(MTL)论文阅读CVPR2019:end-to-end multi-task learning with attention
end-to-end multi-task learning with attention
- abstract
- introduction
- related work
- MTAN
- MTAN 结构
- Task Specific Attention Module
- The Model Objective
- experiments
- Image to Image Prediction (One to Many)
- Datasets
- baselines
- Dynamic Weight Average
abstract
introduction
学习一下他的introduction结构,很清晰:
介绍CNN在CV任务上的出色表现。
however,现在很多网络都是针对某种特定任务的。
而现实世界的应用中我们更需要表现出多任务能力。
目前已经有MTL方法来解决多任务问题,我们提出的框架也是MTL的。
MTL有两个关键:
i) Network Architecture (how to share):
多任务学习体系结构应该同时表达任务共享和任务特定的特性。通过这种方式,网络被鼓励学习一个通用的表示(以避免过度拟合),同时也提供了学习为每个任务量身定制的特性的能力(以避免欠拟合)。
ii) Loss Function (how to balance tasks):多任务损失函数(multi-task loss function)对每个任务的相对贡献进行加权,它应该使所有任务的学习具有同等的重要性,而不是让更简单的任务占据主导地位。
手动调整损耗权值是繁琐的,最好是自动学习权值,或者设计一个对不同权值具有鲁棒性的网络。
Network Architecture (how to share):这个没什么好说的,本来cv上的各种新颖模型就是层出不穷。
Loss Function (how to balance tasks): 各个任务之间要设置权重,因为任务的难易程度不同。可以想象一下,如果任务难易不同却等同视之不用权重值加以权衡,那么,网络就会想,反正你不就要我输出结果越好就行,loss越低就行,那么一定会倾向于最简单的最容易降loss的那个任务。这就造成了不平衡,某些任务效果好某些任务效果不好。因此要用权重值平衡。
however,先前MTL方法只关注某个方面,我们的方法可以兼顾。task-shared and task-specific features to be learned automatically。
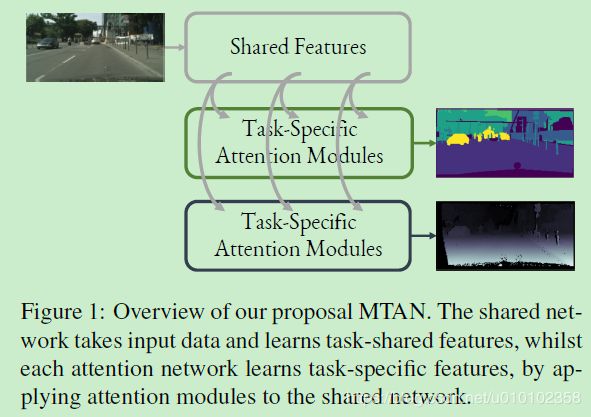
整体架构如上。
In this way, each attention mask
automatically determines the importance of the shared features
for the respective task, allowing learning of both task-shared
and task-specific features in a self-supervised, endto-
end manner.
attention模块自己根据特定任务学习the shared features 的重要性,从而对task-shared
and task-specific features的学习实现一种自监督self-supervised、端到端。
MTAN can be built on any feed-forward neural network
depending on the type of tasks.we also propose a
novel weighting scheme, DynamicWeight Average (DWA),
which adapts the task weighting over time by considering
the rate of change of the loss for each task.
我们还提出了一种新的加权方案——动态加权平均(DWA),它通过考虑每个任务损失的变化率来适应任务加权。
related work
早期的一个MTL模型,每个task分支都是一个network,之间用cross-stitch来交换信息。比较冗杂
Cross-stitch networks for multi-task learning. CVPR2016
自监督self-supervised的MTL模型:
Multi-task selfsupervised visual learning. ICCV2017
关于多任务学习中特征共享的平衡,在[20,14]中有大量的实验分析,两篇论文都认为不同的共享量和权重对不同的任务最有效。适当加权任务的一个例子是使用加权不确定性[14],它利用任务不确定性修改多任务学习中的损失函数。另一种方法是GradNorm[3],它通过控制梯度规范来控制训练动态。作为使用任务损失来确定任务难度的替代方法,动态任务优先级[10]鼓励直接使用准确性和精度等性能指标来确定困难任务的优先级。
MTAN
作者使用将MTAN建立在具有encoder-decoder结构的SegNet(2017年pami:A deep convolutional encoder-decoder architecture for image segmentation.)作为例子,展示图像到图像的密集像素级预测,如语义分割、深度估计和表面法线预测。
MTAN 结构
MTAN由两部分组成,一个共享网络,和若干个task-specific attention networks。
The shared
network can be designed based on the particular task, whilst
each task-specific network consists of a set of attention
modules, which link with the shared network. Each attention
module applies a soft attention mask to a particular
layer of the shared network, to learn task-specific features.
As such, the attention masks can be considered as feature
selectors from the shared network, which are automatically
learned in an end-to-end manner, whilst the shared network
learns a compact(紧凑的) global feature pool across all tasks.
这个共享网络通过所有子任务的共同学习最终学习到了一个紧凑的全局特征池。
每个注意模块学习一个软注意掩码,该掩码本身依赖于相应层共享网络中的特征。因此,共享网络中的特征和软注意掩模可以联合学习,从而在多个任务中最大化共享特征的泛化,同时通过注意掩模最大化特定任务的性能。 同时能够最大化共享特征的泛化性能(这里小存个疑,任务网络里也有可训练参数啊,一定能最大化共享网络的特征泛化么,没准是任务网络自己学习到的呢。不过再想想,任务网络里面的是那种注意力模块,接收共享网络的特征作为输入,再把学习到的mask乘回去,那么应该是可以辅助共享网络的训练的。)。
我觉得这里也是有一种加约束的思想。这种互相协同训练的网络,对于其中的每一个网络和除该网络的其他网络,其他网络就好像是给那个网络的加的约束一样,一种辅助,从而使它的性能更好。由此有一种思路,能否对于别的单一任务,如传统任务图像融合、篡改检测、增强,或cv任务如实例分割等等,外加一些能够辅助他们的网络来协同训练来提升性能呢?

