先使字符"转义",即,将反斜杠字符\ 放在它们前面。下表列出了正则表达式中的特殊字符:
| 特别字符 | 描述 |
|---|---|
| $ | 匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则 $ 也匹配 ‘\n’ 或 ‘\r’。要匹配 $ 字符本身,请使用 $。 |
| ( ) | 标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。要匹配这些字符,请使用 ( 和 )。 |
| * | 匹配前面的子表达式零次或多次。要匹配 * 字符,请使用 *。 |
| + | 匹配前面的子表达式一次或多次。要匹配 + 字符,请使用 +。 |
| . | 匹配除换行符 \n 之外的任何单字符。要匹配 . ,请使用 . 。 |
| [ | 标记一个中括号表达式的开始。要匹配 [,请使用 [。 |
| ? | 匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。要匹配 ? 字符,请使用 ?。 |
| \ | 将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。例如, ‘n’ 匹配字符 ‘n’。’\n’ 匹配换行符。序列 ‘\’ 匹配 “”,而 ‘(’ 则匹配 “(”。 |
| ^ | 匹配输入字符串的开始位置,除非在方括号表达式中使用,此时它表示不接受该字符集合。要匹配 ^ 字符本身,请使用 ^。 |
| { | 标记限定符表达式的开始。要匹配 {,请使用 {。 |
| | | 指明两项之间的一个选择。要匹配 |,请使用 |。 |
限定符
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 “z” 以及 “zoo”。* 等价于{0,}。 |
|---|---|
| + | 匹配前面的子表达式一次或多次。例如,‘zo+’ 能匹配 “zo” 以及 “zoo”,但不能匹配 “z”。+ 等价于 {1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,“do(es)?” 可以匹配 “do” 、 “does” 中的 “does” 、 “doxy” 中的 “do” 。? 等价于 {0,1}。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,‘o{2}’ 不能匹配 “Bob” 中的 ‘o’,但是能匹配 “food” 中的两个 o。 |
| {n,} | n 是一个非负整数。至少匹配n 次。例如,‘o{2,}’ 不能匹配 “Bob” 中的 ‘o’,但能匹配 “foooood” 中的所有 o。‘o{1,}’ 等价于 ‘o+’。‘o{0,}’ 则等价于 ‘o*’。 |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,“o{1,3}” 将匹配 “fooooood” 中的前三个 o。‘o{0,1}’ 等价于 ‘o?’。请注意在逗号和两个数之间不能有空格。 |
由于章节编号在大的输入文档中会很可能超过九,所以您需要一种方式来处理两位或三位章节编号。限定符给您这种能力。下面的正则表达式匹配编号为任何位数的章节标题:
/Chapter [1-9][0-9]*/
请注意,限定符出现在范围表达式之后。因此,它应用于整个范围表达式,在本例中,只指定从 0 到 9 的数字(包括 0 和 9)。
这里不使用 + 限定符,因为在第二个位置或后面的位置不一定需要有一个数字。也不使用 ? 字符,因为使用 ? 会将章节编号限制到只有两位数。您需要至少匹配 Chapter 和空格字符后面的一个数字。
如果您知道章节编号被限制为只有 99 章,可以使用下面的表达式来至少指定一位但至多两位数字。
/Chapter [0-9]{1,2}/
上面的表达式的缺点是,大于 99 的章节编号仍只匹配开头两位数字。另一个缺点是 Chapter 0 也将匹配。只匹配两位数字的更好的表达式如下:
/Chapter [1-9][0-9]?/
或
/Chapter [1-9][0-9]{0,1}/
定位符
定位符使您能够将正则表达式固定到行首或行尾。它们还使您能够创建这样的正则表达式,这些正则表达式出现在一个单词内、在一个单词的开头或者一个单词的结尾。
定位符用来描述字符串或单词的边界,^ 和 $ 分别指字符串的开始与结束,\b 描述单词的前或后边界,\B 表示非单词边界。
正则表达式的定位符有:
| 字符 | 描述 |
|---|---|
| ^ | 匹配输入字符串开始的位置。如果设置了 RegExp 对象的 Multiline 属性,^ 还会与 \n 或 \r 之后的位置匹配。 |
| $ | 匹配输入字符串结尾的位置。如果设置了 RegExp 对象的 Multiline 属性,$ 还会与 \n 或 \r 之前的位置匹配。 |
| \b | 匹配一个单词边界,即字与空格间的位置。 |
| \B | 非单词边界匹配。 |
正向匹配
?=
function testReg02() {
//正向前瞻,匹配.jpg后缀文件名
var str = '123.jpg,456.gif,abc.jpg';
var partern = /\w+(?=\.jpg)/g; //正向前瞻匹配
console.log(str.match(partern)); //['123', 'abc'] 返回结果正确,没有匹配456.gif
}
反向匹配
?!
