Hadoop完全分布式系统安装与配置
硬件环境:
(1)CPU:AMD A8-4500APU with Radenon(tm) HD Graphics 1.9GH
(2)内存:4.00GB
注:内存一定要大些,因为要同时跑3台虚拟主机,每台主机分配256MB,都会有点卡;
软件环境:
(1)Windows 7 64位操作系统
(2)Ubuntu -12.04.3-server-i386
(3)VMware 9
(4)hadoop-0.20.2.tar.gz
(5)jdk1.6.0_20
(6)SecureCRT(用来管理3台虚拟主机,方便命令行输入和主机之间的切换)
安装步骤:
(1)安装VMware 9
(2)在VMware 9安装Ubuntu(注意安装选项应把samba(方便拷贝文件)、ssh、vi(用于编辑配置文件)、perl(有些脚本需要perl解释));
(3)在Ubuntu安装JDK;
(4)通过完全克隆上述安装好常用软件的Ubuntu虚拟机再生成2台虚拟主机;
(5)分别配置/etc/hosts为3个主机添加别名;
(6)配置ssh,生成密钥,使到ssh可以免密码连接各主机;
(7)分别在3台主机新建用户grid,并将hadoop-0.20.2.tar.gz包解压到/home/grid/目录下;
(8)配置/home/grid/hadoop-0.20/conf目录下面的/hadoop-env.sh、core-site.xml、hdfs-site.xml和mapred-site.xml三个核心配置文件;
(9)分发/home/grid/hadoop-0.20目录及其下面的所有文件到其它2台主机;
(10)在作为master的主机上,格式化HDFS;
(11)使用bin/start-all.sh启动Hadoop;
(12)运行一个简单的例子。
安装步骤详解:
一、安装VMware9
直接下载一个VMware的安装包,点击选择默认安装即可,但要注意操作系统的是32位安装32位版本的VMware,64位安装64位版本。
