Yolov3源码darknet编译与训练(二)(Win10 + CUDA9.0 + VS2017)
在完成上一篇博客中的darknet的编译之后,我们便可以使用生成的darknet.exe文件来训练yolov3模型,进行目标检测任务。参照darknet官方教程。该教程文档中提供了VOC数据集,包括20个类别。这里我使用另外一个数据集,来自于武汉大学团队标注的开源数据集RSOD-Dataset。
1. 数据集准备
(1). 获取图片与标记
在RSOD-Dataset中下载某一类数据,这里我使用的是oiltank数据集(若是科研用途别忘记写cite~),用来训练Yolov3模型识别这一类对象。
下载解压之后,可以看到目录下有2个文件夹:JPEGImages\中包含165幅图片;Annotation\下包含每幅图片相应的标记,有2种标记形式,PascalVOC格式与YOLO格式,分别放在Annotation\下的xml文件夹和labels文件夹下,标记的命名与图片命名保持一致。
如果通过其他途径获得的数据标注中,只有PascalVOC格式的标注,可以用darknet源码里的scripts/voc_label.py进行格式转换。这里还推荐一个很不错的用于目标检测的图像标注开源工具:labelImg。
(2)修改标记
随意打开一个标记文件,发现其结构是![]()
第一列表示标记的图片名称,第二列表示对象名称,后四列分别为xmin, ymin, xmax, ymax。这个可是并非我们实际所需的YOLO标记格式,训练用的标记文件只能有五列,第一列表示对象类别 id,后四列表示对象归一化后的center_x, center_y, w, h。由于我们只有一个类,所以标记的第一列应全是0;后四列根据要根据xml标记中的xmin, ymin, xmax, ymax与图片width和height进行归一化。代码如下:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
wd = getcwd()
xmlfilepath = wd + '/Annotation/xml/'
txtfilepath = wd + '/labels/'
if not os.path.exists(txtfilepath):
os.mkdir(txtfilepath)
xml_list = os.listdir(xmlfilepath)
for i in range(len(xml_list)):
name = xml_list[i][:-4]
in_file = open(xmlfilepath + xml_list[i])
out_file = open(txtfilepath + name + '.txt', 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(0) + " " + " ".join([str(a) for a in bb]) + '\n')
in_file.close()
out_file.close()
请在oiltank\目录下运行该程序,成功运行后会在同一级目录下生成labels文件夹,文件夹下的.txt文件中的内容就是我们训练所需的标记数据。
(3). 生成包含训练数据的路径的文本文件
需要有一个文件来告诉模型训练及测试数据在哪里,即把所有用作训练的图片的路径写入一个文件文件:
import os
import random
imgfilepath = 'E:\\oiltank\\JPEGImages'
train_file = 'E:\\oiltank\\train_img.txt'
test_file = 'E:\\oiltank\\test_img.txt'
total_img = os.listdir(imgfilepath)
ftrain = open(train_file, 'w')
ftest = open(test_file, 'w')
train_file_prob = 0.8 # train imgs : test imgs = 4:1
total_file_num = len(total_img)
train_file_num = total_file_num * train_file_prob
file_index = list(range(total_file_num))
random.shuffle(file_index)
for i in file_index:
print(total_img[i])
name = imgfilepath + total_img[i] + '\n'
if i <= train_file_num:
ftrain.write(name)
else:
ftest.write(name)
ftrain.close()
ftest.close()
生成的train_img.txt与test_img.txt文件后续会用到。到这一步,训练测试用的图片与标记数据都已经准备完全了,请确保图片与标记在同一级目录下:

2. 训练模型
(1). 生成.data文件与.names文件
模型训练时,需要从一个.data文件中读取训练数据的信息,我在E:\oiltank\下新建oiltank.data文件:
//类别数目
classes= 1
//包含训练用图片路径的文本文件
train = E:\oiltank\train_img.txt
//包含测试用图片路径的文本文件
test = E:\oiltank\test_img.txt
//包含类别名称的文件
names = E:\oiltank\oiltank.names
//训练得到的weights文件的保存路径
backup = E:\oiltank\
在E:\oiltank\oiltank.names中写入类别的名称,即oiltank。
(2). 修改模型结构.cfg文件
这里我使用的是yolov3-tiny模型来训练,从darknet源码目录下的cfg\下拷贝yolov3-tiny_obj.cfg文件到E:\oiltank\下进行修改:
(a). 修改batch与subdivision
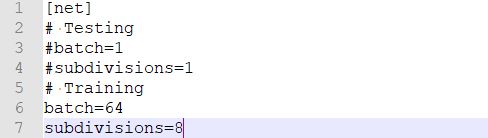
batch表示一个批次的样本数目。
(b). 修改classes数目
将第135行与第177行的classes=80修改为classes=1
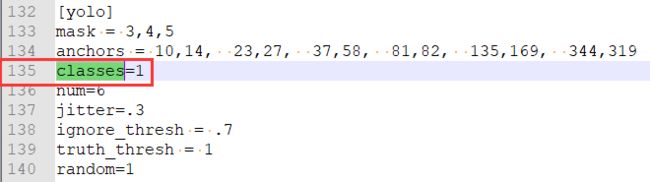
(c ). 修改filters数目
将模型里的yolo层的上一层的filters数目(第127行与)修改为(classes + 5)x3,比如原来有80个类时,filters=255;我们只有1个类,所以filters=18。

filter的计算式是:filters=(classes+coords+1)*< number of mask>;若mask缺失,则filters=(classes+coords+1)*num,Yolov2中使用的是后者。
修改以上3处后,保存退出。
(3). 训练
准备好训练数据与训练模型后,便可以用上一篇博客中编译好的darknet.exe进行训练了。
(a)从头开始训练
darknet.exe detector train E:\oiltank\oiltank.data E:\oiltank\yolov3-tiny_obj.cfg
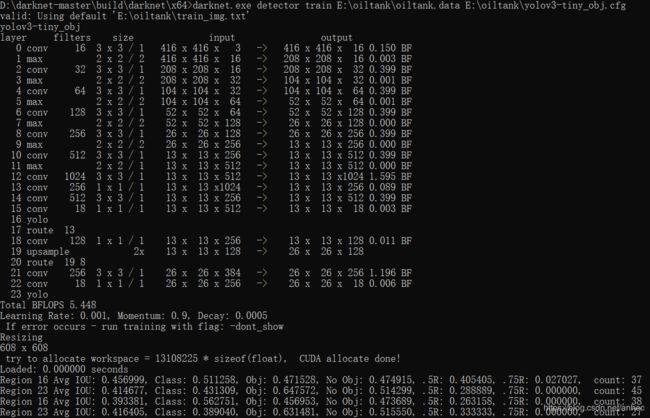
(b)使用预训练好的权重继续训练
权重下载:https://pjreddie.com/media/files/yolov3-tiny.weights,我下载到E:\oiltank\下,然后运行:
darknet.exe partial E:\oiltank\yolov3-tiny_obj.cfg E:\oiltank\yolov3-tiny.weights E:\oiltank\yolov3-tiny.conv.15 15
训练:
darknet.exe detector train E:\oiltank\oiltank.data E:\oiltank\yolov3-tiny_obj.cfg E:\oiltank\yolov3-tiny.conv.15
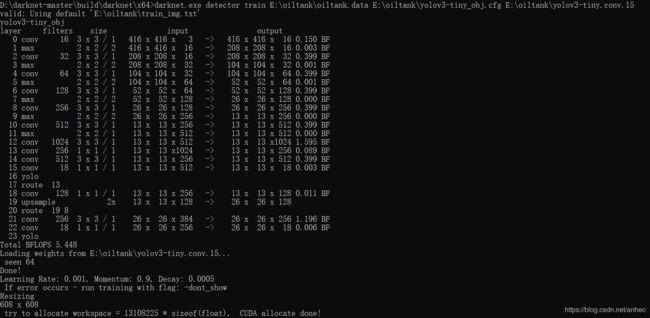
训练时,每个批次64幅图片,
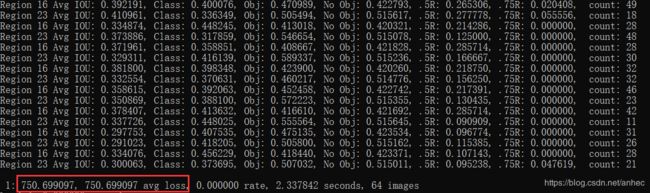
红框内表示训练集误差与测试集误差,当误差值不再下降时,可以停止训练。每1000个batch会保存一次模型的weights到oiltank.data文件中声明的backup路径下。
4. 测试
我训练到1000个批次左右时,loss值在3附近波动不再下降了,于是停止了训练:
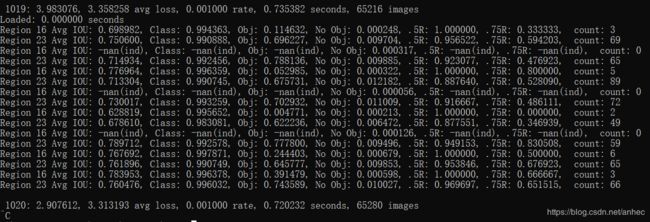
backup声明的路径E:\oiltank\下,生成了2个权重文件:
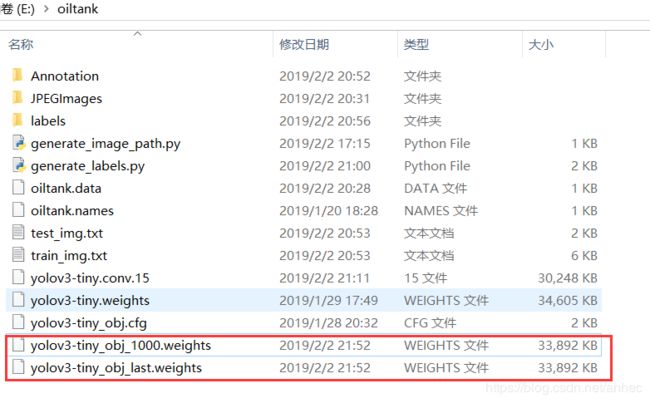
yolov3-tiny_obj_1000.weights是训练到第1000次时,模型的权重;yolov3-tiny_obj_last.weights是中止训练时模型的权重。
测试:
darknet.exe detector test E:\oiltank\oiltank.data E:\oiltank\yolov3-tiny_obj.cfg E:\oiltank\yolov3-tiny_obj_1000.weights
然后输入要测试的图片的路径:
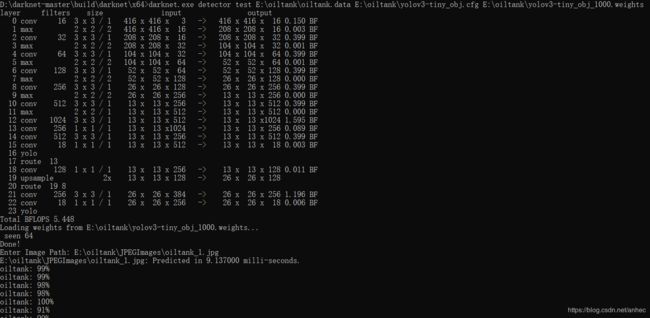
结果:
如果想要继续训练,运行命令:
darknet.exe detector train E:\oiltank\oiltank.data E:\oiltank\yolov3-tiny_obj.cfg E:\oiltank\yolov3-tiny_obj_1000.weights