function testReg03() {
//反向前瞻,匹配3个及以上的a,而且后面不能有000的字符
var str = 'aaa000 aaaa111 aaaaaaa222';
var partern = /a{3,}(?!000)/g; //反向前瞻匹配
console.log(str.match(partern)); //['aaaa', 'aaaaaaa'] 返回结果正确,没有匹配aaa000
}
二:RegExp理解
RegExp有很多属性:
- global 表示全局g是否设置
- ignoreCase 表示i忽略大小是否设置
- lastIndex 表示下次匹配将会从哪个位置开始(只有用了test,exec,match这些方法后才会有值,否则为0)
- multiline 表示多行m是否设置
- source 表示正则表达式的源字符串形式
不同语言单元测试用例
Python
写工具用的最多的语言, 库多, 效率高
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import functools
import sys
import traceback
import os
import string
import re
import glob
import gzip
import tarfile
import shutil
from optparse import OptionParser
from operator import itemgetter
from datetime import datetime
from pathlib import Path
import requests
import json
import platform
import unittest
import tool.utils as utils
SelfPath: str = os.path.abspath(os.path.dirname(__file__))
sys.path.append(SelfPath)
desktopPath = "{}/Desktop".format(str(Path.home()))
# 在线正则
# 参考: https://zhuanlan.zhihu.com/p/42944600
############## 基本字符类s
# \d 数字匹配符 digit
# \D 匹配除了0~9的字符
# \s 空格匹配符,包括\t\s\n\r\f\v
# \S 匹配除了空格的字符
# \w 匹配 字母,数字或下划线字符
# \W 匹配 除了 字母,数字或下划线字符
# \b 边界匹配符,匹配数字字母与符号的边界
# \B 匹配数字字母与数字字母边界以及符号与符号边界
# . 万能匹配符,匹配一切除了\n换行符
############## 规则类
# ^ 开头符
# $ 结尾符
# | 或运算
# + 1+次
# * 0+次
# ? 非贪心字符,0和1次
# 搭配使用 *?或+?表示非贪心,第一次匹配上就停止,0909090用09+?匹配到09,09+则匹配到090909
# {m,n} 匹配m到n次,{m,}匹配m+,{,n}匹配0~n次
############## 多重匹配
# [ ] 匹配括号内字符
# [a-z] - 代表a到z的所有字符
# [+*()]匹配符号时不用加\
# [^ab] ^代表取反,不代表开头
############## 分组获取与顺序要求
# ( ) 匹配括号内的表达式并捕获其内容
# (?:A) 匹配A但不捕获
# (?#...) 给匹配给注释说明
# A(?=B) 匹配A,A在B前
# A(?!B) 匹配A,不在B前的A
# (?<=A)B 匹配B,B在A后
# (?
# (...)\1 代表第一个Group
class Test_Regex(unittest.TestCase):
def setUp(self):
print("\n\n------------------ test result ------------------")
def test_flags(self):
flags = re.M | re.I # 可选项
def test_findall(self):
mystr = "message Role { aaaa\n"
mystr += "message Action { bbb"
arr = re.findall(r"message\s*(.+?)\s*\{\s*(\w*)", mystr) # 如果捕获不到, 返回 空数组 []
print("arr:", arr) # arr: [('Role', 'aaaa'), ('Action', 'bbb')]
mystr = "090909"
match = re.search(r"(09)+?", mystr)
print(match.group(0)) # 09
match = re.search(r"(09)+", mystr)
print(match.group(0)) # 090909
def test_findall2(self):
path = "E:/its_rummy/Channel/1011-3-2/cfg.json"
arr = re.findall("Channel/(.+?)-\d-\d/cfg.json", path) # 捕获
print("--- arr:", arr)
def test_findall3(self):
# (?:xxx|www) 是匹配 xxx 或者 www, 但是不会捕获, 应为有 ?:
path = "E:/its_rummy/Channel/1011-3-2/cfg.json\nE:/its_rummy/Plat/1012-3-2/cfg.apk"
arr = re.findall("(?:Channel|Plat)/(.+?)-\d-\d/cfg\.(?:json|apk)", path) # 捕获
print("--- arr:", arr) # ['1011', '1012']