二、在VMware 9安装Ubuntu -12.04.3-server-i386
点击菜单"File"->"New Virtual Machine Wizard"
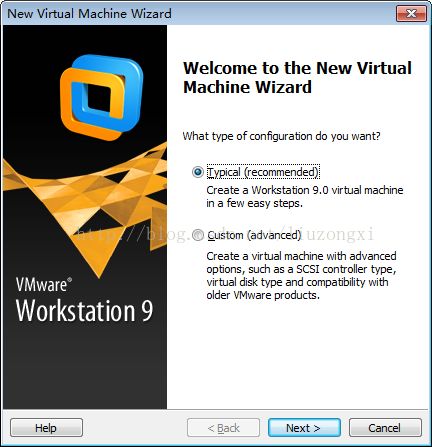
选择"Typical"。

三、在Ubuntu安装JDK
通过smaba建立一个共享目录,将jdk1.6.0_20.tar.gz包拷贝到共享目录下,将jdk1.6.0_20解压到/home/usr/jdk1.6.0_20目录下。
分别在3台主机新建用户grid。
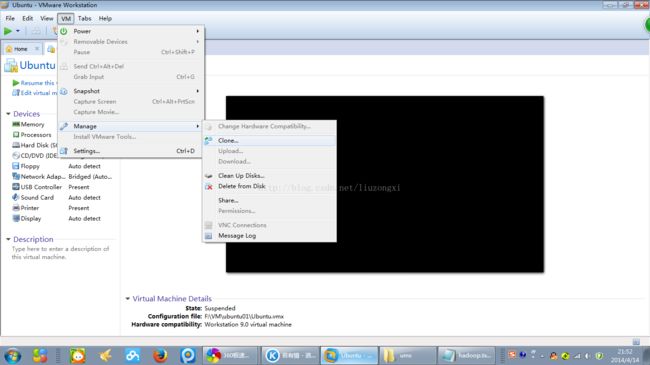
四、通过完全克隆上述安装好常用软件的Ubuntu虚拟机再生成2台虚拟主机
通过“Clone"建立虚拟主机的时候,本实验选择的是“完全克隆”,这样虽然所占的空间会大些,但可以保证各虚拟主机完全独立。
五、分别配置/etc/hosts为3个主机添加别名
分别修改每台虚拟主机/etc/hosts文件,为每个主机加上别名,这样不必记录每台主机的IP地址,只需知道主机别名即可。
192.168.125.106 h1 //第一台虚拟主机的IP地址为192.168.125.106 ,h1为该主机的别名
192.168.125.103 h2
192.168.125.104 h3
由于后面2个主机是通过克隆建立的,主机名相同,所有需要修改主机名,在本次试验中,分别改3台虚拟主机的主机名为h1、h2、h3,和/etc/hosts中的别名一致。
六、配置ssh,生成密钥,使到ssh可以免密码连接各主机
这里非常关键,配置不成功,主机之间无法分发文件。
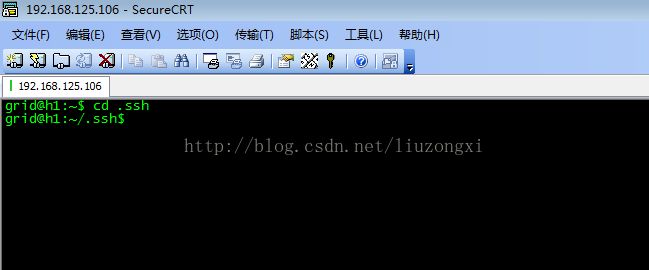
进入当前用户的目录,再进入/.ssh目录。
运行以下命令:
ssh-keygen -t rsa //一直回车,不要输入任何东西
