Pytorch在Windows下的环境搭建以及模型训练
学习一个工具最好的方法就是去使用它。在学习「深度学习」的路上,你需要选择一个用来搭建神经网络的框架,常见的框架包括 Tensorflow,Caffe,Pytorch 等, 其中最推荐的是 Pytorch,尤其是对于新手,Pytorch 入门快,易上手,代码非常 pythonic。不论你是自己做 demo 还是做产品级的应用,Pytorch 都能胜任,实在是居家旅行必备。
##环境搭建
首先需要搭建软硬件环境,如果有 GPU 的话那最好,没有的话也没关系,跑 demo 还是可以的。如果数据集大的话还是需要 GPU 做支持,GPU 的训练速度是 CPU 的 10 倍以上。操作系统推荐 Linux,我由于工作需要已经把之前的 Linux 换成了 Windows,就主要介绍 Windows。环境搭建的大致步骤如下,如果碰到问题欢迎在下方留言讨论。
- 安装 python,推荐 python3,本人安装的是 3.7,直接去官网下载 exe 安装即可,要注意的是安装过程中需要勾选 “将其添加到环境变量” 选项,这样就可以直接在命令行输入 python 进入 python 提示符界面了。
- 如果有 GPU 的话需要安装 GPU 对应的驱动以及 CUDA,驱动直接官网找到对应显卡版本下载安装,CUDA 的话直接搜索 CUDA 点击进入系统选择页面选择自己的系统版本 Download,下载完成安装一下就好了。安装完成之后可以在 “C:\Program Files\NVIDIA Corporation\NVSMI” 路径下面运行一下 nvidia-smi.exe 确认安装成功。
NVIDIA 官网驱动下载页: https://www.nvidia.com/Download/index.aspx
CUDA 下载页: https://developer.nvidia.com/cuda-downloads - 安装 pytorch 和 torchvision。在 pytorch 官网主页就可以选择需要的版本以及安装方式,推荐直接 pip 安装,两行命令搞定。
pytorch 官网: https://pytorch.org/get-started/locally/

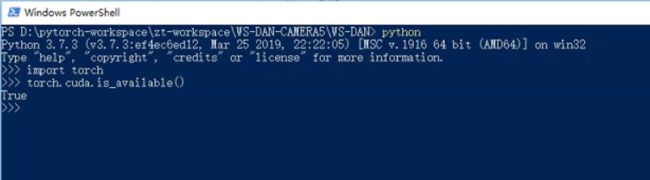
安装完成之后在命令行里验证一下有没有实际安装成功,成功的话应该跟我一样:
模型训练
训练模型中最重要的就是训练集的准备,模型就像是一个小孩子,一开始他啥也不知道,训练的过程就是在“教”他一些。要是一开始“教”的就是错的,那么也不可能期望他能在考试的时候把题目答对是不是。训练集的准备通常需要耗费大量人力物力,所以现在正在往半监督或无监督的方向发展,这是后话。啰嗦这么多,其实我就是想强调训练集的重要性,因为之前吃过亏,在这里提醒一下大家。
这里我使用开放数据集做为例子:
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True, num_workers=1)
valset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
valloader = torch.utils.data.DataLoader(valset, batch_size=64, shuffle=False, num_workers=1)
datasets = {"train":trainset, "val":valset}
dataloaders = {"train":trainloader, "val":valloader}
torchvision 中集成了一些开放数据集,可以直接下载。上面的代码创建了训练集和验证集的数据加载器,batch_size 表示每个 batch 中图片的数量,如果显存小的话可以设置小一点如(8/16/32),shuffle 表示是否打乱数据集,在训练的时候需要打乱,验证的时候自然不需要,num_workers 表示加载数据集的进程数,需要注意在 Windows 上该参数只能设置为1,否则会报错。在 Linux 上可以设置得大一点加快训练速度。
你也可以定义自己的数据集,只需要继承torch.utils.data.Dataset,然后实现一下自己的 getitem() 和 len() 就可以。下面是一个最简单的例子,你可以根据自己的需求定制:
class MyDataset(Dataset):
def __init__(self, image_path, transform=None):
self.image_path = image_path
self.transform = transform
def __len__(self):
return 1
def __getitem__(self, index):
pic = Image.open(self.image_path).convert("RGB")
if self.transform:
pic = self.transform(pic)
return (index, pic)
训练集准备结束,可以开始编写训练代码:
model = torchvision.models.resnet18(pretrained=True)
model.fc = nn.Linear(model.fc.in_features, 10)
模型我们选用 torchvision 中集成的预训练好的 Resnet-18 模型,想要了解更多有关 Resnet 可以看看我的另一篇 经典分类网络 ResNet 论文阅读及PYTORCH示例代码 ,因为这个数据集的输出有 10 种类型,所以最后全连接层的输出改成了 10。