def test_findallByPattern(self):
pattern = re.compile(r"\d+") # 查找数字
result1 = pattern.findall("runoob 123 google 456")
result2 = pattern.findall("run88oob123google456", 0, 10) # 指定搜索位置 起点,终点
print("--- result1:", result1) # ['123', '456']
print("--- result2:", result2) # ['88', '12']
def test_ip(self):
txt = 'kkk 192.168.1.136 kkk 192.168.1.137 kk 192.168.1.138 kk'
arr = re.findall('(\d+\.\d+\.\d+\.\d+)', txt)
print(arr)
def test_catch(self):
txt = 'Today is 11/27/2012. PyCon starts 3/13/2013.'
print("--- txt:", txt)
content = re.sub(r'(\d+)/(\d+)/(\d+)', r'\3-\1-\2', txt) # 将捕获到元素用 \1, \2, ... 表示
# content = utils.replace(txt, r'(\d+)/(\d+)/(\d+)', r'\3-\1-\2')
print("--- content:", content) # Today is 2012-11-27. PyCon starts 2013-3-13.
def test_replace(self):
txt = "wosdfe_aaa_esdfeb+bbbbb+esdfe"
print("--- txt:", txt)
content = utils.replace(txt, "aaa", "wolegequ")
print("--- content:", content) # wosdfe_wolegequ_esdfeb+bbbbb+esdfe
content2 = utils.replace(txt, "_(\w+)_", "_nice_")
print("--- content2:", content2) # wosdfe_nice_esdfeb+bbbbb+esdfe
filePath = os.path.join(utils.getDesktop(), "aaa\\//")
print("--- filePath:", filePath)
filePath = re.sub(r'[/\\]+$', "", filePath)
print("--- filePath:", filePath)
def test_replace_lambda(self):
# 使用捕获值, 重新组合成新字符串
txt = "wosdfe_aaa_esdfeb+bbbbb+esdfe"
content = re.sub(r'(_)(\w+)(_)', lambda m: "{}{}{}".format(m.group(1), "ccc", m.group(3)), txt)
print("--- content:", content) # wosdfe_ccc_esdfeb+bbbbb+esdfe // 使用原有的数据
# lambda 的返回值会替换 匹配串, m 又可以获取到捕获值
# 批量替换
def test_replaceBatch(self):
repMap = {
"aaa": "111",
"bbb": "222",
}
txt = "wosdfe_aaa_esdfeb+bbbbb+esdfe"
print("--- txt:", txt)
rep = dict((re.escape(k), v) for k, v in repMap.items())
pattern = re.compile("|".join(rep.keys()))
content = pattern.sub(lambda m: rep[re.escape(m.group(0))], txt)
print("--- content:", content) # wosdfe_111_esdfeb+222bb+esdfe
content2 = utils.replaceBatch(txt, repMap)
print("--- content2:", content2) # wosdfe_111_esdfeb+222bb+esdfe
# 批量 匹配 并替换: 貌似只能先通过 匹配模式匹配到 内容, 再构建 内容 替换的映射表
def test_search(self):
# 参考:
# https://www.linuxprobe.com/python3-regular-expressions.html
# re.search 扫描整个字符串并返回第一个成功的匹配。
# re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
print()
txt = 'www.runoob.com.cn, www.wolegequ.com'
match = re.search(r'\.(.*?)\.', txt) # 直到找到一个匹配
if match is not None:
print("-- string:", match.string) # www.runoob.com.cn # src string
# 0 是 full match 结果
begin, end = match.span(0)
print("--- span 0, begin: {}, end:{}, bc: {}, ec: {}"
.format(begin, end, txt[begin], txt[end])) # begin: 3, end:11, bc: ., ec: c
print("--- group 0:", match.group(0)) # .runoob.
