本文始发于个人公众号:TechFlow,原创不易,求个关注
今天是Python专题的第23篇文章,我们来聊聊关于多线程的一个经典设计模式。
在之前的文章当中我们曾经说道,在多线程并发的场景当中,如果我们需要感知线程之间的状态,交换线程之间的信息是一件非常复杂和困难的事情。因为我们没有更高级的系统权限,也没有上帝视角,很难知道目前运行的状态的全貌,所以想要设计出一个稳健运行没有bug的功能,不仅非常困难,而且调试起来非常麻烦。
生产消费者模式
在日常开发当中,从一个线程向另外的线程传输数据又是一件家常便饭的事情。举个最简单的例子,我们在处理网页请求的时候,需要打印下来这一次请求的相关日志。打印日志是一次IO行为,这是非常消耗时间的,所以我们不能放在请求当中同步进行,否则会影响系统的性能。最好的办法就是启动一系列线程专门负责打印,后端的线程只负责响应请求,相关的日志以消息的形式传送给打印线程打印。
这个简单的不能再简单的功能当中涉及了诸多细节,我们来盘点几个。首先IO线程的数据都是从后台线程来的,假如一段时间内没有请求,那么这些线程都应该休眠,应该在有请求的时候才会启动。其次,如果某一段时间内请求非常多,导致IO线程一时间来不及打印所有的数据,那么当下的请求应该先暂存起来,等IO线程”忙过来“之后再进行处理。
把这些细节都考虑到,自己来设计功能还是挺麻烦的。好在这个问题前人已经替我们想过了,并且得出了一个非常经典的设计模式,使用它可以很好的解决这个问题。这个模式就是生产消费者模式。
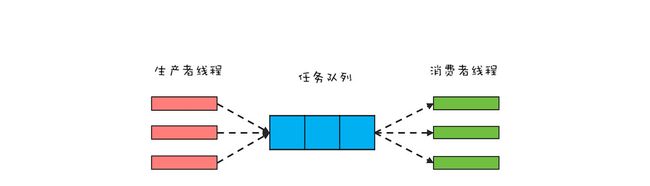
这个设计模式的原理其实非常简单,我们来看张图就明白了。
 Java并发-- 生产者-消费者模式| 点滴积累
Java并发-- 生产者-消费者模式| 点滴积累
线程根据和数据的关系分为生产者线程和消费者线程,其中生产者线程负责生产数据,产生了数据之后会存储到任务队列当中。消费者线程从这个队列获取需要消费的数据,它和生产者线程之间不会直接交互,避免了线程之间互相依赖的问题。
另外一个细节是这里的任务队列并不是普通的队列,一般情况下是一个阻塞队列。也就是说当消费者线程尝试从其中获取数据的时候,如果队列是空的,那么这些消费者线程会自动挂起等待,直到它获得了数据为止。有阻塞队列当然也有非阻塞队列,如果是非阻塞队列的话,当我们尝试从其中获取数据的时候,如果它当中没有数据的话,并不会挂起等待,而是会返回一个空值。
当然阻塞队列的挂起等待时间也是可以设置的,我们可以让它一直等待下去,也可以设置一个最长等待时间。如果超过这个时间也会返回空,不同的队列应用在不同的场景当中,我们需要根据场景性质做出调整。
代码实现
看完了设计模式的原理,我们下面来试着用代码来实现一下。
在一般的高级语言当中都有现成的队列的库,由于在生产消费者模式当中用到的是阻塞型queue,有阻塞性的队列当然也就有非阻塞型的队列。我们在用之前需要先了解清楚,如果用错了队列会导致整个程序出现问题。在Python当中,我们最常用的queue就是一个支持多线程场景的阻塞队列,所以我们直接拿来用就好了。
由于这个设计模式非常简单,这个代码并不长只有几行:
from queue import Queue
from threading import Thread
def producer(que):
data = 0
while True:
data += 1
que.put(data)
def consumer(que):
while True:
data = que.get()
print(data)
que = Queue()
t1 = Thread(target=consumer, args=(que, ))
t2 = Thread(target=producer, args=(que, ))
t1.start()
t2.start()
我们运行一下就会发现它是可行的,并且由于队列先进先出的限制,可以保证了consumer线程读取到的内容的顺序和producer生产的顺序是一致的。
如果我们运行一下这个代码会发现它是不会结束的,因为consumer和producer当中都用到了while True构建的死循环,假设我们希望可以控制程序的结束,应该怎么办?
