监督式学习 -- 分类决策树(一)
决策树(decision tree)是一种基本的分类与回归方法。其表示的树型结构,可以认为是if-else规则的集合。主要的优点是分类可读性好,速度快。通常会有三个步骤:特征选择、决策树的生成和决策树的修剪。
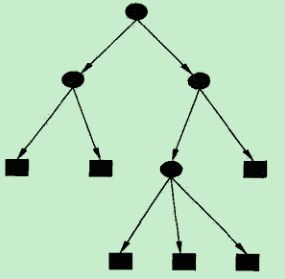
决策树由结点(node)和有向边(directed edge)组成,结点有两类:内部结点(表示一个特征或者属性)和叶节点(表示一个类或者决策结果)。决策树学习样本集,学习的目标是根据给定的训练数据集构建决策树模型,能够对测试集以及实例进行正确的分类。通常默认,训练集和测试集拥有相同或近似的分布概率模型。
从所有可能的决策树中选取最优决策树是NP完全问题,所以通常采用启发式方法,近似求解这一最优问题,得到的决策树是次最优(sub-optimal)。由于决策树表示一个条件概率分布,所以深浅不同的决策树对应复杂度不同的概率模型。决策树的生成只考虑局部最优(贪心算法),决策树的剪枝则考虑全局最优。
信息增益和信息增益率
特征选取在于选择对训练数据集具有分类能力的特征,这样可以提高决策树的学习效率。如果一个特征进行分类的结果与随机分类的结果没有很大的区别,那这个特征的分类能力很差或者几乎没有。
1)信息熵
信息熵是信息论中的基本概念。信息论由Shannon于1948年提出并发展起来,用于解决信息传递过程中的问题,也称统计通信理论。它认为:
1、信息传递由信源、信道和信宿组成;
2、传递系统存在于一个随机干扰环境中,因此传递系统对信息的传递是随机误差的。如果把发送信息记为U而接收到信息记 V,由信道可记为通信模型,为P(U|V)。信道模型是一个条件概率矩阵P(U|V)。
在实际通信前,信宿信源会发出什么信息不可能知道,称为信宿对信源状态具有不确定性,由于这种不确定性是发生在通信之前的,故称为先验不确定性。在收到信息后的不确定性,称为后验不确定性。
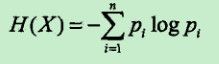
信息是指对不确定性的消除。
Shannon 借鉴了热力学的概念,把信息中排除了冗余后的平均信息量称为“信息熵”,并给出了计算信息熵的数学表达式。变量的不确定性越大,熵也就越大,把它搞清楚所需要的信息量也就越大。
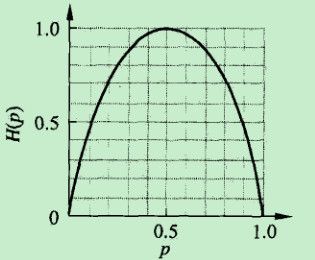
信息熵是信息论中度量信息量的一个概念。一个系统越有序,它的信息熵越小;反之,一个混乱的系统信息熵越大。可以认为,信息熵是系统有序化程度的一个度量。
2)信息增益
信息熵又称为先验熵,是在信息发送前信息量的数学期望;后验熵指在信息发送后,从信宿角度对信息量的数学期望。一般先验熵大于后验熵,先验熵与后验熵估差,即所谓的信息增益,反映的是信息消除随机不确定性的程度。
决策树学习中的信息增益等价于训练集中类与特征的互信息。表示由于特征A而导致训练集不确定性的减少量,信息增益也。特征A对训练集D的信息增益g(D, A),定义为集合D的经验熵H(D)与特征A给定条件下的经验条件熵H(D|A)之差:
3)信息增益率
信息增益值得大小是相对训练集而言,并没有绝对的意义。
举一个例子,火车的速度能在9s内从10m/s加速到100m/s,但是现在有一辆摩托车能在1s内从1m/s加速到11m/s,虽然加速后摩托车的速度不如火车,但是它拥有和火车等同的加速能力!
在训练集的经验熵大的时候,信息增益值也会偏大,反之信息增益值会偏小,不能反映真实的不确定改善能力。使用信息增益率(information gain ratio)可以对这一问题进行校正。
特征A对训练集D的信息增益率gainRatio(D, A),定义为其信息增益g(D, A)与训练数据集D的经验熵H(D)之比:

决策树学习之ID3算法
ID3算法是决策树算法的一种。想了解什么是ID3算法之前,我们得先明白一个概念:奥卡姆剃刀(Occam'sRazor, Ockham's Razor),是由14世纪逻辑学家、圣方济各会修士奥卡姆的威廉(William of Occam,约1285年至1349年)提出,他在《箴言书注》2卷15题说“切勿浪费较多东西,去做‘用较少的东西,同样可以做好的事情’。简单点说,便是:be simple。因此,越是小型的决策树越优于大的决策树(be simple简单理论)。
ID3算法的实现思想:
1)自顶向下贪婪遍历决策树空间以构造决策树;
2)计算单独特征属性分类训练样本集的能力,选取分类能力最好的一个属性(最佳属性)作为决策树的根节点,以此表示该属性相比其它属性拥有更强的区分能力。
3)对于根节点属性可能产生的每一种可能构建一个分支,再次遍历样本集将其划分到不同分支。
4)递归的对每个分支重复2)、3)。直到出现叶子节点,也即分支下只有预测的结果。
ID3相当于用极大似然法进行概率模型的选择。
C4.5算法:ID3算法的改进
既然说C4.5算法是ID3的改进算法,那么C4.5相比于ID3改进的地方有哪些呢?
1)用信息增益率来选择属性。ID3选择属性用的是子树的信息增益,这里可以用很多方法来定义信息,ID3使用的是熵(entropy,熵是一种不纯度度量准则),也就是熵的变化值,而C4.5用的是信息增益率。对,区别就在于一个是信息增益,一个是信息增益率。
2)在树构造过程中进行剪枝,在构造决策树的时候,那些挂着几个元素的节点,容易导致overfitting。
3)对非离散数据也能处理。能够对不完整数据进行处理。