cp id_rsa.pub authorized_keys //回车
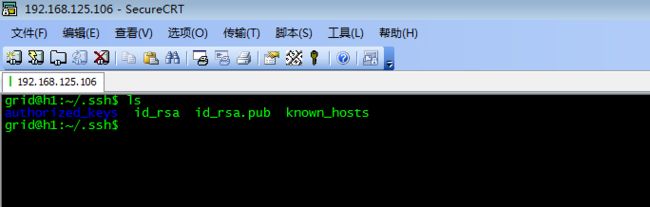
分别在其它2台主机上做同样的操作,然后将各个主机文件生成的authorized_keys内的内容合并,然后将合并后的文件覆盖/home/grid/.ssh下旧的authorized_keys文件,这样主机之间的免密码接入就配置好了。
七、将hadoop-0.20.2.tar.gz包解压到/home/grid/目录下
通过smaba共享目录,将hadoop-0.20.2.tar.gz包拷贝到共享目录下,将jdk1.6.0_20解压到/home/grid/目录下。
八、配置/home/grid/hadoop-0.20/conf目录下面的/hadoop-env.sh、core-site.xml、hdfs-site.xml和mapred-site.xml三个核心配置文件,配置masters和slaves
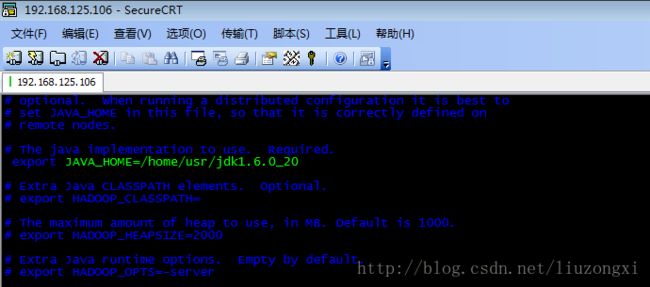
(1)配置hadoop-env.sh, 配置JAVA_HOME=JAVA_HOME=/home/usr/jdk1.6.0_20
vi hadoop-env.sh
(2)配置core-site.xml
vi core-site.xml
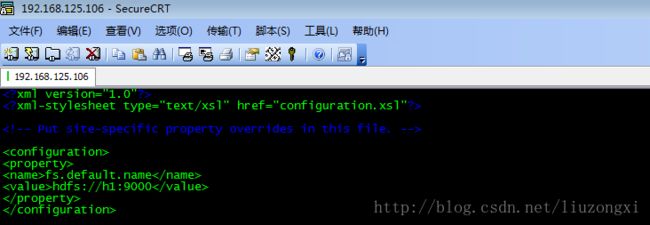
(3)配置hdfs-site.xml
vi hdfs-site.xml
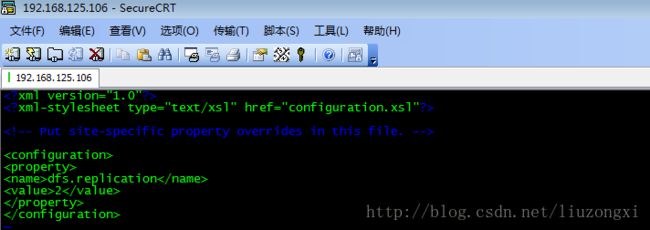
(4)配置mapred-site.xml
vi mapred-site.xml
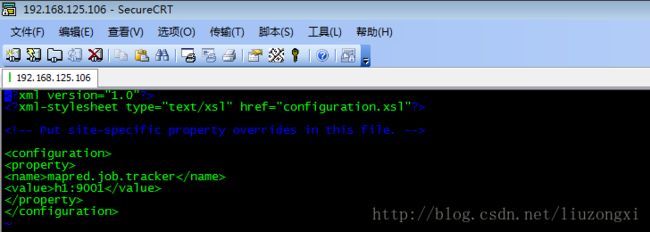
(5)配置masters和slaves
vi master //在文件后面加“h1”
vi slaves //在文件最后加“h2和h2”
