【论文阅读】从pix2pix到pix2pixHD
pix2pix:Image-to-Image Translation with Conditional Adversarial Networks (CVPR 2017)论文 github
pix2pixHD:High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs (CVPR 2018) 论文 github
前言
许多与图像有关的问题都可以理解为图像翻译问题,即输入图像到输出图像的变换。这些问题的实质都是一样的:从像素映射到像素,非常适合利用GAN来解决问题。
GAN包含generator(生成器,以下简称G)和discriminator(判别器,以下简称D)两个部分,训练有两个步骤:
- 首先固定G的参数,将生成的图像和真实图像一起交给D,D尽可能地学会区分真假图像并打分
- 根据D打分的反馈,G进行参数调整,再重新生成图像交给D
在这个循环往复的过程中,D相当于一个损失函数,给G提供梯度更新的方向。
图源: CVPR_2018 pix2pix幻灯片

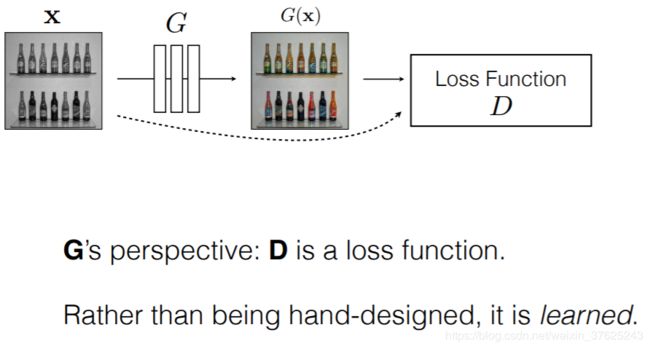
如上所述,GAN不仅学习到图像与图像之间的映射,还能学习到用于训练这个映射的损失函数,可以惩罚任何输入和目标之前有差异的结构,无需对不同的问题手动制定不同的损失函数,从而能将通用方法应用于各种损失函数原本不同的问题,而且初始设置比专注于特定应用的模型更简单。
但是,对于图像翻译问题,传统GAN存在两个方面的问题:
- 缺少用户控制
- 低分辨率和低质量问题
为了改善这两个问题,相应的目标就是:
- 提高GAN的用户控制能力
- 提高GAN生成图片的分辨率和质量
pix2pix和pix2pixHD就分别对应这两个目标的实现。
参考:一文读懂GAN, pix2pix, CycleGAN和pix2pixHD(CycleGAN作者朱俊彦博士的线上报告总结)
pix2pix
pix2pix基于cGAN(conditioanl GAN),为图像翻译问题开发一个通用的框架。
pix2pix需要使用成对的数据进行训练。
cGAN
cGAN与原始GAN的不同之处在于,GAN是学习随机噪声z到输出图像y的映射的生成式模型,而cGAN是学习随机噪声z和条件变量x到输出图像y的映射。
不过,在pix2pix中,作者没有将随机噪声z作为输入的一部分。对于cGAN,在输入足够复杂的情况下,输入可以扮演噪声的角色,因此不需要再引入噪声,而且作者在实验中发现,随着z的改变,模型的输出结果并没有太大的变化。
具体来说,因为原始GAN过于自由,没有用户控制能力,在某种极端情况下,G可能不管输入是什么,都生成相同的能让D打高分的图像。
这与我们想要的结果不符。因此,在作者使用的cGAN中,将G的输入和输出一起给D作为输入,增加指导性的额外条件( x x x),帮助D进行判断。

x x x可以是任何信息,比如上图中的边线图,还可以是类别标签等,给GAN增加条件,让D明白好的图像不仅要求看起来“真”,也要与提出的条件相匹配,从而控制G生成与条件相匹配的图像。
参考:台大李宏毅老师课程
Method
本文中,作者使用DCGAN的结构作为G和D的基本结构。
其中G的第i层和第n-i层之间添加残差连接,使其形成类似于U-Net的结构;对于D,仅对一个patch大小范围内的图像部分进行惩罚,形成“PatchGAN”分类器。
DCGAN

DCGAN与传统GAN的不同之处在于
- DCGAN的网络是全卷积的,而不是原始GAN中的多层感知机
- 生成器除最后一层外都加batchnorm,鉴别器则是第一层没加bacthnorm
- 鉴别器中的激活函数使用的是leaky_relu,负斜率是0.2
- 生成器中的激活函数使用relu,输出层采用tanh
- 采用Adam优化算法,学习率是0.0002,beta1=0.5
损失函数
虽然L1或L2损失函数会造成生成图像的模糊,但是已经足够能够捕捉低分辨率的正确特征,因此只需要让GAN的判别器D对高分辨率的结构进行建模,靠L1损失项去实现低分辨率的正确性即可。模型的损失函数如下图所示:![]()
λ \lambda λ是比例系数
Generator
G使用的是DCGAN的结构,加上镜面对称位置的网络层之间的残差连接,形成类似U-Net的结构
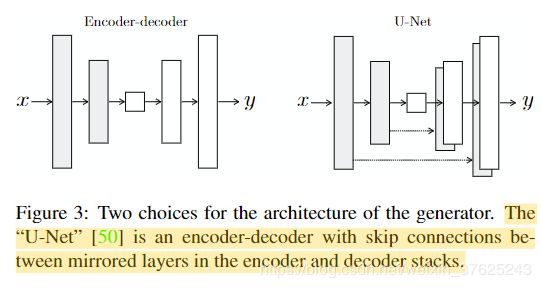
增加了残差连接之后,图像的模糊问题大大减轻,更好地保留了原图中的细节。

Discriminator
作者将D的结构命名为PatchGAN,将图像划分成很多个Patch,并对每一个Patch使用D进行判别,最后以整张图上所有patch的loss的平均值为最终结果。实验证明,即使N比图像实际大小小很多,也能取得很好的效果。

pix2pixHD
如果用图形学的方法渲染真实场景的图像,需要对每个部分建模,非常昂贵、耗时。若能从数据中学习一个模型,即可将此过程转化为模型学习和推断,渲染新的场景只需要重新在数据集上训练;用户也可通过语义自定义,无需重新对几何形状、材质、光线建模。
pix2pix baseline
pix2pix存在两个问题:
- 用GAN很难生成高分辨率的图
- 高分辨率图中会损失细节
为支持交互语义操作,作者试图在两个方向上扩展模型:
- 使用实例级别的目标分割信息,将相同类别的不同物体分为不同实例
- 为同一输入生成多种输出,方便改变物体的外观
此外,作者提出了新的损失函数和新的多尺度G和D,不仅可以使用条件GAN训练高分辨率的图像的过程稳定下来,也可以得到更好的结果。
提高真实性和分辨率
具体来说,作者对结构做出了以下三个部分的改动:
- 不断进行提纯的G(Coarse-to-fine generator)
- 多尺度D(Multi-scale discriminators)
- 对抗学习目标函数
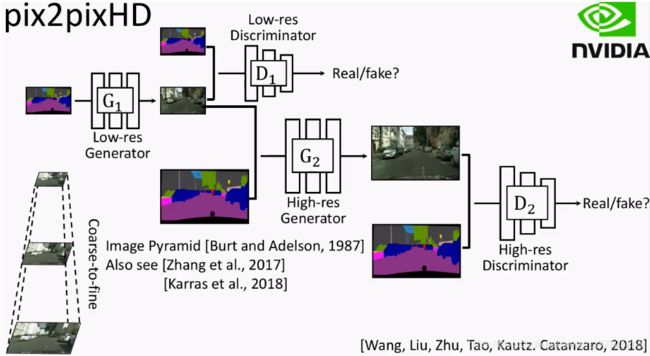
图源:一文读懂GAN, pix2pix, CycleGAN和pix2pixHD(CycleGAN作者朱俊彦博士的线上报告总结)
Generator
将G分为两个子模块:全局 G 1 G_{1} G1和局部增强 G 2 G_{2} G2。
全局 G 1 G_{1} G1操作1024x512大小的图像,局部增强 G 2 G_{2} G2输出与其接受的输入相比,在宽和高上各扩大两倍的图像。要合成更高分辨率的图像,再往上加局部增强G模块即可
全局 G 1 G_{1} G1包含三个部分:
- 卷积前置网络 G 1 ( f ) G_{1}^{(f)} G1(f)
- 一系列残差块 G 1 ( R ) G_{1}^{(R)} G1(R)
- 转置卷积后端网络 G 1 ( B ) G_{1}^{(B)} G1(B)
输入的条件信息图大小为1024x512,按顺序穿过三个部分,输出相同大小的图。
局部 G 2 G_{2} G2包含的三个部分同上。略微不同的是, G 2 ( f ) G_{2}^{(f)} G2(f)接受的输入为2048x1024,且为了将 G 1 G_{1} G1获得的全局信息融合到 G 2 G_{2} G2, G 2 ( R ) G_{2}^{(R)} G2(R)接受的输入为 G 2 ( f ) G_{2}^{(f)} G2(f)与 G 1 ( B ) G_{1}^{(B)} G1(B)的和。
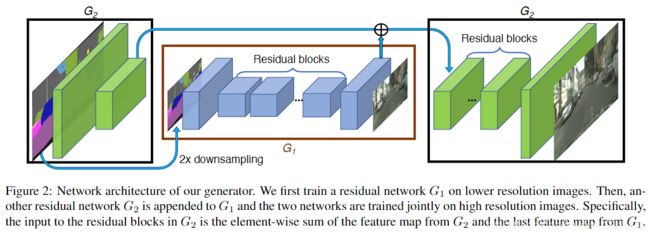
训练时,先在低分辨率图像上训练残差网络 G 1 G_{1} G1,再和另一个残差网络 G 2 G_{2} G2在高分辨率图像上一起fine-tune。
Discriminator
为生成高分辨率的真假图像,D必须有大的感知野。因此须有更深的网络或更大的感知野。但这两个选项都可能会造成过拟合,且需要大量内存。
作者就此提出多尺度D,使用三个有相同网络结构但对不同大小图像进行操作的D,对真假高分辨率图像进行2或4的下采样。对最粗糙的图像(分辨率最小的)进行操作的D有最大的感知野,对图像有更全局的认识,指导G产生全局上一致的图像对最细致的图像(分辨率最大的)进行操作的D专门指导G生成细节。
这让训练提纯G更容易,因为将低分辨率的模型扩大到高分辨率只需要在增加一个额外的D,而无需从头开始训练。若没有多尺度D,生成图中会出现很多重复的图案。
损失函数
D是多尺度的,因此修改GAN的loss部分为一个多任务问题:

在上述loss基础上,因为模型结构中存在多尺度,所以增加一个特征匹配loss,用于稳定GAN的训练。从D的多个层中提取特征,学习匹配真实图像和合成图像的中间表示:
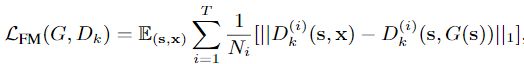
D k ( i ) D_{k}^{(i)} Dk(i):第k个D的第i层的特征
N i N_{i} Ni:每层中总的元素个数
T T T:总层数
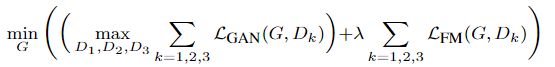
最后的总loss如上式所示。
下面是对于从语义标签图生成逼真图像的两个优化。
改进输入
现有的图像合成方法只利用语义标签图(semantic label map):每个像素值代表其归属的目标的类别的图,但无法区分同一类别的不同物体。而实例级的语义标签图通过赋予每个目标唯一的ID弥补这个不足。
如何实现呢?一般来说有三种方法:
- 直接传入网络
- 使用one-hot向量
- 为每个类预先分配固定数量的特征映射
但以上方法都有较明显的缺点,实施起来较为困难。
作者分析,实例图提供的最重要的信息是物体的边界。为了提取该信息,首先计算出实例边界图(Instance boundary map,若某个像素的ID与周围四个像素中的任意一个不同则为1,否则为0)。

将实例边界图与用one-hot向量表示的语义标签图拼接作为G的输入。D的输入是实例边界图,语义标签图,真/假图像在通道上的拼接。
学习实例级别的特征编码
图像合成是一个一对多映射问题(one-to-many)。现有的一对多模型关注图像的颜色、纹理的整体变化,无法解决对图像在物体级别上的控制。作者提出加入额外的低维特征通道作为G的输入。由于特征通道是连续量,理论上可以生成无限个图像。
为了得到低维特征,需要训练一个编码器E,为每个实例生成与ground truth中的目标相对应的低维特征。为了保证在每个实例范围内的特征是一致的,在编码器的输出处加入一个实例级的平均池化层,计算实例的平均特征,然后将平均特征向该实例的所有像素位置传播。
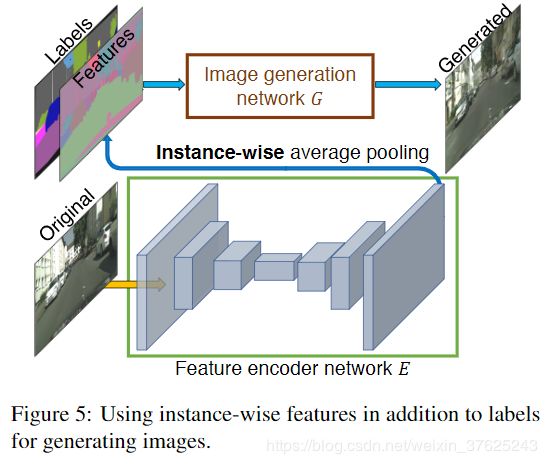
训练好编码器后,在训练图像上的每个实例上跑一遍,记录下得到的特征,接着为每个语义类别的特征进行K均值集簇,每个簇为每个特征编码一个特定的风格,如一条路的材质是沥青还是卵石,这样就给自定义风格提供了方案。在inference阶段,随机选择一个簇作为编码的特征,与标签图拼接,作为G的输入。
与其他模型生成的高分辨率图像比较,该模型生成的图像细节更真实,更清晰。

