TensorFlow学习笔记:编程模型
1 计算图
在TensorFlow中,算法都被表示成计算图(computational graphs)。计算图也叫数据流图,可以把计算图看做是一种有向图,图中的节点表示操作,图中的边代表在不同操作之间的数据流动。
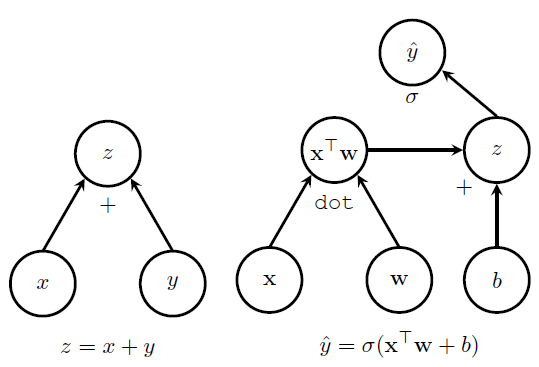
如图所示,左边的图表示 z=x+y 。从图中可以看到,x y z是图中的三个节点,x和y分别有一个箭头指到z,在z节点的下方有一个+号,表明是一个加法操作,因此最后的输出结果就是 z=x+y 。右图是一种相对复杂点的情况,随着计算图逐步分析可以得到 y^=σ(xTw+b) 。
在这样的数据流图中,有四个主要的元素:
* 操作(operations)
* 张量(tensors)
* 变量(variables)
* 会话(sessions)
操作
把算法表示成一个个操作的叠加,可以非常清晰地看到数据之间的关系,而且这样的基本操作也具有普遍性。在TensorFlow中,当数据流过操作节点的时候就可以对数据进行操作。一个操作可以有零个或多个输入,产生零个或多个输出。一个操作可能是一次数学计算,一个变量或常量,一个数据流走向控制,一次文件IO或者是一次网络通信。其中,一个常量可以看做是没有输入,只有一个固定输出的操作。具体操作如下所示:
| 操作类型 | 例子 |
|---|---|
| 元素运算 | Add,Mul |
| 矩阵运算 | MatMul,MatrixInverse |
| 数值产生 | Constant,Variable |
| 神经网络单元 | SoftMax,ReLU,Conv2D |
| I/O | Save,Restore |
每一种操作都需要相对应的底层计算支持,比如在GPU上使用就需要实现在GPU上的操作符,在CPU上使用就要实现在CPU上的操作符。
张量
在计算图中,每个边就代表数据从一个操作流到另一个操作。这些数据被表示为张量,一个张量可以看做是多维的数组或者高维的矩阵。
关于TensorFlow中的张量,需要注意的是张量本身并没有保存任何值,张量仅仅提供了访问数值的一个接口,可以看做是数值的一种引用。在TensorFlow实际使用中我们也可以发现,在run之前的张量并没有分配空间,此时的张量仅仅表示了一种数值的抽象,用来连接不同的节点,表示数据在不同操作之间的流动。
TensorFlow中还提供了SparseTensor数据结构,用来表示稀疏张量。
变量
变量是计算图中可以改变的节点。比如当计算权重的时候,随着迭代的进行,每次权重的值会发生相应的变化,这样的值就可以当做变量。在实际处理时,一般把需要训练的值指定为变量。在使用变量的时候,需要指定变量的初始值,变量的大小和数据类型就是根据初始值来推断的。
在构建计算图的时候,指定一个变量实际上需要增加三个节点:
* 实际的变量节点
* 一个产生初始值的操作,通常是一个常量节点
* 一个初始化操作,把初始值赋予到变量
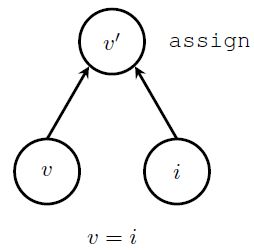
如图所示,v代表的是实际的变量,i是产生初始值的节点,上面的assign节点将初始值赋予变量,assign操作以后,产生已经初始化的变量值v'。
会话
在TensorFlow中,所有操作都必须在会话(session)中执行,会话负责分配和管理各种资源。在会话中提供了一个run方法,可以用它来执行计算图整体或者其中的一部分节点。在进行run的时候,还需要用feed_dict把相关数据输入到计算图。
当run被调用的时候,TensorFlow将会从指定的输出节点开始,向前查找所有的依赖界节点,所有依赖节点都将被执行。这些操作随后将被分配到物理执行单元上(比如CPU或GPU),这种分配规则由TensorFlow中的分配算法决定。