# 1 之后的就是捕获的结果
begin, end = match.span(1)
print("--- span 1, begin: {}, end:{}, bc: {}, ec: {}"
.format(begin, end, txt[begin], txt[end])) # begin: 4, end:10, bc: r, ec: .
print("--- group 1:", match.group(1)) # runoob
print("-- groups, len:{}, res: {}".format(len(match.groups()), match.groups())) # len:1, res: ('runoob',)
# 如果遇到需要动态拼接的参数, 可以用 %s, %d 的方式, 用 {}.format 会报错
enumName = "hello"
csEnumTxt = "sdfsdfsdf"
match = re.search(r"public enum EPlatId.*\{[\s\S]*(%s\s*=\s*\d+).*[\s\S]*" % enumName, csEnumTxt)
def test_search_any(self):
# [\s\S]* 可以匹配任意字符, 包括 空格换行, 而 .* 遇到 空格/换行 就中断
txt = "---sdfsdf\nccc\ddd---"
match = re.search(r'---([\s\S]*)---', txt)
print("--- match:", match.group(1))
def test_match(self):
# re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
print(re.match('www', 'www.runoob.com').span()) # 在起始位置匹配, (0, 3)
print(re.match('com', 'www.runoob.com')) # 不在起始位置匹配, None
csharp
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Text.RegularExpressions;
// 参考
/*
- C# 正则表达式 - https://www.runoob.com/csharp/csharp-regular-expressions.html
原文链接:https://blog.csdn.net/qq_38507850/article/details/79179128
(1)"\d"这个符号代表从0-9的数字字符。
(2)"\w"代表所有单词字符,包括:大小写字母a-z、数字0-9、汉字(其实我认为是各国文字字符都可以但是身为中国人应该只用到了汉字)、下划线。
(3)"\s"代表任何空白字符,所谓空白字符就是打出来是空白的字符,包括:空格、制表符、换页符、换行符、回车符等等。
(4)"\D"代表任何非数字字符。
(5)"\W"代表任何非单词字符。
(6)"\S"代表任何非空白字符。
(7)"."代表除换行符(\n)之外的任何字符。
*/
public class TestRegex {
private static void test_catch() {
string txt1 = "紫色版-7-123";
Match mth1 = new Regex(@"-(\d+)-(\d+)").Match(txt1);
Console.WriteLine("--- is match ok: {0}, cnt: {1}", mth1.Success, mth1.Groups.Count); // is match ok: True, cnt: 3
if (mth1.Success) {
Console.WriteLine("platId0: {0}", mth1.Groups[0].Value); // -7-123
Console.WriteLine("platId1: {0}", mth1.Groups[1].Value); // 7
Console.WriteLine("platId2: {0}", mth1.Groups[2].Value); // 123
}
Match mth2 = new Regex(@"-(?:\d+)-(\d+)").Match(txt1); // ?: 表示只是匹配, 但不捕获
Console.WriteLine("--- is match ok: {0}, cnt: {1}", mth2.Success, mth2.Groups.Count); // is match ok: True, cnt: 2
if (mth2.Success) {
Console.WriteLine("platId0: {0}", mth2.Groups[0].Value); // -7-123
Console.WriteLine("platId1: {0}", mth2.Groups[1].Value); // 123
Console.WriteLine("platId2: {0}", mth2.Groups[2].Value); // ""
