Scrapy 下载器 中间件(Downloader Middleware)
Scrapy 下载器中间件官方文档:https://scrapy-chs.readthedocs.io/zh_CN/1.0/topics/downloader-middleware.html
官方 英文 文档:http://doc.scrapy.org/en/latest/topics/downloader-middleware.html#topics-downloader-middleware
Scrapy 扩展中间件: 针对特定响应状态码,使用代理重新请求:https://www.cnblogs.com/my8100/p/scrapy_middleware_autoproxy.html
https://www.baidu.com/s?wd=中间件状态码不等于200重新请求
下载器中间件(Downloader Middleware)
下载器中间件是介于Scrapy的request/response处理的钩子框架。 是用于全局修改Scrapy request和response的一个轻量、底层的系统。
用容易理解的话表述就是:更换代理IP,更换Cookies,更换User-Agent,自动重试 等。
1. 如果完全没有中间件,爬虫的流程如下图所示。
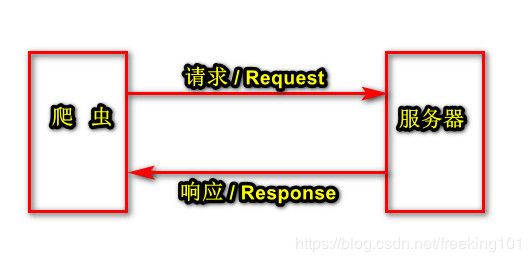
2. 使用了中间件以后,爬虫的流程如下图所示。
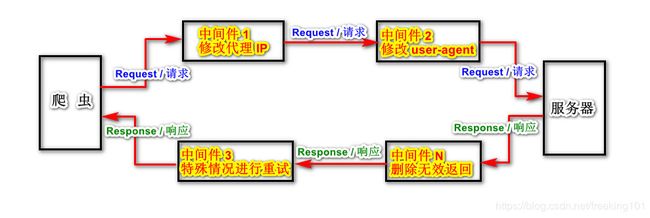
激活下载器中间件
要激活下载器中间件组件,将其加入到 DOWNLOADER_MIDDLEWARES 设置中。 该设置是一个字典(dict),键为中间件类的路径,值为其中间件的顺序(order)。
这里是一个例子:
DOWNLOADER_MIDDLEWARES = {
'myproject.middlewares.CustomDownloaderMiddleware': 543,
}
DOWNLOADER_MIDDLEWARES 设置会与 Scrapy 定义的 DOWNLOADER_MIDDLEWARES_BASE 设置合并(但不是覆盖), 而后根据顺序(order)进行排序,最后得到启用中间件的有序列表: 第一个中间件是最靠近引擎的,最后一个中间件是最靠近下载器的。
关于如何分配中间件的顺序请查看 DOWNLOADER_MIDDLEWARES_BASE 设置,而后根据您想要放置中间件的位置选择一个值。 由于每个中间件执行不同的动作,您的中间件可能会依赖于之前(或者之后)执行的中间件,因此顺序是很重要的。
如果您想禁止内置的(在 DOWNLOADER_MIDDLEWARES_BASE 中设置并默认启用的)中间件, 您必须在项目的 DOWNLOADER_MIDDLEWARES 设置中定义该中间件,并将其值赋为 None 。 例如,如果您想要关闭user-agent中间件:
DOWNLOADER_MIDDLEWARES = {
'myproject.middlewares.CustomDownloaderMiddleware': 543,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
}
最后,请注意,有些中间件需要通过特定的设置来启用。更多内容请查看相关中间件文档。
编写您自己的下载器中间件
编写下载器中间件十分简单。每个中间件组件是一个定义了以下一个或多个方法的Python类:
class scrapy.downloadermiddlewares.DownloaderMiddleware
- process_request(request, spider):
当每个request通过下载中间件时,该方法被调用。
process_request()必须返回其中之一: 返回None、返回一个Response对象、返回一个Request对象或raiseIgnoreRequest。如果其返回
None,Scrapy将继续处理该request,执行其他的中间件的相应方法,直到合适的下载器处理函数(download handler)被调用, 该request被执行(其response被下载)。如果其返回
Response对象,Scrapy将不会调用 任何 其他的process_request()或process_exception()方法,或相应地下载函数; 其将返回该response。 已安装的中间件的process_response()方法则会在每个response返回时被调用。如果其返回
Request对象,Scrapy则停止调用 process_request方法并重新调度返回的request。当新返回的request被执行后, 相应地中间件链将会根据下载的response被调用。如果其raise一个
IgnoreRequest异常,则安装的下载中间件的process_exception()方法会被调用。如果没有任何一个方法处理该异常, 则request的errback(Request.errback)方法会被调用。如果没有代码处理抛出的异常, 则该异常被忽略且不记录(不同于其他异常那样)。参数: - request (
Request对象) – 处理的request - spider (
Spider对象) – 该request对应的spider
- request (
- process_response(request, response, spider):
process_request()必须返回以下之一: 返回一个Response对象、 返回一个Request对象或raise一个IgnoreRequest异常。如果其返回一个
Response(可以与传入的response相同,也可以是全新的对象), 该response会被在链中的其他中间件的process_response()方法处理。如果其返回一个
Request对象,则中间件链停止, 返回的request会被重新调度下载。处理类似于process_request()返回request所做的那样。如果其抛出一个
