Python数据分析与机器学习实战笔记(10) - 项目实战(交易数据异常检测)
文章目录
- 项目实战(交易数据异常检测)
- 1. 信用卡欺诈检测
- 1.1 任务流程:
- 1.2 主要解决问题:
- 2. 项目总结
项目实战(交易数据异常检测)
1. 信用卡欺诈检测
基于信用卡交易记录数据建立分类模型来预测哪些交易记录是异常的哪些是正常的。
1.1 任务流程:
- a. 加载数据,观察问题
- b. 针对问题给出解决方案
- c. 数据集切分
- d. 评估方法对比
- e. 逻辑回归模型
- f. 建模结果分析
- g. 方案效果对比
1.2 主要解决问题:
(1)在此项目中,我们首选对数据进行了观察,发现了其中样本不均衡的问题,其实我们做任务工作之前都一定要先进行数据检查,看看数据有什么问题,针对这些问题来选择解决方案。
(2)这里我们提出了两种方法,下采样和过采样,两条路线来进行对比实验,任何实际问题来了之后,我们都不会一条路走到黑的,没有对比就没有伤害,通常都会得到一个基础模型,然后对各种方法进行对比,找到最合适的,所以在任务开始之前,一定得多动脑筋多一手准备,得到的结果才有可选择的余地。
(3)在建模之前,需要对数据进行各种预处理的操作,比如数据标准化,缺失值填充等,这些都是必要操作,由于数据本身已经给定了特征,此处我们还没有提到特征工程这个概念,后续实战中我们会逐步引入,其实数据预处理的工作是整个任务中最为最重也是最苦的一个阶段,数据处理的好不好对结果的影响是最大的。
(4)先选好评估方法,再进行建模。建模的目的就是为了得到结果,但是我们不可能一次就得到最好的结果,肯定要尝试很多次,所以一定得有一个合适的评估方法,可以用这些通用的,比如Recall,准确率等,也可以根据实际问题自己指定评估指标。
(5)选择合适的算法,这里我们使用的是逻辑回归,也详细分析了其中的细节,这是因为我们刚刚讲解完逻辑回归的原理就拿它来练手了,之后我们还会讲解其他算法,并不一定非要用逻辑回归来完成这个任务,其他算法可能效果会更好。但是有一点我希望大家能够理解就是在机器学习中并不是越复杂的算法越实用,恰恰相反,越简单的算法反而应用的越广泛。逻辑回归就是其中一个典型的代表了,简单实用,所以任何分类问题都可以把逻辑回归当做一个待比较的基础模型了。
(6)模型的调参也是很重要的,之前我们通过实验也发现了不同的参数可能会对结果产生较大的影响,这一步也是必须的,后续实战内容我们还会来强调调参的细节,这里就简单概述一下了。对于参数我建立大家在使用工具包的时候先看看其API文档,知道每一个参数的意义,再来实验选择合适的参数值。
(7)得到的结果一定要和实际任务结合在一起,有时候虽然得到的结果指标还不错,但是实际应用却成了问题,所以测试环节也是必不可少的。到此,这个项目就给大家介绍到这里了,在实践中学习才能成长的更快,建议大家一定使用提供的Notebook代码文件来自己完成一遍上述操作。
导入工具包
#导入工具包
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
数据读取
#数据读取
data = pd.read_csv("creditcard.csv")
data.head()
数据标签分布
#数据标签分布
count_classes = pd.value_counts(data['Class'], sort = True).sort_index()
count_classes.plot(kind = 'bar')
plt.title("Fraud class histogram")
plt.xlabel("Class")
plt.ylabel("Frequency")
Text(0,0.5,‘Frequency’)

数据标准化处理
from sklearn.preprocessing import StandardScaler
data['normAmount'] = StandardScaler().fit_transform(data['Amount'].values.reshape(-1, 1))
data = data.drop(['Time','Amount'],axis=1)
data.head()
下采样方案 under sample
X = data.iloc[:, data.columns != 'Class']
y = data.iloc[:, data.columns == 'Class']
# 得到所有异常样本的索引
number_records_fraud = len(data[data.Class == 1])
fraud_indices = np.array(data[data.Class == 1].index)
# 得到所有正常样本的索引
normal_indices = data[data.Class == 0].index
# 在正常样本中随机采样出指定个数的样本,并取其索引
random_normal_indices = np.random.choice(normal_indices, number_records_fraud, replace = False)
random_normal_indices = np.array(random_normal_indices)
# 有了正常和异常样本后把它们的索引都拿到手
under_sample_indices = np.concatenate([fraud_indices,random_normal_indices])
# 根据索引得到下采样所有样本点
under_sample_data = data.iloc[under_sample_indices,:]
X_undersample = under_sample_data.iloc[:, under_sample_data.columns != 'Class']
y_undersample = under_sample_data.iloc[:, under_sample_data.columns == 'Class']
# 下采样 样本比例
print("正常样本所占整体比例: ", len(under_sample_data[under_sample_data.Class == 0])/len(under_sample_data))
print("异常样本所占整体比例: ", len(under_sample_data[under_sample_data.Class == 1])/len(under_sample_data))
print("下采样策略总体样本数量: ", len(under_sample_data))
正常样本所占整体比例: 0.5
异常样本所占整体比例: 0.5
下采样策略总体样本数量: 984