}
string txt2 = "23794大富科世纪东方了[email protected]@163.comsdfjsd [email protected]*&*&*2";
MatchCollection mths1 = new Regex(@"[a-zA-Z0-9]+@[a-zA-z0-9]+\.com").Matches(txt2);
foreach (Match match in mths1) {
Console.WriteLine("--- mth: {0}", match);
}
string txt3 = "[email protected] [email protected]";
MatchCollection mths2 = new Regex(@"([a-zA-Z0-9_]+)@([a-zA-Z0-9]+)\.com").Matches(txt3);;
Console.WriteLine("--- cnt: {0}", mths2.Count);
for (int i = 0; i < mths2.Count; i++) {
Console.WriteLine("匹配到的第 {0} 个邮箱结果是 {1},对应用户名是 {2}, 邮箱域名: {3}", i + 1, mths2[i], mths2[i].Groups[1].Value, mths2[i].Groups[2].Value);
}
}
private static void test_replace() {
string txt1 = "紫色版-7-123";
string res1 = new Regex(@"-(\d+)").Replace(txt1, "wolegequ", 1); // 1 表示只替换一次, -1 表示所有
Console.WriteLine("--- res1: {0}", res1); // res1: 紫色版wolegequ-123
string res2 = new Regex(@"-(\d+)").Replace(txt1, (mth) => {
Console.WriteLine("--- mth: {0}", mth.ToString()); // mth: -7, mth: -123
return "hello";
});
Console.WriteLine("--- res2: {0}", res2); // res2: 紫色版hellohello
}
public static void main() {
// test_catch();
test_replace();
}
}
lua
-- 参考
-- Lua的字符串匹配与正则表达式 - https://www.cnblogs.com/meamin9/p/4502461.html
--[[
-------- 字符
. 匹配任意字符 Ka.a Kana
% 转义字符, 等价于 Python 中的 \,改变后一个字符的原有意思。当后面的接的是特殊字符时,将还原特殊字符的原意。%和一些特定的字母组合构成了lua的预定义字符集。%和数字1~9组合表示之前捕获的分组
[...] 字符集(字符类)。匹配一个包含于集合内的字符。[...]中的特殊字符将还原其原意,但有下面几种特殊情况
1. %],%-,%^作为整体表示字符']','-','^'
2. 预定义字符集作为一个整体表示对应字符集
3. 当]位于序列的第一个字符时只表示字符']'
4. 形如[^...],[...-...]有特定的其他含义
[...-...] -表示ascii码在它前一个字符到它后一个字符之间的所有字符 [a-z]a na
[^...] 不在...中的字符集合。 [^0-9]na
[^^0-9]na Kna
Kna
-------- 重复(数量词)
* 表示前一个字符出现0次或多次 [0-9]*
[a-z]*9* 2009
na
+ 表示前一个字符出现1次或1次以上 n+[0-9]+ n2009
? 表示前一个字符出现0次或1次 n?[0-9]+ 2009
-------- 预定义字符集
%s 空白符[ \r\n\t\v\f] an[%s]?9 an 9
%p 标点符号 an[%p]9 an.9
%c 控制字符
%w 字母数字[a-zA-Z0-9] [%w]+ Kana9
%a 字母[a-zA-Z] [%a]* Kana
%l 小写字母[a-z] -
%u 大写字母[A-Z] -
%d 数字[0-9] -
%x 16进制数[0-9a-fA-F] -
%z ascii码是0的字符 -
分组
(...) 表达式中用小括号包围的子字符串为一个分组,分组从左到右(以左括号的位置),组序号从1开始递增。 ab(%d+)
(%d+)%1 ab233
123123
-------- 边界匹配(属于零宽断言)
^ 匹配字符串开头 ^(%a)%w* abc123
$ 匹配字符串结尾 %w*(%d)$ abc123
%b
%bxy 平衡匹配(匹配xy对)。这里的x,y可以是任何字符,即使是特殊字符也是原来的含义,匹配到的子串以x开始,以y结束,并且如果从x开始,每遇到x,计算+1,遇到y计数-1,则结束的y是第一个y使得计数等于0。就是匹配成对的符号,常见的如%b()匹配成对的括号 %b()