IgnoreRequest异常,则调用request的errback(Request.errback)。 如果没有代码处理抛出的异常,则该异常被忽略且不记录(不同于其他异常那样)。参数: - request (
Request对象) – response所对应的request - response (
Response对象) – 被处理的response - spider (
Spider对象) – response所对应的spider
- request (
- process_exception(request, exception, spider):
当下载处理器(download handler)或
process_request()(下载中间件)抛出异常(包括IgnoreRequest异常)时, Scrapy调用process_exception()。process_exception()应该返回以下之一: 返回None、 一个Response对象、或者一个Request对象。如果其返回
None,Scrapy将会继续处理该异常,接着调用已安装的其他中间件的process_exception()方法,直到所有中间件都被调用完毕,则调用默认的异常处理。如果其返回一个
Response对象,则已安装的中间件链的process_response()方法被调用。Scrapy将不会调用任何其他中间件的process_exception()方法。如果其返回一个
Request对象, 则返回的request将会被重新调用下载。这将停止中间件的process_exception()方法执行,就如返回一个response的那样。参数: - request (是
Request对象) – 产生异常的request - exception (
Exception对象) – 抛出的异常 - spider (
Spider对象) – request对应的spider
- request (是
- from_crawler(cls, crawler):
If present, this classmethod is called to create a middleware instance from a
Crawler. It must return a new instance of the middleware. Crawler object provides access to all Scrapy core components like settings and signals; it is a way for middleware to access them and hook its functionality into Scrapy.Parameters: crawler ( Crawlerobject) – crawler that uses this middleware
scrapy 中的 from_crawler:https://www.jianshu.com/p/e9ec5d7b6204
示例:代理中间件
在爬虫开发中,更换代理IP是非常常见的情况,有时候每一次访问都需要随机选择一个代理IP来进行。
中间件本身是一个Python的类,只要爬虫每次访问网站之前都先“经过”这个类,它就能给请求换新的代理IP,这样就能实现动态改变代理。
在创建一个Scrapy工程以后,工程文件夹下会有一个 middlewares.py 文件,打开以后其内容如下图所示。
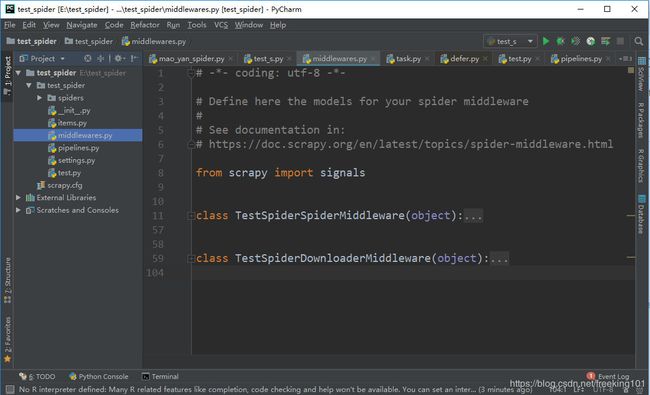
Scrapy 自动生成的这个文件名称为 middlewares.py,名字后面的 s 表示复数,说明这个文件里面可以放很多个中间件。可以看到有一个 SpiderMiddleware (爬虫中间件)中间件 和 DownloaderMiddleware (下载中间件)中间件
在middlewares.py中添加下面一段代码(可以在 下载中间件这个类 里面写,也可以把 爬虫中间件 和 下载中间件 这两个类删了,自己写个 下载中间件的类。推荐 自己单写一个类 作为 下载中间件):
# -*- coding: utf-8 -*-
# Define here the models for your spider middleware
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
import random
from scrapy.conf import settings
from scrapy.utils.project import get_project_settings
class ProxyMiddleware(object):
def process_request(self, request, spider):
proxy_1 = random.choice(settings['PROXIES']) # 方法 1
proxy_2 = random.choice(get_project_settings()['PROXIES']) # 方法 2
request.meta['proxy'] = proxy_1打开 setting.py 添加 代理 ,并激活 这个代理中间件:
需要注意的是,代理IP是有类型的,需要先看清楚是 HTTP型 的代理IP还是 HTTPS型 的代理IP。
DOWNLOADER_MIDDLEWARES = {
'test_spider.middlewares.ProxyMiddleware': 543,
# 'test_spider.middlewares.Custom_B_DownloaderMiddleware': 643,
# 'test_spider.middlewares.Custom_B_DownloaderMiddleware': None,
}
PROXIES = [
'https://114.217.243.25:8118',
'https://125.37.175.233:8118',