数据集划分
from sklearn.cross_validation import train_test_split
# 整个数据集进行划分
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size = 0.3, random_state = 0)
print("原始训练集包含样本数量: ", len(X_train))
print("原始测试集包含样本数量: ", len(X_test))
print("原始样本总数: ", len(X_train)+len(X_test))
# 下采样数据集进行划分
X_train_undersample, X_test_undersample, y_train_undersample, y_test_undersample = train_test_split(X_undersample
,y_undersample
,test_size = 0.3
,random_state = 0)
print("")
print("下采样训练集包含样本数量: ", len(X_train_undersample))
print("下采样测试集包含样本数量: ", len(X_test_undersample))
print("下采样样本总数: ", len(X_train_undersample)+len(X_test_undersample))
原始训练集包含样本数量: 199364
原始测试集包含样本数量: 85443
原始样本总数: 284807
下采样训练集包含样本数量: 688
下采样测试集包含样本数量: 296
下采样样本总数: 984
逻辑回归模型
#Recall = TP/(TP+FN)#TP: true positive FN: false negative
from sklearn.linear_model import LogisticRegression
from sklearn.cross_validation import KFold, cross_val_score
from sklearn.metrics import confusion_matrix,recall_score,classification_report
from sklearn.model_selection import cross_val_predict
def printing_Kfold_scores(x_train_data,y_train_data):
fold = KFold(len(y_train_data),5,shuffle=False)
# 定义不同力度的正则化惩罚力度
c_param_range = [0.01,0.1,1,10,100]
# 展示结果用的表格
results_table = pd.DataFrame(index = range(len(c_param_range),2), columns = ['C_parameter','Mean recall score'])
results_table['C_parameter'] = c_param_range
# k-fold 表示K折的交叉验证,这里会得到两个索引集合: 训练集 = indices[0], 验证集 = indices[1]
j = 0
#循环遍历不同的参数
for c_param in c_param_range:
print('-------------------------------------------')
print('正则化惩罚力度: ', c_param)
print('-------------------------------------------')
print('')
recall_accs = []
#一步步分解来执行交叉验证
for iteration, indices in enumerate(fold,start=1):
# 指定算法模型,并且给定参数
lr = LogisticRegression(C = c_param, penalty = 'l1')
# 训练模型,注意索引不要给错了,训练的时候一定传入的是训练集,所以X和Y的索引都是0
lr.fit(x_train_data.iloc[indices[0],:],y_train_data.iloc[indices[0],:].values.ravel())
# 建立好模型后,预测模型结果,这里用的就是验证集,索引为1
y_pred_undersample = lr.predict(x_train_data.iloc[indices[1],:].values)
# 有了预测结果之后就可以来进行评估了,这里recall_score需要传入预测值和真实值。
recall_acc = recall_score(y_train_data.iloc[indices[1],:].values,y_pred_undersample)
# 一会还要算平均,所以把每一步的结果都先保存起来。
recall_accs.append(recall_acc)
print('Iteration ', iteration,': 召回率 = ', recall_acc)
# 当执行完所有的交叉验证后,计算平均结果
results_table.loc[j,'Mean recall score'] = np.mean(recall_accs)
j += 1
print('')
print('平均召回率 ', np.mean(recall_accs))
print('')
#找到最好的参数,哪一个Recall高,自然就是最好的了。
best_c = results_table.loc[results_table['Mean recall score'].astype('float32').idxmax()]['C_parameter']
# 打印最好的结果
print('*********************************************************************************')
print('效果最好的模型所选参数 = ', best_c)
print('*********************************************************************************')
return best_c
交叉验证与不同参数结果
best_c = printing_Kfold_scores(X_train_undersample,y_train_undersample)
正则化惩罚力度: 0.01
