Transformer Assemble(PART III)
本文首发于微信公众号:NewBeeNLP,欢迎关注获取更多干货资源。
这一期魔改Transformers主要关注对原始模型中位置信息的讨论与优化,
- Self-Attention with RPR from Google,NAACL2018
- Self-Attention with SPR from Tencent,EMNLP 2019
- TENER from FDU
- Encoding Word Order in Complex Embedding,ICLR2020
1、Self-Attention with Relative Position Representations
一篇短文不是很难理解,文章要解决的痛点也非常清晰:self-attention机制在处理序列输入时无法编码位置信息。在原始Transformer里是采取sin/cos函数显示地引入位置信息,考虑的是绝对位置:
P E ( pos , 2 i ) = sin ( pos 10000 0 2 i / d nodd ) P E ( pos , 2 i + 1 ) = cos ( pos 1000 0 2 i / d nodd ) \begin{aligned} &P E(\text {pos}, 2 i)=\sin \left(\frac{\text {pos}}{100000^{2 i / d_{\text {nodd}}}}\right)\\ &P E(\text { pos }, 2 i+1)=\cos \left(\frac{\text { pos }}{10000^{2 i / d_{\text {nodd}}}}\right) \end{aligned} PE(pos,2i)=sin(1000002i/dnoddpos)PE( pos ,2i+1)=cos(100002i/dnodd pos )其中, p o s pos pos表示token在序列中的位置, i i i表示position embedding的第 i i i维,总共有 d m o d e l d_{model} dmodel维。另外,作者在原文中指出,sin/cos函数的周期性形式可以允许模型进一步学习到相对位置的信息。但是这种方式学习到的相对位置信息仍然是存在较大缺陷的,参考文章【浅谈 Transformer-based 模型中的位置表示】。
正对以上问题,这篇论文提出一种相对位置信息引入Transformer的方法。
Vanilla Transformer
为了方便两者的对比,给出原始Transformer里self-attention的计算:
z i = ∑ j = 1 n α i j ( x j W V ) z_{i}=\sum_{j=1}^{n} \alpha_{i j}\left(x_{j} W^{V}\right) zi=j=1∑nαij(xjWV) α i j = exp e i j ∑ k = 1 n exp e i k \alpha_{i j}=\frac{\exp e_{i j}}{\sum_{k=1}^{n} \exp e_{i k}} αij=∑k=1nexpeikexpeij e i j = ( x i W Q ) ( x j W K ) T d z e_{i j}=\frac{\left(x_{i} W^{Q}\right)\left(x_{j} W^{K}\right)^{T}}{\sqrt{d_{z}}} eij=dz(xiWQ)(xjWK)T
e i j e_{ij} eij: the scaled dot product of token i i i and token j j j;
α i j \alpha_{ij} αij: the weight coefficient of token i i i and token j j j;
z i z{i} zi: the output representation of token i i i
Relative Position Representations
输入被看成是有向全连接图,两个token x i x_{i} xi、 x j x_{j} xj之间的边设置了权重 a i j V , a i j K ∈ R d a a_{i j}^{V}, a_{i j}^{K} \in \mathbb{R}^{d_{a}} aijV,aijK∈Rda,用做attention时key-value对添加相对位置信息。
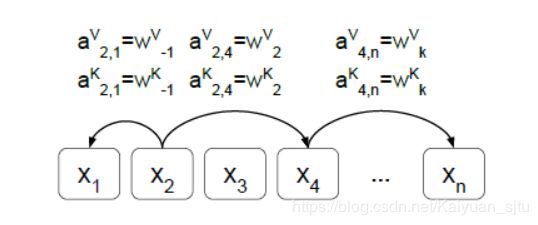