%d+%b() (3+4(x*2))
2(3+4(x*2))
]]
local function test_find()
-- api: string.find(s, pattern[, init[, plain]])
-- 在字符串s中匹配pattern,如果匹配成功返回第一个匹配到的子串的起始索引和结束索引,如果pattern中有分组,分组匹配的内容也会接着两个索引值之后返回。如果匹配失败返回nil。
-- 可选数值参数init表示从s中的哪个索引位置开始匹配,缺省值是1,可以为负索引。
-- 1. 在字符串s中匹配pattern,如果匹配成功返回第一个匹配到的子串的起始索引和结束索引,如果pattern中有分组,分组匹配的内容也会接着两个索引值之后返回。如果匹配失败返回nil。
-- 2. 可选数值参数init表示从s中的哪个索引位置开始匹配,缺省值是1,可以为负索引。
-- 3. 可选布尔值参数plain为true时,pattern作为普通字符串匹配,所有正则中的元字符都只被作为普通字符解析。(这个参数并不是匹配字符串的结束索引)
print("--- res1:", string.find("Hanazawa Kana", "na"))
print("--- res2:", string.find("Hanazawa Kana", "[%a]+"))
print("--- res3:", string.find("2015-5-12 13:53", "(%d+)-(%d+)-(%d+)")) -- 可以捕获
print("--- res4:", string.find("2015-5-12 13:53", "(%d+)-(%d+)-(%d+)", 1, true))
print("--- res5:", string.find("%a1234567890%a", "%a", 3, true))
--- res1: 3 4
--- res2: 1 8
--- res3: 1 9 2015 5 12 // 返回 开始 结束 下标 和 捕获到的值
--- res4: nil
--- res5: 13 14
end
local function test_match()
-- api: string.match(s, pattern[, init])
-- 在字符串s中匹配pattern,如果匹配失败返回nil。否则,当pattern中没有分组时,返回第一个匹配到的子串;当pattern中有分组时,返回第一个匹配到子串的分组,多个分组就返回多个。可选参数init表示匹配字符串的起始索引,缺省为1,可以为负索引。
print("--- res1:", string.match("2015-5-12 13:53", "%d+-%d+-%d+")) -- 只返回 匹配串
print("--- res2:", string.match("2015-5-12 13:53", "(%d+)-(%d+)-(%d+)")) -- 只返回 捕获
print("--- res3:", string.match("2015-5-12 13:53", "((%d+)-(%d+)-(%d+))")) -- // 返回 匹配串 和 捕获
--- res1: 2015-5-12
--- res2: 2015 5 12
--- res3: 2015-5-12 2015 5 12
end
local function test_gmatch()
-- api: string.gmatch(s, pattern)
-- 返回一个迭代器。每当迭代器调用时,返回下一个匹配到的子串,如果pattern中有分组,返回的是子串对应的分组。gmatch也可以用find和循环来实现。
print("\n--- res1:")
for s in string.gmatch("2015-5-12 22:20", "%d+") do
print(s)
end
--[[
--- res1:
2015
5
12
22
20
]]
print("\n--- res2:")
for s in string.gmatch("Hanazawa Kana", "a(%a)a") do
print(s)
end --找出形如“a字母a”中间的字母
--[[
--- res2:
n
w
n
]]
print("\n--- res3:")
for k, v in string.gmatch("a=214,b=233", "(%w+)=(%w+)") do
print(k, v)
end
--[[
--- res3:
a 214
b 233
]]
end
local function test_gsub()
-- api: string.gsub(s, pattern, repl[, n])
-- 替换字符串函数!这个功能应该是字符串处理中实用性最强的一个。
-- 把字符串中用模式pattern匹配到的所有子串替换为repl指代的子串,返回替换后的字符串和替换的次数。可选数值参数n表示最多可替换的次数。