其实也很简单,我们也可以利用队列。我们创建一个特殊的信号量,约定好当consumer接受到这个特殊值的时候就停止程序。这样当我们要结束程序的时候,我们只需要把这个信号量加入队列即可。
singal = object()
def producer(que):
data = 0
while data < 20:
data += 1
que.put(data)
que.put(singal)
def consumer(que):
while True:
data = que.get()
if data is singal:
# 继续插入singal
que.put(singal)
break
print(data)
这里有一个细节是我们在consumer当中,当读取到singal的时候,在跳出循环之前我们又把singal放回了队列。原因也很简单,因为有时候consumer线程不止一个,这个singal上游只放置了一个,只会被一个线程读取进来,其他线程并不会知道已经获得了singal的消息,所以还是会继续执行。
而当consumer关闭之前放入singal就可以保证每一个consumer在关闭的之前都会再传递一个结束的信号给其他未关闭的consumer读取。这样一个一个的传递,就可以保证所有consumer都关闭。
这里还有一个小细节,虽然利用队列可以解决生产者和消费者通信的问题,但是上游的生产者并不知道下游的消费者是否已经执行完成了。假如我们想要知道,应该怎么办?
Python的设计者们也考虑到了这个问题,所以他们在Queue这个类当中加入了task_done和join方法。利用task_done,消费者可以通知queue这一个任务已经执行完成了。而通过调用join,可以等待所有的consumer完成。
from queue import Queue
from threading import Thread
def producer(que):
data = 0
while data < 20:
data += 1
que.put(data)
def consumer(que):
while True:
data = que.get()
print(data)
que.task_done()
que = Queue()
t1 = Thread(target=consumer, args=(que, ))
t2 = Thread(target=producer, args=(que, ))
t1.start()
t2.start()
que.join()
除了使用task_done之外,我们还可以在que传递的消息当中加入一个Event,这样我们还可以继续感知到每一个Event执行的情况。
优先队列与其他设置
我们之前在介绍一些分布式调度系统的时候曾经说到过,在调度系统当中,调度者会用一个优先队列来管理所有的任务。当有机器空闲的时候,会有限调度那些优先级高的任务。
其实这个调度系统也是基于我们刚才介绍的生产消费者模型开发的,只不过将调度队列从普通队列换成了优先队列而已。所以如果我们也希望我们的consumer能够根据任务的优先级来改变执行顺序的话,也可以使用优先队列来进行管理任务。
关于优先队列的实现我们已经很熟悉了,但是有一个问题是我们需要实现挂起等待的阻塞功能。这个我们自己实现是比较麻烦的,但好在我们可以通过调用相关的库来实现。比如threading中的Condition,Condition是一个条件变量可以通知其他线程,也可以实现挂起等待。
from threading import Thread, Condition
class PriorityQueue:
def __init__(self):
self._queue = []
self._cv = Condition()
def put(self, item, priority):
with self._cv:
heapq.heappush(self._queue, (-priority, self._count, item))
# 通知下游,唤醒wait状态的线程
self._cv.notify()
def get(self):
with self._cv:
# 如果对列为空则挂起
while len(self._queue) == 0:
self._cv.wait()
# 否则返回优先级最大的
return heapq.heappop(self._queue)[-1]
最后介绍一下Queue的其他设置,比如我们可以通过size参数设置队列的大小,由于这是一个阻塞式队列,所以如果我们设置了队列的大小,那么当队列被装满的时候,往其中插入数据的操作也会被阻塞。此时producer线程会被挂起,一直到队列不再满为止。
当然我们也可以通过block参数将队列的操作设置成非阻塞。比如que.get(block=False),那么当队列为空的时候,将会抛出一个队列为空的异常。同样,que.put(data, block=False)时也一样会得到一个队列已满的异常。
总结
今天这篇文章当中我们主要介绍了多线程场景中经典的生产消费者模式,这个模式在许多场景当中都有使用。比如kafka等消息系统,以及yarn等调度系统等等,几乎只要是涉及到多线程上下游通信的,往往都会用到。也正因此它的使用场景太广了,所以它经常在各种面试当中出现,也可以认为是工程师必须知道的几种基础设计模式之一。
另外,队列也是一个在设计模式以及使用场景当中经常出现的数据结构。从侧面也说明了,为什么算法和数据结构非常重要,许多大公司喜欢问一些算法题,也是因为有实际的使用场景,并且的的确确能锻炼工程师的思维能力。经常有同学问我算法和数据结构的使用案例,这就是一个很好的例子。
今天的文章到这里就结束了,如果喜欢本文的话,请来一波素质三连,给我一点支持吧(关注、转发、点赞)。