作者认为,在token之间超过一定距离之后相对位置信息就没有意义,因此设置了一个最大截断 k k k,且截断可以更好地提升模型泛化能力。计算公式如下:
a i j K = w clip ( j − i , k ) K a i j V = w clip ( j − i , k ) V clip ( x , k ) = max ( − k , min ( k , x ) ) \begin{aligned} a_{i j}^{K} &=w_{\operatorname{clip}(j-i, k)}^{K} \\ a_{i j}^{V} &=w_{\operatorname{clip}(j-i, k)}^{V} \\ \operatorname{clip}(x, k) &=\max (-k, \min (k, x)) \end{aligned} aijKaijVclip(x,k)=wclip(j−i,k)K=wclip(j−i,k)V=max(−k,min(k,x))其中,上面的 a i j K a_{i j}^{K} aijK和 a i j V a_{i j}^{V} aijV都是需要学习的,即需要学习的为 w K = ( w − k K , … , w k K ) and w V = ( w − k V , … , w k V ) w^{K}=\left(w_{-k}^{K}, \ldots, w_{k}^{K}\right) \text { and } w^{V}=\left(w_{-k}^{V}, \ldots, w_{k}^{V}\right) wK=(w−kK,…,wkK) and wV=(w−kV,…,wkV)公式可能不好理解,举个栗子,假设序列长度N=9,截断窗口k=3,则RPR嵌入的lookup表如下图,感觉跟滑动窗口有点像:
w K = ( w − 4 K , … , w 4 K ) w^{K}=\left(w_{-4}^{K}, \ldots, w_{4}^{K}\right) wK=(w−4K,…,w4K) w V = ( w − 4 V , … , w 4 V ) w^{V}=\left(w_{-4}^{V}, \ldots, w_{4}^{V}\right) wV=(w−4V,…,w4V)
Relation-aware Self-Attention
理解上面RPR之后,就可以对原始self-attention进行改写,将相对位置信息融入进去:
z i = ∑ j = 1 n α i j ( x j W V + a i j V ) z_{i}=\sum_{j=1}^{n} \alpha_{i j}\left(x_{j} W^{V}+a_{i j}^{V}\right) zi=j=1∑nαij(xjWV+aijV) e i j = x i W Q ( x j W K + a i j K ) T d z e_{i j}=\frac{x_{i} W^{Q}\left(x_{j} W^{K}+a_{i j}^{K}\right)^{T}}{\sqrt{d_{z}}} eij=dzxiWQ(xjWK+aijK)T
虽然论文基本概念相对简单(自注意力机制中包含了相对位置信息),但是它极大地提高了两个机器翻译任务的翻译质量。
Reference
- Code Here
- How Self-Attention with Relative Position Representations works
Self-Attention with Structural Position Representations
不管是transformer原文的绝对位置编码还是上文引入的相对位置编码,都属于sequential information。作者从Hewitt和Manning发表的论文中得到启发:句子的潜在结构可以通过结构深度和距离来捕获,于是他们提出了absolute structural position来编码元素在句法树种深度,relative structural position来编码元素之间的距离。
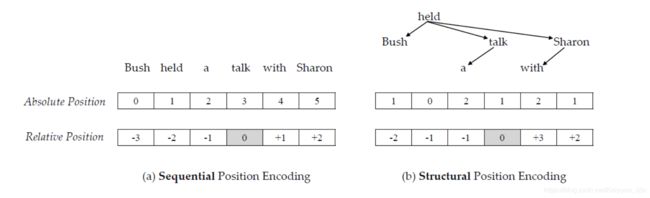
上图左边属于两种序列位置编码表示,具体在上一节已经有介绍;右边是本文提出的结构位置编码,分为两种:
- Absolute Structural Position:把句子的主要动词(如上图"held")作为origin,然后通过计算句法树中目标词语origin之间的距离作为绝对结构位置信息:
abs str u ( x i ) = distance tree ( x i , origin ) \operatorname{abs}_{\operatorname{str} u}\left(x_{i}\right)=\operatorname{distance}_{\operatorname{tree}}\left(x_{i}, \text {origin}\right) absstru(xi)=distancetree(xi,origin) - Relative Structural Position:相对位置信息考虑的单词对之间的关系,
- 如果单词 x i x_{i} xi和 x j x_{j} xj在句法树的同一条边上,则相对位置即为绝对位置之差:
r e l s t r u ( x i , x j ) = a b s s t r u ( x i ) − a b s s t r u ( x j ) r e l_{s t r u}\left(x_{i}, x_{j}\right)=a b s_{s t r u}\left(x_{i}\right)-a b s_{s t r u}\left(x_{j}\right) relstru(xi,xj)=absstru(xi)−absstru(xj) - 如果在不同的边上,相对位置为绝对位置之和乘上一个系数 f s t r u ( x ) f_{s t r u}(x) fstru(x)
r e l s t r u ( x i , x j ) = f s t r u ( i − j ) ∗ ( a b s s t r u ( x i ) + a b s s t r u ( x j ) ) r e l_{s t r u}\left(x_{i}, x_{j}\right)=f_{s t r u}(i-j) *\left(a b s_{s t r u}\left(x_{i}\right)+a b s_{s t r u}\left(x_{j}\right)\right) relstru(xi,xj)=fstru(i−j)∗(absstru(xi)+absstru(xj))当两个单词正序时系数为1;相同时系数为0;逆序时系数为-1:
f s t r u ( x ) = { 1 x > 0 0 x = 0 − 1 x < 0 f_{s t r u}(x)=\left\{\begin{array}{ll} {1} & {x>0} \\ {0} & {x=0} \\ {-1} & {x<0} \end{array}\right. fstru(x)=⎩⎨⎧10−1x>0x=0x<0
- 如果单词 x i x_{i} xi和 x j x_{j} xj在句法树的同一条边上,则相对位置即为绝对位置之差:
接下去就是将结构位置信息整合进SAN,
- 对于绝对位置,通过一个非线性函数将序列位置和结构位置融合得到位置表示:
asb ( x i ) = f a b s ( A B S P E ( a b s s e q ) , A B S P E ( a b s s t r u ) ) \operatorname{asb}\left(x_{i}\right)=f_{a b s}\left(\mathrm{ABSPE}\left(a b s_{s e q}\right)\right.,\left.\mathrm{ABSPE}\left(a b s_{s t r u}\right)\right) asb(xi)=fabs(ABSPE(absseq),ABSPE(absstru)) - 对于相对位置,采用同上一篇论文一致的方法
一点疑问…
简单看了一下《A Structural Probe for Finding Syntax in Word Representations》,也就是作者在文章里说给了他们motivation的论文,大概说的是通过structural probe检测像BERT这样的模型学到的context represetation是否包含了syntax tree信息,结论是可以学到句法树的结构信息。那这样为啥还要加structural position representation呢?
TENER: Adapting Transformer Encoder for Named Entity Recognition
针对命名实体识别任务的一个工作,虽然Transformer系在NLP很多领域都取得了非常大的进步,但是在NER任务上表现不佳。作者分析了注意力机制与特定的NER任务,发现原始实现中的位置信息编码、注意力稀疏性方面不太适用于NER。
位置信息编码
- 距离性
vanilla transformer中位置信息使用sin/cos函数嵌入,由公式定义