九、分发/home/grid/hadoop-0.20目录及其下面的所有文件到其它2台主机
进入/home/grid目录,逐一运行以下命令:
scp -r ./hadoop-0.20.2 h2:/home/grid
scp -r ./hadoop-0.20.2 h2:/home/grid
十、在作为master的主机上,格式化HDFS
进入/home/grid目录,运行以下命令:
bin/hadoop namenode -format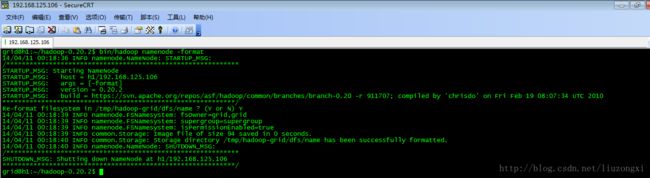
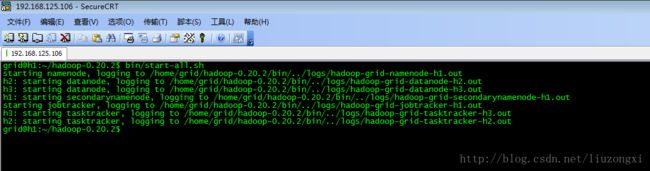
十一、使用bin/start-all.sh启动Hadoop
进入/home/grid目录,运行以下命令:
bin/start-all.sh
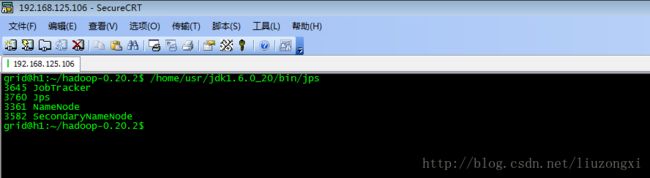
在h1运行指令:/home/usr/jdk1.6.0_20/bin/jps
在h2中运行指令:/home/usr/jdk1.6.0_20/bin/jps
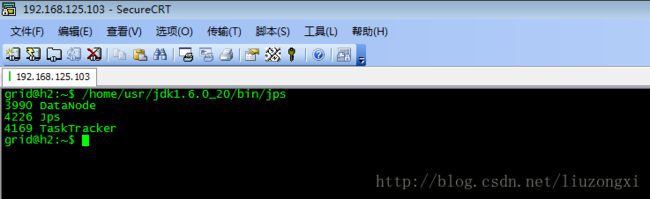
十二、运行一个简单的例子
该例子主要实现的是统计input文件夹中所有文件中各单词出现的次数。
在/home/grid目录下创建一个文件夹“input”,再将“hello world”写入test1.txt文件,将“hello hadoop”写入test2.txt文件。
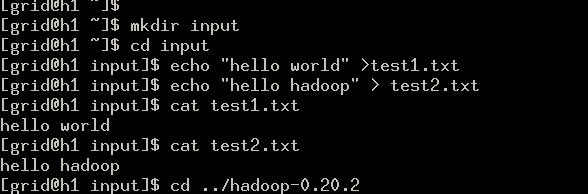
往dfs写入文件,并查看文件是否存在。

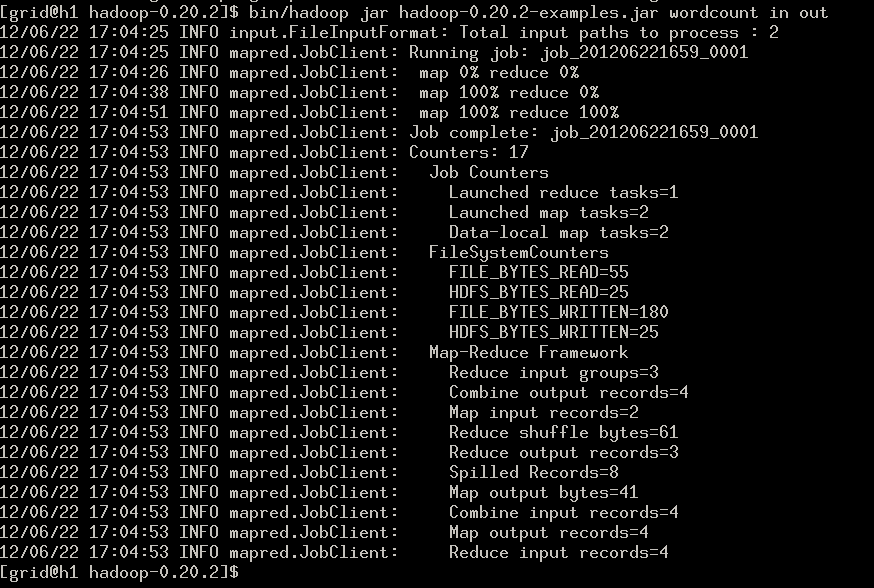
执行程序。
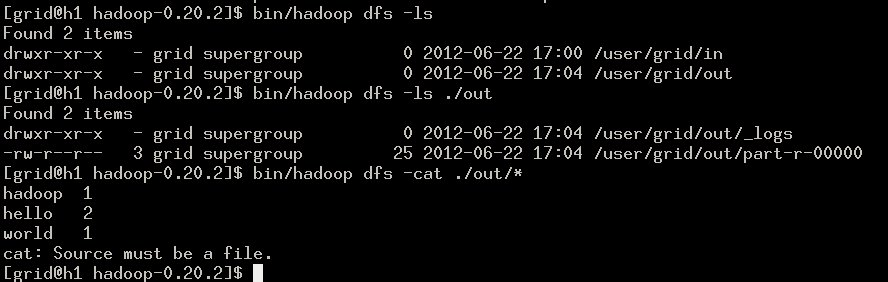
查看结果。
文本是在本人学习dataguru的视频教程后,根据个人实验整理,有待进一步完善。