【数据挖掘】DBSCAN聚类算法(python实现)
一、python代码
'''
Author: Vici__
date: 2020/5/14
'''
import math
'''
Point类,记录坐标x,y和点的名字id
'''
class Point:
'''
初始化函数
'''
def __init__(self, x, y, name):
self.x = x # 横坐标
self.y = y # 纵坐标
self.name = name # 名字
'''
计算两点之间的欧几里得距离
'''
def calc_Euclidean_distance(self, p2):
return math.sqrt((self.x - p2.x) * (self.x - p2.x) + (self.y - p2.y) * (self.y - p2.y))
'''
1. 获取数据集
'''
def get_dataset():
# 原始数据集以元组形式存放,(横坐标,纵坐标,名字)
datas = [(1, 3, '1'), (1, 2, '2'), (2, 4, '3'), (2, 3, '4'),
(2, 2, '5'), (2, 1, '6'), (3, 2, '7'), (4, 2, '8'),
(5, 3, '9'), (5, 2, '10'), (5, 1, '11'), (6, 2, '12')]
dataset = [] # 用于计算两点之间的距离,形式 [point1, point2...]
id_point_dict = {} # 编号和点的映射
temp_list = []
for i in range(len(datas)): # 遍历原始数据集
point = Point(datas[i][0], datas[i][1], datas[i][2]) # 利用(横坐标,纵坐标,编号)实例化
id_point_dict[str(i)] = point
dataset.append(point) # 放入dataset中
temp_list.append(point)
return dataset, id_point_dict # [p1, p2], {id: point}
'''
2. 计算任意两点之间的距离
'''
def get_dist(dataset):
n = len(dataset) # 点的个数
dist = [] # 存放任意两点之间的距离
for i in range(n):
dist_i = [] # 临时列表
for j in range(n): # 遍历数据集
# 计算距离并放入临时列表中
dist_i.append(dataset[i].calc_Euclidean_distance(dataset[j]))
dist.append(dist_i) # 利用临时列表创建二维列表
# 打印dist
print("任意两点之间的距离:")
for d in dist:
print(d)
print()
return dist
def DBSCAN(dataset, r, min_point):
id_to_key = {} # 编号到key的映射
key_to_set = {} # key到集合的映射
key_num = len(dataset) # 当形成新的集合时,需要新的key值
dist = get_dist(dataset) # 获取任意两点之间的距离
for i in range(len(dataset)): # 遍历数据集
id_to_key[i] = str(i) # 编号到key的映射,编号就是下标,key值就是下标的字符串形式
key_to_set[str(i)] = set() # 集合
key_to_set[str(i)].add(dataset[i].name) # 集合内存放该数据点的名字
for i in range(len(dataset)):
count = 0 # 计数,符合条件的数据点的个数
t_list = []
for j in range(len(dataset)): # 寻找小于半径的数据点
if dist[i][j] <= r:
count += 1 # 计数加一
t_list.append(j) # 放入临时列表中
if count >= min_point: # 如果数据点个数大于等于要求的点数
union_set = set() # 定义新集合
key_ = str(key_num) # 新集合需要映射的key值
for id in t_list:
key = id_to_key[id] # 上面找到的数据点,根据下标获取key值
if key not in key_to_set: # 如果集合中有多个数据点时,第一个数据点时可能就删除了,这个key值就没了
continue
s = key_to_set[key] # 根据key值找到相应集合
union_set = union_set.union(s) # 合并到新集合中
id_to_key[id] = key_ # 数据点下标映射到新key值
del key_to_set[key] # 删除旧集合
key_to_set[key_] = union_set # 新key值到新集合的映射
key_num += 1 # 更新key_num
# 每次输出一下结果
for v in key_to_set.values():
print(v)
print("-----------------------------------")
# 测试
dataset, id_point_dict = get_dataset()
r = 1
min_point = 4
DBSCAN(dataset, r, min_point)二、测试
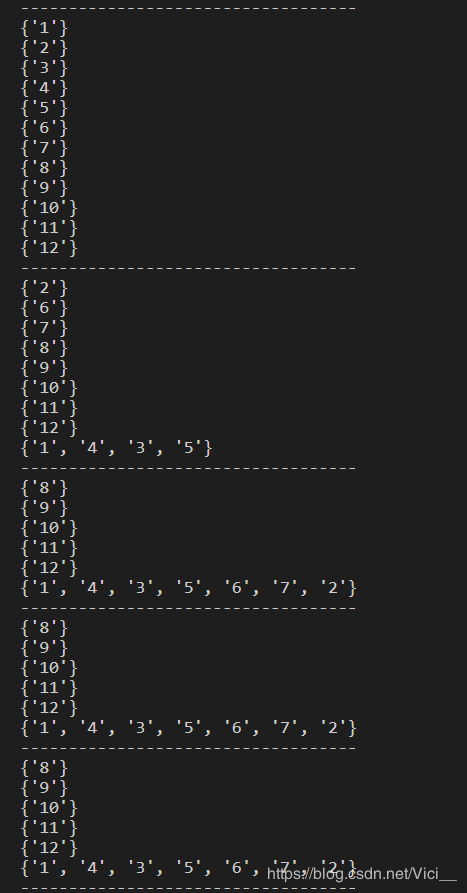
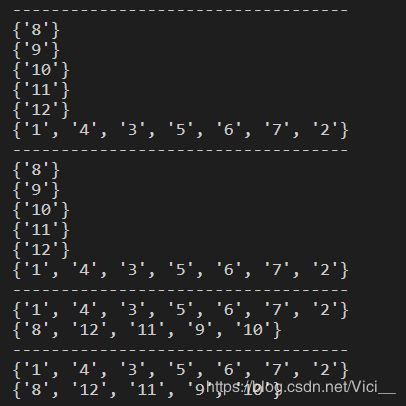
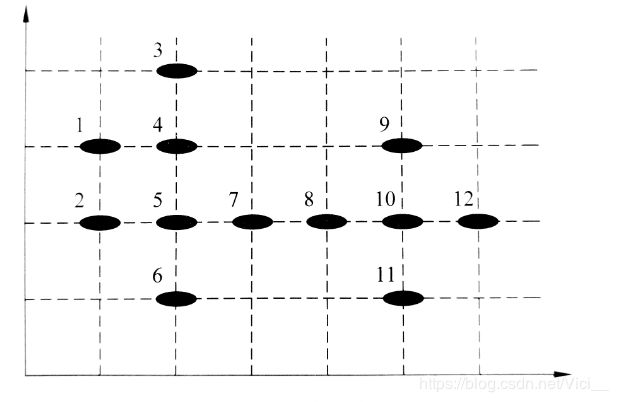
实验数据:设有12个样本点(样本点的具体坐标可以根据图中数据的位置获得,设横、纵坐标的单位间隔为1)。指定DBSCAN聚类的参数中:r=1,minPoints=4。假设有数据集如下图所示,将图中数据从上到下、从左到右依次进行编号如下:
结果: