Prometheus资源监控工具使用小结
文章目录
- 前沿
- Prometheus介绍
- Prometheus的特点
- Prometheus基本原理
- Prometheus的工作流程
- Prometheus组成及架构
- Prometheus Server
- Exporter采集器
- 其他组件
- Client Library
- Push Gateway
- Alertmanager
- PromQL
- Promql介绍
- 特性
- 完全匹配模式
- 使用正则表达式
- 范围查询和时间位移
- 聚合操作
- 数学运算,布尔运算,集合运算
- 可视化
- Prometheus Graph界面介绍
- 菜单
- Status 子菜单
- 使用Grafana作为Prometheus仪表盘
- 告警(Alertmanager)
- 一条典型的基于node_exporter的告警规则
- 参考文档
前沿
有段时间没有更新博客了,在保持低产这方面,我算是契而不舍了ε=ε=ε=ε=ε=ε=┌(; ̄◇ ̄)┘
虽然写的东西已经烂大街,也算是一种回顾,这种心路历程和对所写东西的理解才是本文中独一无二的东西,照例会把参考文档都写到最后以供参考。
上篇中主要介绍了Prometheus的部署、配置;
本章主要介绍Prometheus的使用。
(再次强调看官方文档的重要性)
主要包括5各部分:
- Prometheus介绍
- Prometheus 组成及架构
- PromQL使用
- 可视化
- 告警
每个部分不会尽善尽美,但足够起到抛砖引玉的作用
Prometheus介绍
Prometheus是由SoundCloud开发的开源监控报警系统和时序列数据库(TSDB)。Prometheus使用Go语言开发,是Google BorgMon监控系统的开源版本。
其性能足够支持上万台规模的集群。
Prometheus的特点
- 多维度数据模型。(所有的 metrics/指标数据 都可以设置任意的多维标签,可以对数据模型进行聚合,切割和切片操作)
- 灵活的查询语言。(PromQL:在同一个查询语句,可以对多个 metrics 进行乘法、加法、连接、取分数位等操作。)
- 易于管理:Prometheus server 是一个单独的二进制文件,可直接在本地工作,不依赖于分布式存储。
- 通过基于HTTP的pull方式采集时序数据。 可以通过中间网关进行时序列数据推送。(Push Gateway)
- 可以通过服务发现或者静态配置去获取监控的 targets。 支持多种多样的图表和界面展示,比如Grafana等。(可视化)
需要注意的是:由于数据采集可能会有丢失,所以 Prometheus 不适用对采集数据要 100% 准确的情形。但如果用于记录时间序列数据,Prometheus 具有很大的查询优势,此外,Prometheus 适用于微服务的体系架构。
上面的介绍里面有一些专属的名词数据,这些将在接下来进行介绍。
Prometheus基本原理
Prometheus的基本原理是通过HTTP协议周期性抓取被监控组件的状态,任意组件只要提供对应的HTTP接口就可以接入监控。不需要任何SDK或者其他的集成过程。
这样做非常适合做虚拟化环境监控系统,比如VM、Docker、Kubernetes等。输出被监控组件信息的HTTP接口被叫做exporter 。目前互联网公司常用的组件大部分都有exporter可以直接使用,比如Varnish、Haproxy、Nginx、MySQL、Linux系统信息(包括磁盘、内存、CPU、网络等等)。
Prometheus的工作流程
Prometheus server 定期从配置好的 jobs 或者 exporters 中拉 metrics,或者接收来自 Pushgateway 发过来的 metrics,或者从其他的 Prometheus server 中拉 metrics。
Prometheus server 在本地存储收集到的 metrics,并运行已定义好的 alert.rules,记录新的时间序列或者向 Alertmanager 推送警报。
Alertmanager 根据配置文件,对接收到的警报进行处理,发出告警。
在图形界面中,可视化采集数据。
Prometheus组成及架构

这个Prometheus及其套件的架构如图所示。
(查找过一些架构图,这张与我的理解最为符合,)
Prometheus Server
先来看看图上中间的Prometheus Server部分,其内部主要分为三大块:
- Retrieval是负责定时去暴露的目标页面上去抓取采样指标数据;
- Storage是负责将采样数据写磁盘;
- PromQL是Prometheus提供的查询语言模块,可以类比数据库SQL语言
上面描述中多次提到metric,metric是Prometheus监控的基石,没有metric,监控也就无从谈起了。
首先metric长这样:

上面就是Prometheus抓取的原始数据了,其中:
- Metric name代表了一类的指标,他们可以携带不同的Label
- 每个Metric name + Label组合成代表了一条时间序列的数据
- timestamp代表当前抓取时刻的时间戳
- value是指标数值
我们可以按照字面意思解读一下图中的一条数据:
http_request_total(status="200", method="GET") @14343317560938 94355
http_request_total应该是代表http请求总耗时,
括号里的是过滤条件,及返回状态200,方法为GET的http请求。
最后的数据94355表示总耗时,单位为微妙。
图中的指标目的是记录累计时间,他在Prometheus中被定义为计数器类型,除此之外,Prometheus Metric还有以下类型:
Counter:只增不减的计数器,可以在应用程序中记录某些事件发生的次数(e.g. http_requests_total,node_cpu)Gauge:可增可减的仪表盘,这类指标侧重于反应系统的当前状态,因此指标的样本数据可增可减。Histogram、Summary:用于分析数据分布情况(e.g. 监控CPU的平均使用率、页面的平均响应时间)
Prometheus本身通过时间序列存储数据(过去的数据一般是只读的,不会变更,当前时间的数据才会可能在写),存储形式为key-value,
使用了LevelDB的引擎(顺序读写性能非常高,本质是SSTables,排序字符串列表)
Exporter采集器
在Prometheus的架构设计中,Prometheus Server并不直接服务监控特定的目标,其主要任务是负责数据的收集,存储并且对外提供数据查询支持。
因此为了能够能够监控到某些东西,如主机的CPU使用率,我们需要使用到Exporter。Prometheus周期性的从Exporter暴露的HTTP服务地址(通常是/metrics)拉取监控样本数据。
以node exporter为例,搭载了node_expoter后,我们访问:http://xxx.xx.xx.xx/metrics,可以看到如下信息:

其中HELP用于解释当前指标的含义,TYPE则说明当前指标的数据类型。
其他组件
Client Library
客户端库,为需要监控的服务生成相应的 metrics 并暴露给 Prometheus server。当 Prometheus server 来 pull 时,直接返回实时状态的 metrics。
Push Gateway
主要用于短期的 jobs。由于这类 jobs 存在时间较短,可能在 Prometheus 来 pull 之前就消失了。为此,这次 jobs 可以直接向 Prometheus server 端推送它们的 metrics。这种方式主要用于服务层面的 metrics,对于机器层面的 metrices,需要使用 node exporter。
Alertmanager
从 Prometheus server 端接收到 alerts 后,会进行去除重复数据,分组,并路由到对收的接受方式,发出报警。常见的接收方式有:电子邮件,pagerduty,OpsGenie, webhook 等。
PromQL
Promql介绍
通过PromQL我们可以非常方便地对监控样本数据进行统计分析,PromQL支持常见的运算操作符,同时PromQL中还提供了大量的内置函数可以实现对数据的高级处理。
告警监控也是依赖PromQL实现的。
特性
这里列举一些PromQL的特性:
- 可以直接使用指标名称进行查询
- PromQL支持用户根据时间序列的标签匹配模式来对时间序列进行过滤,目前主要支持两种匹配模式:
完全匹配和正则匹配 - PromQL支持基于
时间位移范围内的查询 - PromQL直接支持用户使用
标量(Scalar)和字符串(String) - PromQL能够支持基础的
数学运算(加减乘除求余求幂)及布尔运算、集合运算 - 内置
聚合操作符,这些操作符作用域瞬时向量。可以将瞬时表达式返回的样本数据进行聚合,形成一个新的时间序列。 - 还有其他内置函数,用于对时序数据进行丰富的处理
PS : 所有的PromQL表达式都必须至少包含一个指标名称(例如http_request_total),或者一个不会匹配到空字符串的标签过滤器
下面将会一一介绍以下PromQL的这些特性。
完全匹配模式
完全匹配模式由PromQL通过 = 和 != 支持
- 通过使用label=value可以选择那些标签满足表达式定义的时间序列;
- 反之使用label!=value则可以根据标签匹配排除时间序列;
# 举个例子
apiserver_request_total{instance="10.10.11.79:6443"}
使用正则表达式
PromQL还可以支持使用正则表达式作为匹配条件,多个表达式之间使用|进行分离
- 使用label=~regx表示选择那些标签符合正则表达式定义的时间序列;
- 反之使用label!~regx进行排除
# 举个例子
apiserver_request_total{instance!="10.10.11.79:6443", verb=~"CONNECT|WATCH"}
范围查询和时间位移
- 使用区间向量表达式,使用时间范围选择器“[ ]”筛选时间区间,使用关键 字offset进行时间位移操作(改变查询的时间基准)
- 查询支持的时间单位有:s/秒,m/分钟,h/小时,d/天,w/周,y/年
# 举个例子
apiserver_request_total{}[5m] offset 2d
聚合操作
Promql内置聚合操作符,这些操作符作用域瞬时向量。可以将瞬时表达式返回的样本数据进行聚合,形成一个新的时间序列
基本的聚合函数
| 名称 | 功能 |
|---|---|
| sum | 求和 |
| min | 最小值 |
| max | 最大值 |
| avg | 平均值 |
| stddev | 标准差 |
| stdvar | 标准差异 |
| count | 计数 |
| count_values | 对value计数 |
| bottomk | 后n条时序 |
| topk | 前n条时序 |
| count | 计数 |
| quantile | 分布统计 |
| itrae | 计算增长率 |
| … | … |
其他就不一一列举了,可前往官网查看
数学运算,布尔运算,集合运算
PromQL还支持丰富的操作符,用户可以使用这些操作符对进一步的对事件序列进行二次加工。这些操作符包括:数学运算符,逻辑运算符,布尔运算符等等。
| 名称 | 功能 |
|---|---|
| + | 加法 |
| - | 减法 |
| * | 乘法 |
| % | 除法 |
| ^ | 幂运算 |
| == | 等于 |
| != | 不等于 |
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
| and | 加法 |
| or | 减法 |
| less | 乘法 |
可视化
Prometheus Graph界面介绍
Prometheus基础界面如下所示

菜单
Alert:预警相关的信息,当监控指标满足一定规则时,会产生预警信息Graph:监控指标查询界面,可输入表达式查询监控指标,查询结果可以用简单的图表进行展示Status:记录Prometheus运行状态,配置,集成的采集节点等信息Help:Prometheus官方文档链接
Status 子菜单
command-line flags:用来配置一些系统参数,比如数据存储路径,磁盘、内存的使用上限等;Configuration:配置与采集节点相关的有所配置,以及要加载的规则文件Rules:配置的规则展示Targets:配置Exporter节点的展示Service Discovery:用于发现服务Help:Prometheus官方文档链接
使用Grafana作为Prometheus仪表盘
Grafana 是一款数据可视化看板,可指定多个数据源执行查询,将枯燥的数据转化为多维度的面板。
Grafana的界面长这样(如何部署请看上篇):

我们可以使用现成的Dashboard,也可以手动导入Metric配置自己的图表
我这里直接导入一个现成的图表看看效果:

狂拽酷炫掉渣天的感觉
DashBoard的配置也需要花费较长时间去描述,这里就不细讲了。
告警(Alertmanager)
告警能力在Prometheus的架构中被划分成两个独立的部分。通过在Prometheus中定义AlertRule(告警规则),Prometheus会周期性的对告警规则进行计算,如果满足告警触发条件就会向Alertmanager发送告警信息。
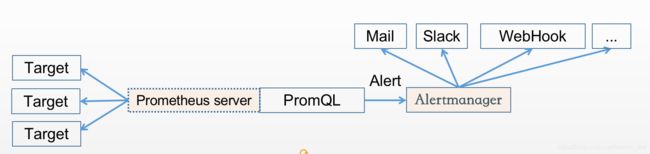
Alertmanager作为一个独立的组件,负责接收并处理来自Prometheus Server(也可以是其它的客户端程序)的告警信息。Alertmanager可以对这些告警信息进行进一步的处理,比如:
- 当接收到大量重复告警时能够消除重复的告警信息(可以更加精准的定位问题,并且避免你的邮箱被告警邮件爆破(¬_¬))
- 对告警信息进行分组并且路由到正确的通知方
- 当不希望某种告警触发时可以通过配置对告警进行静默处理(不会发送告警通知)
一条典型的基于node_exporter的告警规则
groups:
- name: hostStatsAlert
rules:
- alert: InstanceDown # 告警规则的名称
expr: up == 0 # 基于PromQL表达式告警触发条件,用于计算是否有时间序列满足该条件
for: 1m # 评估等待时间,可选参数。用于表示只有当触发条件持续一段时间后才发送告警。在等待期间新产生告警的状态为pending。
labels: # 自定义标签,允许用户指定要附加到告警上的一组附加标签。
severity: page
annotations: # 用于指定一组附加信息,比如用于描述告警详细信息的文字等,annotations的内容在告警产生时会一同作为参数发送到Alertmanager。
summary: "Instance {{$labels.instance}} down"
description: "{{$labels.instance}} of job {{$labels.job}} has been down for more than 5 minutes."
这条配置的效果就是,当node exporter挂掉时,Alertmanager会发送预警信息
如何部署请看上篇 :)
告警邮件长这样

Prometheus的基本介绍和使用就到此结束了,如果有什么不明白的话,可以留言或者参考其他文档
参考文档
- Prometheus入门
- Prometheus实践(IBM Developer)
- Prometheus-book
- Prometheus getting started
- 剖析Prometheus的内部存储机制
- 《Designing Data-Intensive Applications》
今天发什么图好呢,来个弥豆子治愈一下( ̄~ ̄)