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
定义损失函数及优化器,这里采用了 交叉熵 作为最优化的目标,优化器采用 SGD,初始学习率为 0.01,动量 0.9,这些都是比较常用的参数值。
cuda = torch.cuda.is_available()
if cuda:
model.cuda()
best_accuracy = 0.0
start_time = time.time()
epoches = 5
for epoch in range(epoches):
print('Epoch {}/{}'.format(epoch, epoches - 1))
print('-' * 40)
since_epoch = time.time()
for phase in ["train", "val"]:
if phase == "train":
model.train()
else:
model.eval()
running_loss = 0.0
running_corrects = 0
for data in dataloaders[phase]:
inputs, labels = data
# put data on GPU
if cuda:
inputs = inputs.cuda()
labels = labels.cuda()
# init optimizer
optimizer.zero_grad()
# forward
outputs = model(inputs)
_, preds = torch.max(outputs.data, 1)
# loss
loss = criterion(outputs, labels)
if phase == "train":
# backward
loss.backward()
# update params
optimizer.step()
# total loss
running_loss += loss.item() * inputs.size(0)
# correct numbers
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / len(datasets[phase])
epoch_acc = float(running_corrects) / len(datasets[phase])
time_elapsed_epoch = time.time() - since_epoch
print('{} Loss: {:.4f} Acc: {:.4f} in {:.0f}m {:.0f}s'.format(
phase, epoch_loss, epoch_acc, time_elapsed_epoch // 60, time_elapsed_epoch % 60))
if phase == "val" and epoch_acc >= best_accuracy:
best_accuracy = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
time_elapsed = time.time() - start_time
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_accuracy))
model.load_state_dict(best_model_wts)
上面就是一个基本的模型训练的 backbone,有一些打印可以看见训练的过程,我稍微写了些注释,有问题的话欢迎留言讨论。看一下训练结果:

可以看到随着训练的进行,训练集跟测试集的准确率都在逐步上升,后面在 loss 稳定不变的时候可以尝试降低学习率等调参方法来训练。
最后,除了 torchvision 中自带的预训练的模型之外,另外在介绍一个库,叫做 pretrainedmodels,里面包含了很多比较新的预训练好的模型,用起来也非常方便,强烈推荐。安装:
pip install pretrainedmodels
使用起来一样简单,这里以 se_ResNeXt101 为例:
model_name = "se_resnext101_32x4d"
model = pretrainedmodels.__dict__[model_name](num_classes=1000, pretrained='imagenet')
model.avg_pool = nn.AvgPool2d(int(image_size / 32), stride=1)
model.last_linear = nn.Linear(model.last_linear.in_features, your_num_classes)
首先确认你想要用的模型,用其对应名称初始化该模型。需要注意的是这里不仅改变了最后一层的全连接层,为了维度匹配也改变了前面的池化层,因为这个模型默认的输入图片大小为(448, 448),跟这个不一样的话就要匹配一下。pretrainedmodels 的 github地址:https://github.com/Cadene/pretrained-models.pytorch
PS:如果觉得对你有帮助的话,请帮我点赞噢,也欢迎 wx 搜索 [MachineLearning学习之路],和我一起学习 python,机器学习,计算机视觉 !