'http://1.85.116.218:8118'
]DOWNLOADER_MIDDLEWARES 其实就是一个字典,字典的Key就是用点分隔的中间件路径,后面的数字表示这种中间件的顺序。由于中间件是按顺序运行的,因此如果遇到后一个中间件依赖前一个中间件的情况,中间件的顺序就至关重要。
如何确定后面的数字应该怎么写呢?最简单的办法就是从543开始,逐渐加一,这样一般不会出现什么大问题。如果想把中间件做得更专业一点,那就需要知道Scrapy自带中间件的顺序,如图下图所示 ( DOWNLOADER_MIDDLEWARES )。

数字越小的中间件越先执行(数字越小,越靠近引擎,数字越大越靠近下载器,所以数字越小的,processrequest()优先处理;数字越大的,process_response()优先处理;若需要关闭某个中间件直接设为None即可),例如Scrapy自带的第1个中间件RobotsTxtMiddleware,它的作用是首先查看settings.py中ROBOTSTXT_OBEY 这一项的配置是True还是False。如果是True,表示要遵守Robots.txt协议,它就会检查将要访问的网址能不能被运行访问,如果不被允许访问,那么直接就取消这一次请求,接下来的和这次请求有关的各种操作全部都不需要继续了。
开发者自定义的中间件,会被按顺序插入到Scrapy自带的中间件中。爬虫会按照从100~900的顺序依次运行所有的中间件。直到所有中间件全部运行完成,或者遇到某一个中间件而取消了这次请求。
Scrapy 其实自带了 UA 中间件(UserAgentMiddleware)、代理中间件(HttpProxyMiddleware)和重试中间件(RetryMiddleware)。所以,从“原则上”说,要自己开发这3个中间件,需要先禁用Scrapy里面自带的这3个中间件。要禁用Scrapy的中间件,需要在settings.py里面将这个中间件的顺序设为None:
DOWNLOADER_MIDDLEWARES = {
'test_spider.middlewares.ProxyMiddleware': 543,
'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware': None,
'scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware': None
}
PROXIES = [
'https://114.217.243.25:8118',
'https://125.37.175.233:8118',
'http://1.85.116.218:8118'
]为什么说“原则上”应该禁用呢?先查看Scrapy自带的代理中间件的源代码,如下图所示:

从上图可以看出,如果Scrapy发现这个请求已经被设置了代理,那么这个中间件就会什么也不做,直接返回。因此虽然Scrapy自带的这个代理中间件顺序为750,比开发者自定义的代理中间件的顺序543大,但是它并不会覆盖开发者自己定义的代理信息,所以即使不禁用系统自带的这个代理中间件也没有关系。
代理中间件的可用代理列表不一定非要写在settings.py里面,也可以将它们写到数据库或者Redis中。一个可行的自动更换代理的爬虫系统,应该有如下的3个功能。
- 1. 有一个小爬虫ProxySpider去各大代理网站爬取免费代理并验证,将可以使用的代理IP保存到数据库中。
- 2. 在ProxyMiddlerware的process_request中,每次从数据库里面随机选择一条代理IP地址使用。
- 3. 周期性验证数据库中的无效代理,及时将其删除。由于免费代理极其容易失效,因此如果有一定开发预算的话,建议购买专业代理机构的代理服务,高速而稳定。
scrapy 中对接 selenium
from scrapy.http import HtmlResponse
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from gp.configs import *
class ChromeDownloaderMiddleware(object):
def __init__(self):
options = webdriver.ChromeOptions()
options.add_argument('--headless') # 设置无界面
if CHROME_PATH:
options.binary_location = CHROME_PATH
if CHROME_DRIVER_PATH:
self.driver = webdriver.Chrome(chrome_options=options, executable_path=CHROME_DRIVER_PATH) # 初始化Chrome驱动
else:
self.driver = webdriver.Chrome(chrome_options=options) # 初始化Chrome驱动
def __del__(self):
self.driver.close()
def process_request(self, request, spider):
try:
print('Chrome driver begin...')
self.driver.get(request.url) # 获取网页链接内容
return HtmlResponse(url=request.url, body=self.driver.page_source, request=request, encoding='utf-8',
status=200) # 返回HTML数据
except TimeoutException:
return HtmlResponse(url=request.url, request=request, encoding='utf-8', status=500)
finally:
print('Chrome driver end...')
示例:UA (user-agent) 中间件
Scrapy学习篇(十一)之设置随机User-Agent:https://www.cnblogs.com/cnkai/p/7401343.html
开发UA中间件和开发代理中间件几乎一样,它也是从 settings.py 配置好的 UA 列表中随机选择一项,加入到请求头中。代码如下:
class UAMiddleware(object):
def process_request(self, request, spider):
ua = random.choice(settings['USER_AGENT_LIST'])
request.headers['User-Agent'] = ua比IP更好的是,UA不会存在失效的问题,所以只要收集几十个UA,就可以一直使用。常见的UA如下:
USER_AGENT_LIST = [
"Mozilla/5.0 (Linux; U; Android 2.3.6; en-us; Nexus S Build/GRK39F) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Avant Browser/1.2.789rel1 (http://www.avantbrowser.com)",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/532.5 (KHTML, like Gecko) Chrome/4.0.249.0 Safari/532.5",
"Mozilla/5.0 (Windows; U; Windows NT 5.2; en-US) AppleWebKit/532.9 (KHTML, like Gecko) Chrome/5.0.310.0 Safari/532.9",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US) AppleWebKit/534.7 (KHTML, like Gecko) Chrome/7.0.514.0 Safari/534.7",
"Mozilla/5.0 (Windows; U; Windows NT 6.0; en-US) AppleWebKit/534.14 (KHTML, like Gecko) Chrome/9.0.601.0 Safari/534.14",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.14 (KHTML, like Gecko) Chrome/10.0.601.0 Safari/534.14",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.20 (KHTML, like Gecko) Chrome/11.0.672.2 Safari/534.20",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.27 (KHTML, like Gecko) Chrome/12.0.712.0 Safari/534.27",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/13.0.782.24 Safari/535.1",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/535.2 (KHTML, like Gecko) Chrome/15.0.874.120 Safari/535.2",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.7 (KHTML, like Gecko) Chrome/16.0.912.36 Safari/535.7",
"Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.9.0.10) Gecko/2009042316 Firefox/3.0.10",
"Mozilla/5.0 (Windows; U; Windows NT 6.0; en-GB; rv:1.9.0.11) Gecko/2009060215 Firefox/3.0.11 (.NET CLR 3.5.30729)",
"Mozilla/5.0 (Windows; U; Windows NT 6.0; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6 GTB5",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; tr; rv:1.9.2.8) Gecko/20100722 Firefox/3.6.8 ( .NET CLR 3.5.30729; .NET4.0E)",
"Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Mozilla/5.0 (Windows NT 5.1; rv:5.0) Gecko/20100101 Firefox/5.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0a2) Gecko/20110622 Firefox/6.0a2",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:7.0.1) Gecko/20100101 Firefox/7.0.1",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:2.0b4pre) Gecko/20100815 Minefield/4.0b4pre",
"Mozilla/4.0 (compatible; MSIE 5.5; Windows NT 5.0 )",
"Mozilla/4.0 (compatible; MSIE 5.5; Windows 98; Win 9x 4.90)",
"Mozilla/5.0 (Windows; U; Windows XP) Gecko MultiZilla/1.6.1.0a",
"Mozilla/2.02E (Win95; U)",
"Mozilla/3.01Gold (Win95; I)",
"Mozilla/4.8 [en] (Windows NT 5.1; U)",
"Mozilla/5.0 (Windows; U; Win98; en-US; rv:1.4) Gecko Netscape/7.1 (ax)",
"HTC_Dream Mozilla/5.0 (Linux; U; Android 1.5; en-ca; Build/CUPCAKE) AppleWebKit/528.5 (KHTML, like Gecko) Version/3.1.2 Mobile Safari/525.20.1",
"Mozilla/5.0 (hp-tablet; Linux; hpwOS/3.0.2; U; de-DE) AppleWebKit/534.6 (KHTML, like Gecko) wOSBrowser/234.40.1 Safari/534.6 TouchPad/1.0",
"Mozilla/5.0 (Linux; U; Android 1.5; en-us; sdk Build/CUPCAKE) AppleWebkit/528.5 (KHTML, like Gecko) Version/3.1.2 Mobile Safari/525.20.1",
"Mozilla/5.0 (Linux; U; Android 2.1; en-us; Nexus One Build/ERD62) AppleWebKit/530.17 (KHTML, like Gecko) Version/4.0 Mobile Safari/530.17",
"Mozilla/5.0 (Linux; U; Android 2.2; en-us; Nexus One Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Mozilla/5.0 (Linux; U; Android 1.5; en-us; htc_bahamas Build/CRB17) AppleWebKit/528.5 (KHTML, like Gecko) Version/3.1.2 Mobile Safari/525.20.1",
"Mozilla/5.0 (Linux; U; Android 2.1-update1; de-de; HTC Desire 1.19.161.5 Build/ERE27) AppleWebKit/530.17 (KHTML, like Gecko) Version/4.0 Mobile Safari/530.17",
"Mozilla/5.0 (Linux; U; Android 2.2; en-us; Sprint APA9292KT Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Mozilla/5.0 (Linux; U; Android 1.5; de-ch; HTC Hero Build/CUPCAKE) AppleWebKit/528.5 (KHTML, like Gecko) Version/3.1.2 Mobile Safari/525.20.1",
"Mozilla/5.0 (Linux; U; Android 2.2; en-us; ADR6300 Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Mozilla/5.0 (Linux; U; Android 2.1; en-us; HTC Legend Build/cupcake) AppleWebKit/530.17 (KHTML, like Gecko) Version/4.0 Mobile Safari/530.17",
"Mozilla/5.0 (Linux; U; Android 1.5; de-de; HTC Magic Build/PLAT-RC33) AppleWebKit/528.5 (KHTML, like Gecko) Version/3.1.2 Mobile Safari/525.20.1 FirePHP/0.3",
"Mozilla/5.0 (Linux; U; Android 1.6; en-us; HTC_TATTOO_A3288 Build/DRC79) AppleWebKit/528.5 (KHTML, like Gecko) Version/3.1.2 Mobile Safari/525.20.1",
"Mozilla/5.0 (Linux; U; Android 1.0; en-us; dream) AppleWebKit/525.10 (KHTML, like Gecko) Version/3.0.4 Mobile Safari/523.12.2",
"Mozilla/5.0 (Linux; U; Android 1.5; en-us; T-Mobile G1 Build/CRB43) AppleWebKit/528.5 (KHTML, like Gecko) Version/3.1.2 Mobile Safari 525.20.1",
"Mozilla/5.0 (Linux; U; Android 1.5; en-gb; T-Mobile_G2_Touch Build/CUPCAKE) AppleWebKit/528.5 (KHTML, like Gecko) Version/3.1.2 Mobile Safari/525.20.1",
"Mozilla/5.0 (Linux; U; Android 2.0; en-us; Droid Build/ESD20) AppleWebKit/530.17 (KHTML, like Gecko) Version/4.0 Mobile Safari/530.17",
"Mozilla/5.0 (Linux; U; Android 2.2; en-us; Droid Build/FRG22D) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Mozilla/5.0 (Linux; U; Android 2.0; en-us; Milestone Build/ SHOLS_U2_01.03.1) AppleWebKit/530.17 (KHTML, like Gecko) Version/4.0 Mobile Safari/530.17",
"Mozilla/5.0 (Linux; U; Android 2.0.1; de-de; Milestone Build/SHOLS_U2_01.14.0) AppleWebKit/530.17 (KHTML, like Gecko) Version/4.0 Mobile Safari/530.17",
"Mozilla/5.0 (Linux; U; Android 3.0; en-us; Xoom Build/HRI39) AppleWebKit/525.10 (KHTML, like Gecko) Version/3.0.4 Mobile Safari/523.12.2",
"Mozilla/5.0 (Linux; U; Android 0.5; en-us) AppleWebKit/522 (KHTML, like Gecko) Safari/419.3",
"Mozilla/5.0 (Linux; U; Android 1.1; en-gb; dream) AppleWebKit/525.10 (KHTML, like Gecko) Version/3.0.4 Mobile Safari/523.12.2",
"Mozilla/5.0 (Linux; U; Android 2.0; en-us; Droid Build/ESD20) AppleWebKit/530.17 (KHTML, like Gecko) Version/4.0 Mobile Safari/530.17",
"Mozilla/5.0 (Linux; U; Android 2.1; en-us; Nexus One Build/ERD62) AppleWebKit/530.17 (KHTML, like Gecko) Version/4.0 Mobile Safari/530.17",
"Mozilla/5.0 (Linux; U; Android 2.2; en-us; Sprint APA9292KT Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Mozilla/5.0 (Linux; U; Android 2.2; en-us; ADR6300 Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Mozilla/5.0 (Linux; U; Android 2.2; en-ca; GT-P1000M Build/FROYO) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Mozilla/5.0 (Linux; U; Android 3.0.1; fr-fr; A500 Build/HRI66) AppleWebKit/534.13 (KHTML, like Gecko) Version/4.0 Safari/534.13",
"Mozilla/5.0 (Linux; U; Android 3.0; en-us; Xoom Build/HRI39) AppleWebKit/525.10 (KHTML, like Gecko) Version/3.0.4 Mobile Safari/523.12.2",
"Mozilla/5.0 (Linux; U; Android 1.6; es-es; SonyEricssonX10i Build/R1FA016) AppleWebKit/528.5 (KHTML, like Gecko) Version/3.1.2 Mobile Safari/525.20.1",
"Mozilla/5.0 (Linux; U; Android 1.6; en-us; SonyEricssonX10i Build/R1AA056) AppleWebKit/528.5 (KHTML, like Gecko) Version/3.1.2 Mobile Safari/525.20.1",
]test_spider.py (使用 的是 scrapy-redis 的 RedisSpider,需要从 redis 读取 url):
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# @Author :
# @File : mao_yan_spider.py
# @Software : PyCharm
# @description : XXX
from scrapy import Spider
from scrapy_redis.spiders import RedisSpider
class TestSpider(RedisSpider):
name = 'test'
redis_key = 'start_urls:{0}'.format(name)
# start_urls = ['http://exercise.kingname.info/exercise_middleware_ua']
def parse(self, response):
print('response text : {0}'.format(response.text))
pass
setting.py 配置 ():
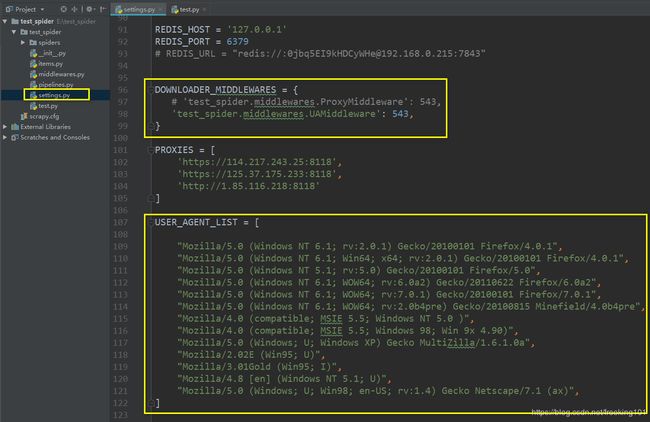
test.py:
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# @Author :
# @File : test_s.py
# @Software : PyCharm
# @description : XXX
import redis
from scrapy import cmdline
def add_test_task():
r = redis.Redis(host='127.0.0.1', port=6379)
for i in range(10):
url = 'http://exercise.kingname.info/exercise_middleware_ua'
r.lpush('start_urls:test', url)
if __name__ == "__main__":
add_test_task()
cmdline.execute("scrapy crawl test".split())
pass
运行 test.py 截图:
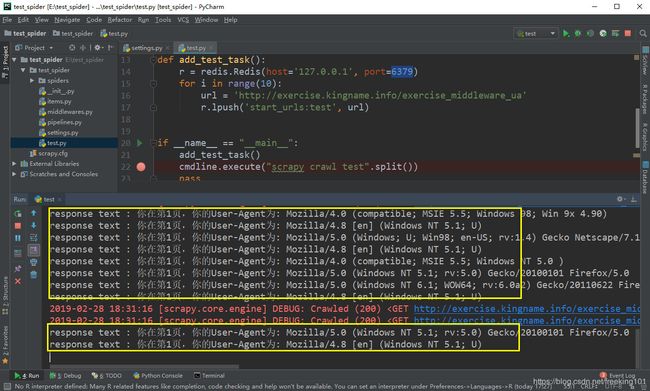
可以看到 请求的 user-agent 是变化的。
from faker import Faker
class UserAgent_Middleware():
def process_request(self, request, spider):
f = Faker()
agent = f.firefox()
request.headers['User-Agent'] = agent
Cookies 中间件
对于需要登录的网站,可以使用Cookies来保持登录状态。那么如果单独写一个小程序,用Selenium持续不断地用不同的账号登录网站,就可以得到很多不同的Cookies。由于Cookies本质上就是一段文本,所以可以把这段文本放在Redis里面。这样一来,当Scrapy爬虫请求网页时,可以从Redis中读取Cookies并给爬虫换上。这样爬虫就可以一直保持登录状态。
以下面这个练习页面为例:http://exercise.kingname.info/exercise_login_success
如果直接用Scrapy访问,得到的是登录界面的源代码,如下图所示。
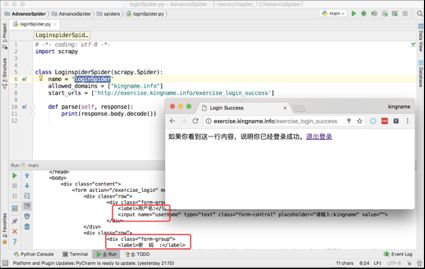
现在,使用中间件,可以实现完全不改动这个loginSpider.py里面的代码,就打印出登录以后才显示的内容。
首先开发一个小程序,通过Selenium登录这个页面,并将网站返回的Headers保存到Redis中。这个小程序的代码如下图所示。
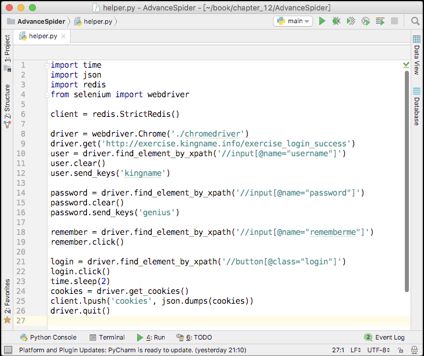
这段代码的作用是使用Selenium和ChromeDriver填写用户名和密码,实现登录练习页面,然后将登录以后的Cookies转换为JSON格式的字符串并保存到Redis中。
接下来,再写一个中间件,用来从Redis中读取Cookies,并把这个Cookies给Scrapy使用:
class LoginMiddleware(object):
def __init__(self):
self.client = redis.StrictRedis()
def process_request(self, request, spider):
if spider.name == 'loginSpider':
cookies = json.loads(self.client.lpop('cookies').decode())
request.cookies = cookies设置了这个中间件以后,爬虫里面的代码不需要做任何修改就可以成功得到登录以后才能看到的HTML,如图12-12所示。
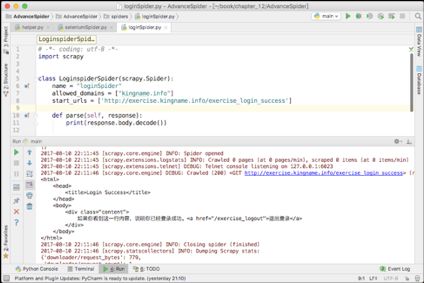
如果有某网站的100个账号,那么单独写一个程序,持续不断地用Selenium和ChromeDriver或者Selenium 和PhantomJS登录,获取Cookies,并将Cookies存放到Redis中。爬虫每次访问都从Redis中读取一个新的Cookies来进行爬取,就大大降低了被网站发现或者封锁的可能性。
这种方式不仅适用于登录,也适用于验证码的处理。
内置 下载中间件 参考手册
本页面介绍了Scrapy自带的所有下载中间件。关于如何使用及编写您自己的中间件,请参考 downloader middleware usage guide.
关于默认启用的中间件列表(及其顺序)请参考 DOWNLOADER_MIDDLEWARES_BASE 设置。
CookiesMiddleware
class scrapy.downloadermiddlewares.cookies.CookiesMiddleware
该中间件使得爬取需要cookie(例如使用session)的网站成为了可能。 其追踪了web server发送的cookie,并在之后的request中发送回去, 就如浏览器所做的那样。
以下设置可以用来配置cookie中间件:
COOKIES_ENABLEDCOOKIES_DEBUG
每个 spider 多 cookie session
0.15 新版功能.
Scrapy 通过使用 cookiejar 作为 Request meta 的 key 来支持单 spider 追踪多 cookie session。 默认情况下其使用一个 cookie jar(session),不过您可以传递一个标示符来使用多个。
例如 ( yield 的 每个 Request 都 有一个 meta={'cookiejar': i} ,cookiejar 这个字段的 值只是一个标识,只要不为 None 就行,通常 设置为一个整数 。例如 1,或者 True):
for i, url in enumerate(urls):
yield scrapy.Request(
url="http://www.example.com",
meta={'cookiejar': i},
callback=self.parse_page
)需要注意的是 cookiejar meta key不是”黏性的(sticky)”。 您需要在之后的 每个 request 请求中接着传递。例如:
def parse_page(self, response):
# do some processing
return scrapy.Request("http://www.example.com/otherpage",
meta={'cookiejar': response.meta['cookiejar']},
callback=self.parse_other_page)
COOKIES_ENABLED
默认: True
是否启用 cookies middleware。如果关闭,cookies 将不会发送给 web server。
COOKIES_DEBUG
默认: False
如果启用,Scrapy将记录所有在request(Cookie 请求头)发送的cookies及response接收到的cookies(Set-Cookie 接收头)。
下边是启用 COOKIES_DEBUG 的记录的样例:
2011-04-06 14:35:10-0300 [scrapy] INFO: Spider opened
2011-04-06 14:35:10-0300 [scrapy] DEBUG: Sending cookies to:
Cookie: clientlanguage_nl=en_EN
2011-04-06 14:35:14-0300 [scrapy] DEBUG: Received cookies from: <200 http://www.diningcity.com/netherlands/index.html>
Set-Cookie: JSESSIONID=B~FA4DC0C496C8762AE4F1A620EAB34F38; Path=/
Set-Cookie: ip_isocode=US
Set-Cookie: clientlanguage_nl=en_EN; Expires=Thu, 07-Apr-2011 21:21:34 GMT; Path=/
2011-04-06 14:49:50-0300 [scrapy] DEBUG: Crawled (200) (referer: None)
[...]
DefaultHeadersMiddleware
class scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware
该中间件设置 DEFAULT_REQUEST_HEADERS 指定的默认request header。
DownloadTimeoutMiddleware
class scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware
该中间件设置 DOWNLOAD_TIMEOUT 指定的request下载超时时间.
Note
You can also set download timeout per-request using download_timeout Request.meta key; this is supported even when DownloadTimeoutMiddleware is disabled.
HttpAuthMiddleware
class scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware
该中间件完成某些使用 Basic access authentication (或者叫HTTP认证)的spider生成的请求的认证过程。
在 spider 中启用 HTTP 认证,请设置 spider 的 http_user 及 http_pass 属性。
样例:
from scrapy.spiders import CrawlSpider
class SomeIntranetSiteSpider(CrawlSpider):
http_user = 'someuser'
http_pass = 'somepass'
name = 'intranet.example.com'