Iteration 1 : 召回率 = 0.958904109589
Iteration 2 : 召回率 = 0.931506849315
Iteration 3 : 召回率 = 1.0
Iteration 4 : 召回率 = 0.972972972973
Iteration 5 : 召回率 = 0.984848484848
平均召回率 0.969646483345
正则化惩罚力度: 0.1
Iteration 1 : 召回率 = 0.849315068493
Iteration 2 : 召回率 = 0.86301369863
Iteration 3 : 召回率 = 0.949152542373
Iteration 4 : 召回率 = 0.945945945946
Iteration 5 : 召回率 = 0.893939393939
平均召回率 0.900273329876
正则化惩罚力度: 1
Iteration 1 : 召回率 = 0.849315068493
Iteration 2 : 召回率 = 0.904109589041
Iteration 3 : 召回率 = 0.966101694915
Iteration 4 : 召回率 = 0.945945945946
Iteration 5 : 召回率 = 0.909090909091
平均召回率 0.914912641497
正则化惩罚力度: 10
Iteration 1 : 召回率 = 0.849315068493
Iteration 2 : 召回率 = 0.904109589041
Iteration 3 : 召回率 = 0.966101694915
Iteration 4 : 召回率 = 0.932432432432
Iteration 5 : 召回率 = 0.909090909091
平均召回率 0.912209938795
正则化惩罚力度: 100
Iteration 1 : 召回率 = 0.849315068493
Iteration 2 : 召回率 = 0.904109589041
Iteration 3 : 召回率 = 0.983050847458
Iteration 4 : 召回率 = 0.945945945946
Iteration 5 : 召回率 = 0.909090909091
平均召回率 0.918302472006
效果最好的模型所选参数 = 0.01
混淆矩阵
def plot_confusion_matrix(cm, classes,
title='Confusion matrix',
cmap=plt.cm.Blues):
"""
绘制混淆矩阵
"""
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=0)
plt.yticks(tick_marks, classes)
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, cm[i, j],
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
import itertools
lr = LogisticRegression(C = best_c, penalty = 'l1')
lr.fit(X_train_undersample,y_train_undersample.values.ravel())
y_pred_undersample = lr.predict(X_test_undersample.values)
# 计算所需值
cnf_matrix = confusion_matrix(y_test_undersample,y_pred_undersample)
np.set_printoptions(precision=2)
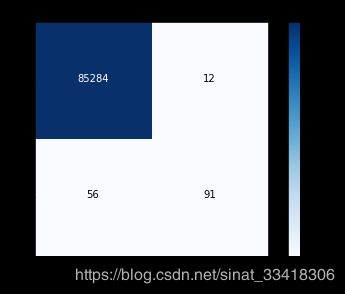
print("召回率: ", cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]))
# 绘制
class_names = [0,1]
plt.figure()
plot_confusion_matrix(cnf_matrix
, classes=class_names
, title='Confusion matrix')
plt.show()
召回率: 0.931972789116

下采样方案在原始数据集中的结果
lr = LogisticRegression(C = best_c, penalty = 'l1')
lr.fit(X_train_undersample,y_train_undersample.values.ravel())
y_pred = lr.predict(X_test.values)
# 计算所需值
cnf_matrix = confusion_matrix(y_test,y_pred)
np.set_printoptions(precision=2)
print("召回率: ", cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]))
# 绘制
class_names = [0,1]
plt.figure()
plot_confusion_matrix(cnf_matrix
, classes=class_names
, title='Confusion matrix')
plt.show()
召回率: 0.925170068027

best_c = printing_Kfold_scores(X_train,y_train)
C parameter: 0.01
Iteration 1 : recall score = 0.492537313433
Iteration 2 : recall score = 0.602739726027
Iteration 3 : recall score = 0.683333333333
Iteration 4 : recall score = 0.569230769231
Iteration 5 : recall score = 0.45
Mean recall score 0.559568228405
C parameter: 0.1
Iteration 1 : recall score = 0.567164179104
Iteration 2 : recall score = 0.616438356164
Iteration 3 : recall score = 0.683333333333
Iteration 4 : recall score = 0.584615384615