P E t , 2 i = sin ( t 1000 0 2 i / d ) P E t , 2 i + 1 = cos ( t 1000 0 2 / d ) \begin{aligned} P E_{t, 2 i}=& \sin \left(\frac{t}{10000^{2 i / d}}\right) \\ P E_{t, 2 i+1} &=\cos \left(\frac{t}{10000^{2 / d}}\right) \end{aligned} PEt,2i=PEt,2i+1sin(100002i/dt)=cos(100002/dt)可以推导出 P E t T P E t + k = ∑ j = 0 d 2 − 1 [ sin ( c j t ) sin ( c j ( t + k ) ) + cos ( c j t ) cos ( c j ( t + k ) ) ] = ∑ j = 0 d 2 − 1 cos ( c j ( t − ( t + k ) ) ) = ∑ j = 0 d 2 − 1 cos ( c j k ) \begin{aligned} P E_{t}^{T} P E_{t+k} &=\sum_{j=0}^{\frac{d}{2}-1}\left[\sin \left(c_{j} t\right) \sin \left(c_{j}(t+k)\right)+\cos \left(c_{j} t\right) \cos \left(c_{j}(t+k)\right)\right] \\ &=\sum_{j=0}^{\frac{d}{2}-1} \cos \left(c_{j}(t-(t+k))\right) \\ &=\sum_{j=0}^{\frac{d}{2}-1} \cos \left(c_{j} k\right) \end{aligned} PEtTPEt+k=j=0∑2d−1[sin(cjt)sin(cj(t+k))+cos(cjt)cos(cj(t+k))]=j=0∑2d−1cos(cj(t−(t+k)))=j=0∑2d−1cos(cjk)可见两个元素的点积只与它们之间的距离 k k k有关(距离敏感),但是进一步研究可以发现,当position embedding被映射到自注意力的键值对时,其就会失去距离敏感性,如下图,最上面的曲线表示 P E t T P E t + k P E_{t}^{T} P E_{t+k} PEtTPEt+k,可以反映对称性;下面两条曲线表示 P E t T W P E t + k P E_{t}^{T}W PE_{t+k} PEtTWPEt+k,无距离特性。
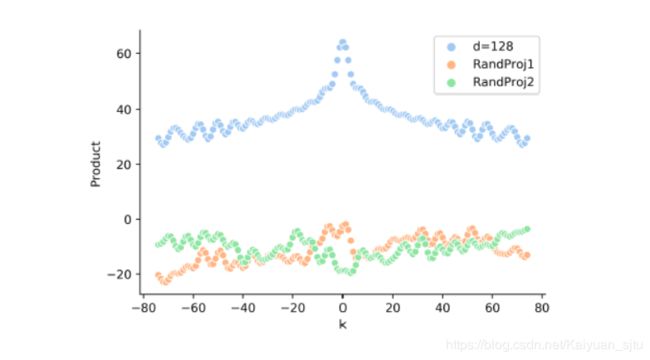
论文中说 P E t T W P E t + k P E_{t}^{T}W PE_{t+k} PEtTWPEt+k中的 W W W是随机的,但是这个参数是可学习的,在模型训练之后会不会效果变好?
- 方向性
此外,由上述推导可知,令 j = t − k j=t-k j=t−k,有
P E t T P E t + k = P E j T P E j + k = P E t − k T P E t P E_{t}^{T} P E_{t+k}=P E_{j}^{T} P E_{j+k}=P E_{t-k}^{T} P E_{t} PEtTPEt+k=PEjTPEj+k=PEt−kTPEt因此这也是方向不敏感的
由上分析可知该种嵌入方式并不能反映方向性和距离性,但是对于NER任务而言距离和方向都是尤为重要的。为此本文对注意力分数计算进行改进,将绝对位置改成相对位置: Q , K , V = H W q , H d k , H W v Q, K, V=H W_{q}, H_{d_{k}}, H W_{v} Q,K,V=HWq,Hdk,HWv R t − j = [ … , sin ( t − j 1000 0 2 i d k ) cos ( t − j 1000 0 2 i d k ) , … ] T {R_{t-j}=\left[\ldots, \sin \left(\frac{t-j}{10000^{2 i} d_{k}}\right) \cos \left(\frac{t-j}{10000^{2 i} d_{k}}\right), \ldots\right]^{T}} Rt−j=[…,sin(100002idkt−j)cos(100002idkt−j),…]T A t j r e l = Q t T K j + Q t T R t − j u T K j + v T R t − j {A_{t j}^{r e l}=Q_{t}^{T} K_{j}+Q_{t}^{T} R_{t-j} u^{T} K_{j}+v^{T} R_{t-j}} Atjrel=QtTKj+QtTRt−juTKj+vTRt−j A t t n ( Q , K , V ) = softmax ( A r e l ) V {A t tn(Q, K, V)=\operatorname{softmax}\left(A^{r e l}\right) V} Attn(Q,K,V)=softmax(Arel)V与transformer-xl里的比较像。