-- 参数repl可以是正则表达式,也可以是函数。当repl是函数时,函数的参数是模式pattern捕获的子串,和match类似,有分组返回分组,无分组返回整个子串。函数最后应该返回一个字符串。如果repl是正则表达式,可以用分组序号引用匹配到的分组。
print("--- res1:", string.gsub('Hanazawa-Kana', 'na', 'nya'))
print("--- res2:", string.gsub('Hanazawa-Kana', '(n)(a)', '%1y%2')) -- %1 获取到第一个捕获到的值
print("--- res3:", string.gsub('Hanazawa-Kana', 'na', function(s) -- 每次匹配到都会执行这个放回, 用返回值替换掉, s 就是匹配到的值
print("s3: ", s)
return string.sub(s,1,1)..'y'..string.sub(s,2,2)
end))
print("--- res4:", string.gsub('Hanazawa-Kana', '(n)(a)', function(a,b) -- a, b 对应捕获到的值
print("s4: ", a, b)
return a..'y'..b
end))
--- res1: Hanyazawa-Kanya 2 -- 2 表示替换的个数
--- res2: Hanyazawa-Kanya 2
-- s3: na
-- s3: na
--- res3: Hanyazawa-Kanya 2
-- s4: n a
-- s4: n a
--- res4: Hanyazawa-Kanya 2
end
--[[
lua中的魔法字符有 ( ) . % + - * ? [ ] ^ $ ,在表示它们时候要考虑用到转义,转义符号为%
https://blog.csdn.net/ma2595162349/article/details/71941361
]]
-- 添加搜索路径
local path = debug.getinfo(1, "S").source
path = string.sub(path, 2, -1) -- 去掉开头的"@"
path = string.gsub(path, '\\', '/')
path = string.match(path, "(.*)/")
path = path .. "/?.lua"
package.path = package.path .. ";" .. path
require "tool.functions"
dump = require "tool.dump"
local function test_findStr001()
local url = "https://play.google.com/store/apps/details?id=com.rmg.rummy"
local flag = "https://play.google.com/store/apps/details%?id="
local firstIndex, lastIndex = string.find(url, flag)
print("--- firstIndex:", firstIndex)
print("--- lastIndex:", lastIndex)
-- local _, lastIndex = string.find(url, flag)
-- print("--- sss:", string.sub(url, lastIndex + 1, string.len(url)))
-- local input = "opencmd:logaaaaaaaaaaaa2 bbb ccc"
-- local flag = "opencmd:"
-- local _, lastIndex = string.find(input, flag)
-- if lastIndex then
-- cmd = string.sub(input, lastIndex + 1, string.len(input))
-- print("--- cmd:", cmd)
-- local tbl = string.split(cmd, " ")
-- for k,v in ipairs(tbl) do
-- print("--- ele:", k, v)
-- end
-- end
local eleArr = string.split(url, "%?")
dump(eleArr, "-- aaa")
end
local function test_match001()
local url = "https://test.cashfree.com/billpay/sim/thankyou"
print("--- res:", string.match(url, "thankyou"))
end
--------- 标准测试
-- test_find()
-- test_match()
-- test_gmatch()
-- test_gsub()
--------- 其他测试
-- test_findStr001()
test_match001()
c++
#include