主干网络不再做输出,只是作为了一个“特征池”
Task Specific Attention Module
文中作者所给的栗子的做法是:对于每一个块,第一次输入是pool后的第一层,第二次输入是pool前的最后一层。(这个可能不是固定的,再看看代码)
The attention module is designed to allow the taskspecific
network to learn task-related features, by applying
a soft attention mask to the features in the shared network,
with one attention mask per task per feature channel.


看上面这两个图,似乎是把pool前的最后一层conv的输出作为这个block最终提取出的共享特征了。
还要注意的是论文中的公式(2)描述的是encoder。
attention block里面还有pooling操作来匹配分辨率。

the attention mask 是使用反向传播自监督学习的。我们的网络在过程中就一直分享全局特征,我们期望效果至少不会比那些只在网络的最后才分裂出各单独任务的网络差。
The Model Objective
这里作者使用该网络做三个任务:
语义分割、深度估计、surface normals
https://cs.nyu.edu/~deigen/dnl/

https://blog.csdn.net/Kevin_cc98/article/details/78935659

由上面两个图可以看出,labels预测就是那种正常的语义分割,depth就是用热力图来表示预测像素所处的深度,surface normals 就是把处于平行的平面的像素归为一类,主要是三个方向的,像上面沙发平面和地面是平行的,就都归为紫色。墙面和沙发侧面是一个方向的面,就都是红色。
还有资料说surface normals是法线预测,法线同方向则归为一类。
三个任务都使用各自典型的损失函数,再加权和作为总loss。
experiments
测试两种类型任务:one-to-many predictions for image-to-image regression tasks 和 many-to-many predictions for image classification tasks (Visual Decathlon Challenge)。
Image to Image Prediction (One to Many)

MTAN可以构建在几乎任意网络上。在实验部分,作者将MTAN构建在SegNet上来进行一系列image-to-image prediction tasks,所谓image to image ,就是“图片”到“图片”的形式,就像上面那三种任务就是:

segnet是15年的模型,一种image-to-image的预测框架。图中的pooling indices(index的复数),就是指明了之前pooling时的最大值所处的位置,然后unpooling的时候把值填在相应位置。
Datasets
cityscapes 城市街景
NYUv2 室内
baselines
关于对比试验的设计,依然从Network Architecture (how to share) 和 Loss Function (how to balance tasks) 入手。
各种方法模型,体现的就是Network Architecture (how to share)。每个方法内还测试了三种权重平衡方法,equal weights, uncert.weights, DWA, 这体现就是Loss Function (how to balance tasks)。
baseline看github上也做了解释。
Dynamic Weight Average

t是epoch数,T是超参数,T越大,各任务间权重差别越小。Lk,是第k个任务的loss。
wk,就是该任务上轮loss除以上上轮loss,然后所有任务的w和某个任务的wk做softmax,以此来获得第k个任务的第t轮的权重λi。loss降得快,说明这个任务简单,loss(t-1)除以loss(t-2)自然就小,wk就小,λi就相应小。
使用softmax做权值分配也很常见,SKNet中也使用了。但通道注意力和空间注意力如果用softmax就会得到非常稀疏的结果,因为softmax不仅仅要求和为1,它还把值放在e的指数位上,这就使得值与值之间的差距更加拉大,越大的值结果越大。这种稀疏结果不能被用于空间通道注意力,因此用sigmoid。但在这种互相要拼出个你死我活的权重分配场景中softmax是适用的。