注意力稀疏
注意到修改后的Attention计算最后没有用到scaling系数 d \sqrt{d} d,这是因为对于NER任务只需要attend几个相对重要的context就足够了,scaled后的attention分布过于平滑会引入噪音。
这篇论文感觉主要重点在工程意义,在NER任务达到最好的效果;针对NER任务做了专门的修改,除了上面的相对位置信息和系数注意力,由于NER数据集相对较小,也减少了模型的可学习参数避免过拟合。
reference
- Code Here
- TENER: Adapting Transformer Encoder for NER
Encoding Word Order in Complex Embedding
比较有意思的工作,关注的点也是在序列建模的位置信息编码。先前的方法通过引入额外的位置编码,在embedding层将词向量和位置向量通过加性编码融合,
f ( j , p o s ) = f w e ( j ) + f p e ( p o s ) f(j, p o s)=f_{w e}(j)+f_{p e}(p o s) f(j,pos)=fwe(j)+fpe(pos)但是该种方式每个位置向量是独立训练得到的,并不能建模序列的order relationship(例如邻接或优先关系),作者将此称为the position independece problem。
针对该问题提出了一种新的位置编码方式,将独立的词向量替换成自变量为位置的函数,于是单词表示会随着位置的变化而平滑地移动,可以更好地建模单词的绝对位置和顺序信息。
f ( j , pos ) = g j ( pos ) ∈ C D f(j, \text { pos })=g_{j}(\text { pos }) \in \mathbb{C}^{D} f(j, pos )=gj( pos )∈CD其中, f ( j , pos ) f(j, \text { pos }) f(j, pos )表示此表中序号为 j j j的单词在位置 p o s pos pos时的单词向量, D D D表示函数集合, g w e ( ⋅ ) : N → ( F ) D g_{w e}(\cdot):\mathbb{N} \rightarrow(\mathcal{F})^{D} gwe(⋅):N→(F)D表示单词到函数的映射,展开即为, [ g j , 1 ( p o s ) , g j , 2 ( p o s ) , … , g j , D ( p o s ) ] ∈ C D \left[g_{j, 1}(\mathrm{pos}), g_{j, 2}(\mathrm{pos}), \ldots, g_{j, D}(\mathrm{pos})\right] \in \mathbb{C}^{D} [gj,1(pos),gj,2(pos),…,gj,D(pos)]∈CD
为了达到上述要求,函数应该满足以下两个条件:
Property 1. Position-free offset transformation
对于任意位置pos和 n > 1 n>1 n>1,存在变换Transform n ( ⋅ ) = _{n}(\cdot)= n(⋅)= Transform ( n , ⋅ ) (n, \cdot) (n,⋅)满足, g ( p o s + n ) = Transform n ( g ( p o s ) ) g(\mathrm{pos}+n)=\text { Transform }_{n}(g(\mathrm{pos})) g(pos+n)= Transform n(g(pos))特别地,论文考虑Transform为线性变换
Property 2. Boundedness
函数应该是有界的,
∃ δ ∈ R + , ∀ pos ∈ N , ∣ g ( pos ) ∣ ≤ δ \exists \delta \in\mathbb{R}^{+}, \forall \text { pos } \in \mathbb{N},|g(\operatorname{pos})| \leq \delta ∃δ∈R+,∀ pos ∈N,∣g(pos)∣≤δ
接下去,论文证明了满足上述两个条件的解函数形式为,
g ( p o s ) = z 2 z 1 p o s for z 1 , z 2 ∈ C with ∣ z 1 ∣ ≤ 1 g(p o s)=z_{2} z_{1}^{p o s} \text { for } z_{1}, z_{2} \in \mathbb{C} \text { with }\left|z_{1}\right| \leq 1 g(pos)=z2z1pos for z1,z2∈C with ∣z1∣≤1
贴一下论文给的证明:(看不看无所谓,能用就行haha)
假设函数 g g g满足上述两个条件,则对于任意位置 n 1 , n 2 ∈ N n_{1}, n_{2} \in \mathbb{N} n1,n2∈N,有
w ( n 1 ) w ( n 2 ) g ( pos ) = w ( n 2 ) g ( pos + n 1 ) = g ( pos + n 1 + n 2 ) = Transform n 1 + n 2 ( g ( pos ) ) = w ( n 1 + n 2 ) g ( pos ) \begin{aligned} w\left(n_{1}\right) w\left(n_{2}\right) g(\text { pos }) &=w\left(n_{2}\right) g\left(\text { pos }+n_{1}\right)=g\left(\text { pos }+n_{1}+n_{2}\right) \\ &=\text { Transform }_{n_{1}+n_{2}}(g(\text { pos }))=w\left(n_{1}+n_{2}\right) g(\text { pos }) \end{aligned} w(n1)w(n2)g( pos )=w(n2)g( pos +n1)=g( pos +n1+n2)= Transform n1+n2(g( pos ))=w(n1+n2)g( pos )因此有 w ( n 1 + n 2 ) = w ( n 1 ) w ( n 2 ) w\left(n_{1}+n_{2}\right)=w\left(n_{1}\right) w\left(n_{2}\right) w(n1+n2)=w(n1)w(n2)。我们令 w ( 1 ) = z 1 w(1)=z_{1} w(1)=z1以及 g ( 0 ) = z 2 g(0)=z_{2} g(0)=z2,由于 n 1 , n 2 ∈ N n_{1}, n_{2} \in \mathbb{N} n1,n2∈N是任意的,有
w ( n ) = ( w ( 1 ) ) n = z 1 n w(n)=(w(1))^{n}=z_{1}^{n} w(n)=(w(1))n=z1n g ( pos + n ) = w ( n ) g ( pos ) = z 1 n g ( pos ) g(\text { pos }+n)=w(n) g(\text { pos })=z_{1}^{n} g(\text { pos }) g( pos +n)=w(n)g( pos )=z1ng( pos )当pos ≥ 1 \geq 1 ≥1时,有
g ( pos ) = g ( 1 + pos − 1 ) = w ( pos ) g ( 0 ) = z 1 pos z 2 = z 2 z 1 pos g(\text { pos })=g(1+\text { pos }-1)=w(\text { pos }) g(0)=z_{1}^{\text {pos }} z_{2}=z_{2} z_{1}^{\text {pos }} g( pos )=g(1+ pos −1)=w( pos )g(0)=z1pos z2=z2z1pos
当pos = 1 =1 =1时,有 g ( 0 ) = z 2 = z 2 z 1 0 g(0)=z_{2}=z_{2} z_{1}^{0} g(0)=z2=z2z10综上,将上述所有情况综合有 g ( pos ) = z 2 z 1 pos g(\text { pos })=z_{2} z_{1}^{\text {pos }} g( pos )=z2z1pos 发现当 ∣ z 1 ∣ > 1 \left|z_{1}\right|>1 ∣z1∣>1, g ( pos ) g(\text { pos }) g( pos )就不是有界的了,因此限制 ∣ z 1 ∣ ≤ 1 \left|z_{1}\right| \leq 1 ∣z1∣≤1后,有
∣ g ( pos ) ∣ ≤ ∣ z 2 z 1 pos ∣ ≤ ∣ z 2 ∣ ∣ z 1 pos ∣ ≤ ∣ z 2 ∣ | g(\text { pos })|\leq| z_{2} z_{1}^{\text {pos }}|\leq| z_{2}|| z_{1}^{\text {pos }}|\leq| z_{2} | ∣g( pos )∣≤∣z2z1pos ∣≤∣z2∣∣z1pos ∣≤∣z2∣这样就满足有界性的条件了;