2 执行
在执行的时候,TensorFlow支持两种方式:一种是单机版本,可以在单机上支持多个计算设备,还有一种是分布式版本,支持多机多设备。在TensorFlow刚出来的时候,只支持第一种方式,后来开源了分布式版本。

当client发出run请求时,master会将这个请求分配到不同的worker上,这些worker负责监控具体的计算设备。
计算设备
所有的计算任务最终都将分配到实际的硬件上执行。除了CPU和GPU之外,TensorFlow也支持自定义硬件,比如谷歌自己使用的TPU(Tensor Processing Unit)。一个worker需要管理多个设备,所以这些设备的名称需要加上worker的名字,比如/cpu:0表示第一个CPU。
任务分配算法
如何将某个计算节点分配到具体设备上,TensorFlow提供了分配算法(placement algorithm)。
分配算法首先模拟计算图的执行,从输入节点到输出节点进行遍历,在遍历过程中遇到节点v,需要决定将这个节点分配到设备 D={d1,...,dn} 中的某一个设备上,具体分配将使用一个成本模型 Cv(d) 。这个成本模型需要考虑四个方面的信息来决定最优的执行设备 d^=argmind∈DCv(d) :
- 该设备是否实现了这个操作,比如某个操作不能在GPU上实现,那么所有的GPU成本都为无穷大。
- 估计节点的输入和输出数据大小
- 在设备上执行时间
- 如果输入的数据在另一个设备上,还需要考虑数据在不同设备间传输的成本
跨设备执行
如果用户系统有多个设备,任务分配算法就需要将节点分配到不同的设备上,在这个分配过程中,可能会出现一个设备中的输入依赖于另一个设备上的输出。此时就需要设备之间交叉执行。

如图所示,设备A上有节点 ν ,设备B上有节点 α 和 β ,其中 ν 的输出是 α 和 β 的输入。在计算图中, ν→α 和 ν→β 就需要跨设备执行。此时,TensorFlow将会自动在适当位置增加send和recv节点,在节点 ν 后面增加一个send节点,在 α 和 β 前面增加recv节点,send和recv节点之间使用额外的边进行链接。当数据流过这两个节点的时候就需要进行设备间通信,设备间通信方式包括TCP和RDMA等方式。此外,TensorFlow还会对recv节点进行进一步的优化,可以将设备B上的两个recv节点进行合并,减少通信次数,如图(c)所示。
3 优化
在编译的时候,TensorFlow还会进行一些优化以提高性能。
子图消除
在程序中,常常有一些重复的操作,可以把这些操作进行合并。可以将反复进行计算的同一个子图进行合并,保存其中的一个输出,在其他地方只需要直接调用就可以了。
调度优化
节点的执行越晚越好,这样的话,这个节点只在内存中保留较短的时间,可以有效降低内存的使用量。合理调度也能降低send和recv节点的网络冲突。
精度优化
许多机器学习算法不需要高的浮点精度,比如float32,只需要16位精度就够了,因此可以将32位精度降低为16位精度。当需要转换成32位精度时,只需要将尾部直接补0即可。
4 反向传播的计算图
在神经网络训练中,需要使用到反向传播算法。在TensorFlow等深度学习框架中,梯度计算都是自动进行的,不需要人工进行梯度计算,这样只需要使用者定义网络的结构,其他工作都由深度学习框架自动完成,大大简化了算法验证。在TensorFlow中,梯度计算也是采用了计算图的结构。
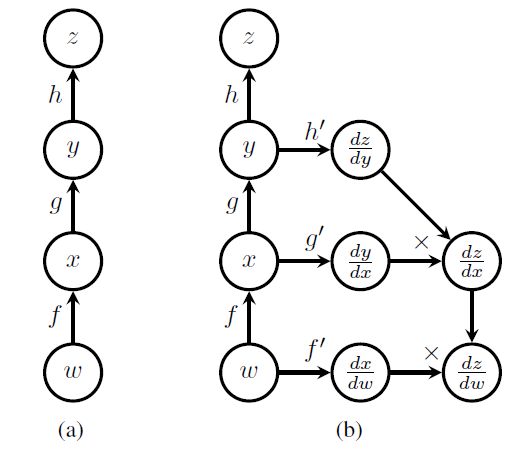
如图,在神经网络中常常需要对权重w进行求导。这样的函数前向计算的式子为: