Data Block段用来保存表中的数据,这部分可以被压缩。 Meta Block段(可选的)用来保存用户自定义的kv段,可以被压缩。 FileInfo段用来保存HFile的元信息,不能被压缩,用户也可以在这一部分添加自己的元信息。 Data Block Index段(可选的)用来保存Meta Blcok的索引。 Trailer这一段是定长的。保存了每一段的偏移量,读取一个HFile时,会首先读取Trailer,Trailer保存了每个段的起始位置(段的Magic Number用来做安全check),然后,DataBlock Index会被读取到内存中,这样,当检索某个key时,不需要扫描整个HFile,而只需从内存中找到key所在的block,通过一次磁盘io将整个 block读取到内存中,再找到需要的key。DataBlock Index采用LRU机制淘汰。 HFile的Data Block,Meta Block通常采用压缩方式存储,压缩之后可以大大减少网络IO和磁盘IO,随之而来的开销当然是需要花费cpu进行压缩和解压缩。(备注: DataBlock Index的缺陷。 a) 占用过多内存 b) 启动加载时间缓慢)
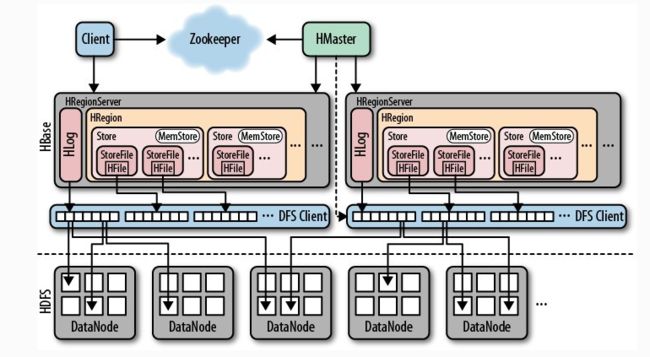
HLog
HLog(WAL log):WAL意为write ahead log,用来做灾难恢复使用,HLog记录数据的所有变更,一旦region server 宕机,就可以从log中进行恢复。
项目需要当某事件触发时,执行http请求任务,失败时需要有重试机制,并根据失败次数的增加,重试间隔也相应增加,任务可能并发。
由于是耗时任务,首先考虑的就是用线程来实现,并且为了节约资源,因而选择线程池。
为了解决不定间隔的重试,选择Timer和TimerTask来完成
package threadpool;
public class ThreadPoolTest {
首先要说的是,不同版本数据库提供的系统表会有不同,你可以根据数据字典查看该版本数据库所提供的表。
select * from dict where table_name like '%SESSION%';
就可以查出一些表,然后根据这些表就可以获得会话信息
select sid,serial#,status,username,schemaname,osuser,terminal,ma
Admin类的主要方法注释:
1. 创建表
/**
* Creates a new table. Synchronous operation.
*
* @param desc table descriptor for table
* @throws IllegalArgumentException if the table name is res
public class LinkListTest {
/**
* we deal with two main missions:
*
* A.
* 1.we create two joined-List(both have no loop)
* 2.whether list1 and list2 join
* 3.print the join
事件回顾:由于需要修改同一个模板,里面包含2个不同的内容,第一个里面使用的时间差和第二个里面名称不一样,其他过滤器,内容都大同小异。希望杜绝If这样比较傻的来判断if-show or not,继续追究其源码。
var b = "{{",
a = "}}";
this.startSymbol = function(a) {