Iteration 5 : recall score = 0.525
Mean recall score 0.595310250644
C parameter: 1
Iteration 1 : recall score = 0.55223880597
Iteration 2 : recall score = 0.616438356164
Iteration 3 : recall score = 0.716666666667
Iteration 4 : recall score = 0.615384615385
Iteration 5 : recall score = 0.5625
Mean recall score 0.612645688837
C parameter: 10
Iteration 1 : recall score = 0.55223880597
Iteration 2 : recall score = 0.616438356164
Iteration 3 : recall score = 0.733333333333
Iteration 4 : recall score = 0.615384615385
Iteration 5 : recall score = 0.575
Mean recall score 0.61847902217
C parameter: 100
Iteration 1 : recall score = 0.55223880597
Iteration 2 : recall score = 0.616438356164
Iteration 3 : recall score = 0.733333333333
Iteration 4 : recall score = 0.615384615385
Iteration 5 : recall score = 0.575
Mean recall score 0.61847902217
Best model to choose from cross validation is with C parameter = 10.0
原始数据直接建模结果
lr = LogisticRegression(C = best_c, penalty = 'l1')
lr.fit(X_train,y_train.values.ravel())
y_pred_undersample = lr.predict(X_test.values)
# Compute confusion matrix
cnf_matrix = confusion_matrix(y_test,y_pred_undersample)
np.set_printoptions(precision=2)
print("Recall metric in the testing dataset: ", cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]))
# Plot non-normalized confusion matrix
class_names = [0,1]
plt.figure()
plot_confusion_matrix(cnf_matrix
, classes=class_names
, title='Confusion matrix')
plt.show()
Recall metric in the testing dataset: 0.619047619048
阈值对结果的影响
# 用之前最好的参数来进行建模
lr = LogisticRegression(C = 0.01, penalty = 'l1')
# 训练模型,还是用下采样的数据集
lr.fit(X_train_undersample,y_train_undersample.values.ravel())
# 得到预测结果的概率值
y_pred_undersample_proba = lr.predict_proba(X_test_undersample.values)
#指定不同的阈值
thresholds = [0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9]
plt.figure(figsize=(10,10))
j = 1
# 用混淆矩阵来进行展示
for i in thresholds:
y_test_predictions_high_recall = y_pred_undersample_proba[:,1] > i
plt.subplot(3,3,j)
j += 1
cnf_matrix = confusion_matrix(y_test_undersample,y_test_predictions_high_recall)
np.set_printoptions(precision=2)
print("给定阈值为:",i,"时测试集召回率: ", cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]))
class_names = [0,1]
plot_confusion_matrix(cnf_matrix
, classes=class_names
, title='Threshold >= %s'%i)
给定阈值为: 0.1 时测试集召回率: 1.0
给定阈值为: 0.2 时测试集召回率: 1.0
给定阈值为: 0.3 时测试集召回率: 1.0
给定阈值为: 0.4 时测试集召回率: 0.993197278912
给定阈值为: 0.5 时测试集召回率: 0.931972789116
给定阈值为: 0.6 时测试集召回率: 0.877551020408
给定阈值为: 0.7 时测试集召回率: 0.829931972789
给定阈值为: 0.8 时测试集召回率: 0.748299319728
给定阈值为: 0.9 时测试集召回率: 0.585034013605

SMOTE过采样方案 over sample
import pandas as pd
from imblearn.over_sampling import SMOTE
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import train_test_split
credit_cards=pd.read_csv('creditcard.csv')
columns=credit_cards.columns
# 在特征中去除掉标签
features_columns=columns.delete(len(columns)-1)
features=credit_cards[features_columns]