又由 w ( n ) = z 1 n w(n)=z_{1}^{n} w(n)=z1n和Transform n ( pos ) = w ( n ) _{n}(\text { pos })=w(n) n( pos )=w(n) pos得对所有的位置pos, g ( pos + n ) = z 2 z 1 p s + n = z 2 z 1 p o s z 1 n = g ( pos ) z 1 n = Transform n ( g ( pos ) ) g(\text { pos }+n)=z_{2} z_{1}^{\mathrm{ps}+n}=z_{2} z_{1}^{\mathrm{pos}} z_{1}^{n}=g(\text { pos }) z_{1}^{n}=\text{Transform}_{n}(g(\text { pos })) g( pos +n)=z2z1ps+n=z2z1posz1n=g( pos )z1n=Transformn(g( pos ))
得证
根据欧拉公式,可以将上式转化为,
g ( pos ) = z 2 z 1 pos = r 2 e i θ 2 ( r 1 e i θ 1 ) pos = r 2 r 1 pos e i ( θ 2 + θ 1 pos ) subject to ∣ r 1 ∣ ≤ 1 g(\text { pos })=z_{2} z_{1}^{\text {pos }}=r_{2} e^{i \theta_{2}}\left(r_{1} e^{i \theta_{1}}\right)^{\text {pos }}=r_{2} r_{1}^{\text {pos }} e^{i\left(\theta_{2}+\theta_{1} \text { pos }\right)} \text { subject to }\left|r_{1}\right| \leq 1 g( pos )=z2z1pos =r2eiθ2(r1eiθ1)pos =r2r1pos ei(θ2+θ1 pos ) subject to ∣r1∣≤1在实现过程中,由于上述 ∣ r 1 ∣ ≤ 1 \left|r_{1}\right| \leq 1 ∣r1∣≤1的限制会导致优化问题,因此一种自然而然的做法就是固定 r 1 = 1 r_{1}=1 r1=1,于是上式可以简化为, g ( pos ) = r e i ( ω pos + θ ) g(\text { pos })=r e^{i(\omega \text { pos }+\theta)} g( pos )=rei(ω pos +θ)
最终的embedding表示为,
f ( j , pos ) = g j ( pos ) = r j e i ( ω j pos + θ j ) f(j, \text { pos })=\boldsymbol{g}_{j}(\text { pos })=\boldsymbol{r}_{j} e^{i\left(\boldsymbol{\omega}_{j} \text { pos }+\boldsymbol{\theta}_{j}\right)} f(j, pos )=gj( pos )=rjei(ωj pos +θj)其中振幅 r j r_{j} rj、角频率 w j w_{j} wj和初相 θ j \theta_{j} θj是需要学习的参数。
- 振幅 r j r_{j} rj只和单词本身有关,即原本的词向量;
- 角频率 w j w_{j} wj决定单词对位置的敏感程度。当角频率非常小时(如下图p1),单词对于所有位置的词向量基本保持不变,这就与标准词向量一样了;
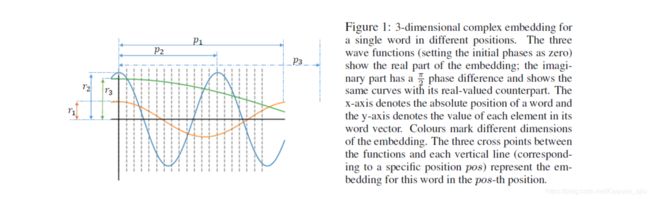
简单看一下文本分类任务的消融性分析结果:
-
增加可学习初相之后效果比设置初相为0差:
“The negative effect of initial phases may be due to periodicity, and w w w cannot be directly regularized with L2-norm penalties.”
-
设置参数共享之后效果变差,可能是由于参数变少导致学习表征能力下降;
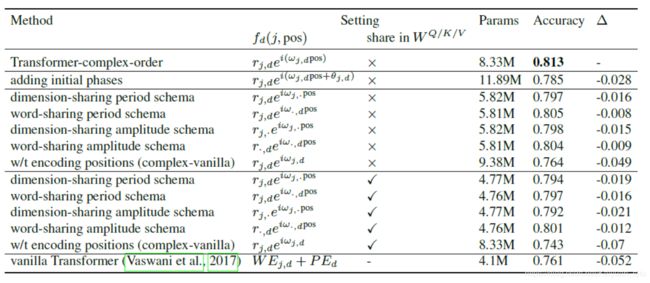
- 要用的话,计算量以及参数量是不是会很大呀
- 好像也没跟其他relative position的模型比较
reference
- Code Here
- Open Review