labels=credit_cards['Class']
features_train, features_test, labels_train, labels_test = train_test_split(features,
labels,
test_size=0.3,
random_state=0)
基于SMOTE算法来进行样本生成,这样正例和负例样本数量就是一致的了
oversampler=SMOTE(random_state=0)
os_features,os_labels=oversampler.fit_sample(features_train,labels_train)
训练集样本数量
len(os_labels[os_labels==1])
os_features = pd.DataFrame(os_features)
os_labels = pd.DataFrame(os_labels)
best_c = printing_Kfold_scores(os_features,os_labels)
正则化惩罚力度: 0.01
Iteration 1 : 召回率 = 0.914285714286
Iteration 2 : 召回率 = 0.88
Iteration 3 : 召回率 = 0.971699544765
Iteration 4 : 召回率 = 0.962088761039
Iteration 5 : 召回率 = 0.961724471466
平均召回率 0.937959698311
正则化惩罚力度: 0.1
Iteration 1 : 召回率 = 0.914285714286
Iteration 2 : 召回率 = 0.88
Iteration 3 : 召回率 = 0.972913505311
Iteration 4 : 召回率 = 0.961347620184
Iteration 5 : 召回率 = 0.963947894029
平均召回率 0.938498946762
正则化惩罚力度: 1
Iteration 1 : 召回率 = 0.914285714286
Iteration 2 : 召回率 = 0.88
Iteration 3 : 召回率 = 0.973065250379
Iteration 4 : 召回率 = 0.96436243044
Iteration 5 : 召回率 = 0.964400115568
平均召回率 0.939222702134
正则化惩罚力度: 10
Iteration 1 : 召回率 = 0.914285714286
Iteration 2 : 召回率 = 0.88
Iteration 3 : 召回率 = 0.973039959535
Iteration 4 : 召回率 = 0.964412677277
Iteration 5 : 召回率 = 0.963445425654
平均召回率 0.93903675535
正则化惩罚力度: 100
Iteration 1 : 召回率 = 0.914285714286
Iteration 2 : 召回率 = 0.88
Iteration 3 : 召回率 = 0.973065250379
Iteration 4 : 召回率 = 0.964425238987
Iteration 5 : 召回率 = 0.963922770611
平均召回率 0.939139794852
效果最好的模型所选参数 = 1.0
lr = LogisticRegression(C = best_c, penalty = 'l1')
lr.fit(os_features,os_labels.values.ravel())
y_pred = lr.predict(features_test.values)
# 计算混淆矩阵
cnf_matrix = confusion_matrix(labels_test,y_pred)
np.set_printoptions(precision=2)
print("召回率: ", cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]))
# 绘制
class_names = [0,1]
plt.figure()
plot_confusion_matrix(cnf_matrix
, classes=class_names
, title='Confusion matrix')
plt.show()
召回率: 0.884353741497

2. 项目总结
(1)在此项目中,我们首选对数据进行了观察,发现了其中样本不均衡的问题,其实我们做任务工作之前都一定要先进行数据检查,看看数据有什么问题,针对这些问题来选择解决方案。
(2)这里我们提出了两种方法,下采样和过采样,两条路线来进行对比实验,任何实际问题来了之后,我们都不会一条路走到黑的,没有对比就没有伤害,通常都会得到一个基础模型,然后对各种方法进行对比,找到最合适的,所以在任务开始之前,一定得多动脑筋多一手准备,得到的结果才有可选择的余地。
(3)在建模之前,需要对数据进行各种预处理的操作,比如数据标准化,缺失值填充等,这些都是必要操作,由于数据本身已经给定了特征,此处我们还没有提到特征工程这个概念,后续实战中我们会逐步引入,其实数据预处理的工作是整个任务中最为最重也是最苦的一个阶段,数据处理的好不好对结果的影响是最大的。
(4)先选好评估方法,再进行建模。建模的目的就是为了得到结果,但是我们不可能一次就得到最好的结果,肯定要尝试很多次,所以一定得有一个合适的评估方法,可以用这些通用的,比如Recall,准确率等,也可以根据实际问题自己指定评估指标。
(5)选择合适的算法,这里我们使用的是逻辑回归,也详细分析了其中的细节,这是因为我们刚刚讲解完逻辑回归的原理就拿它来练手了,之后我们还会讲解其他算法,并不一定非要用逻辑回归来完成这个任务,其他算法可能效果会更好。但是有一点我希望大家能够理解就是在机器学习中并不是越复杂的算法越实用,恰恰相反,越简单的算法反而应用的越广泛。逻辑回归就是其中一个典型的代表了,简单实用,所以任何分类问题都可以把逻辑回归当做一个待比较的基础模型了。
(6)模型的调参也是很重要的,之前我们通过实验也发现了不同的参数可能会对结果产生较大的影响,这一步也是必须的,后续实战内容我们还会来强调调参的细节,这里就简单概述一下了。对于参数我建立大家在使用工具包的时候先看看其API文档,知道每一个参数的意义,再来实验选择合适的参数值。
(7)得到的结果一定要和实际任务结合在一起,有时候虽然得到的结果指标还不错,但是实际应用却成了问题,所以测试环节也是必不可少的。到此,这个项目就给大家介绍到这里了,在实践中学习才能成长的更快,建议大家一定使用提供的Notebook代码文件来自己完成一遍上述操作。