# .. rest of the spider code omitted ...
HttpCacheMiddleware
class scrapy.downloadermiddlewares.httpcache.HttpCacheMiddleware
该中间件为所有HTTP request及response提供了底层(low-level)缓存支持。 其由cache存储后端及cache策略组成。
Scrapy提供了两种HTTP缓存存储后端:
- Filesystem storage backend (默认值)
- DBM storage backend
您可以使用 HTTPCACHE_STORAGE 设定来修改HTTP缓存存储后端。 您也可以实现您自己的存储后端。
Scrapy提供了两种了缓存策略:
- RFC2616策略
- Dummy策略(默认值)
您可以使用 HTTPCACHE_POLICY 设定来修改HTTP缓存存储后端。 您也可以实现您自己的存储策略。
Dummy策略(默认值)
该策略不考虑任何HTTP Cache-Control指令。每个request及其对应的response都被缓存。 当相同的request发生时,其不发送任何数据,直接返回response。
Dummpy策略对于测试spider十分有用。其能使spider运行更快(不需要每次等待下载完成), 同时在没有网络连接时也能测试。其目的是为了能够回放spider的运行过程, 使之与之前的运行过程一模一样 。
使用这个策略请设置:
HTTPCACHE_POLICY为scrapy.extensions.httpcache.DummyPolicy
RFC2616策略
该策略提供了符合RFC2616的HTTP缓存,例如符合HTTP Cache-Control, 针对生产环境并且应用在持续性运行环境所设置。该策略能避免下载未修改的数据(来节省带宽,提高爬取速度)。
实现了:
-
当 no-store cache-control指令设置时不存储response/request。
-
当 no-cache cache-control指定设置时不从cache中提取response,即使response为最新。
-
根据 max-age cache-control指令中计算保存时间(freshness lifetime)。
-
根据 Expires 指令来计算保存时间(freshness lifetime)。
-
根据response包头的 Last-Modified 指令来计算保存时间(freshness lifetime)(Firefox使用的启发式算法)。
-
根据response包头的 Age 计算当前年龄(current age)
-
根据 Date 计算当前年龄(current age)
-
根据response包头的 Last-Modified 验证老旧的response。
-
根据response包头的 ETag 验证老旧的response。
-
为接收到的response设置缺失的 Date 字段。
-
支持request中cache-control指定的 max-stale
通过该字段,使得spider完整支持了RFC2616缓存策略,但避免了多次请求下情况下的重验证问题(revalidation on a request-by-request basis). 后者仍然需要HTTP标准进行确定.
例子:
在Request的包头中添加 Cache-Control: max-stale=600 表明接受未超过600秒的超时时间的response.
更多请参考: RFC2616, 14.9.3
目前仍然缺失:
- Pragma: no-cache 支持 http://www.w3.org/Protocols/rfc2616/rfc2616-sec14.html#sec14.9.1
- Vary 字段支持 http://www.w3.org/Protocols/rfc2616/rfc2616-sec13.html#sec13.6
- 当update或delete之后失效相应的response http://www.w3.org/Protocols/rfc2616/rfc2616-sec13.html#sec13.10
- ... 以及其他可能缺失的特性 ..
使用这个策略,设置:
HTTPCACHE_POLICY为scrapy.extensions.httpcache.RFC2616Policy
Filesystem storage backend (默认值)
文件系统存储后端可以用于HTTP缓存中间件。
使用该存储端,设置:
HTTPCACHE_STORAGE为scrapy.extensions.httpcache.FilesystemCacheStorage
每个request/response组存储在不同的目录中,包含下列文件:
request_body- the plain request bodyrequest_headers- the request headers (原始HTTP格式)response_body- the plain response bodyresponse_headers- the request headers (原始HTTP格式)meta- 以Pythonrepr()格式(grep-friendly格式)存储的该缓存资源的一些元数据。pickled_meta- 与meta相同的元数据,不过使用pickle来获得更高效的反序列化性能。
目录的名称与request的指纹(参考 scrapy.utils.request.fingerprint)有关,而二级目录是为了避免在同一文件夹下有太多文件 (这在很多文件系统中是十分低效的)。目录的例子:
/path/to/cache/dir/example.com/72/72811f648e718090f041317756c03adb0ada46c7
DBM storage backend
0.13 新版功能.
同时也有 DBM 存储后端可以用于HTTP缓存中间件。
默认情况下,其采用 anydbm 模块,不过您也可以通过 HTTPCACHE_DBM_MODULE 设置进行修改。
使用该存储端,设置:
HTTPCACHE_STORAGE为scrapy.extensions.httpcache.DbmCacheStorage
LevelDB storage backend
0.23 新版功能.
A LevelDB storage backend is also available for the HTTP cache middleware.
This backend is not recommended for development because only one process can access LevelDB databases at the same time, so you can’t run a crawl and open the scrapy shell in parallel for the same spider.
In order to use this storage backend:
- set
HTTPCACHE_STORAGEtoscrapy.extensions.httpcache.LeveldbCacheStorage - install LevelDB python bindings like
pip install leveldb
HTTPCache中间件设置
HttpCacheMiddleware 可以通过以下设置进行配置:
HTTPCACHE_ENABLED
0.11 新版功能.
默认: False
HTTP缓存是否开启。
在 0.11 版更改: 在0.11版本前,是使用 HTTPCACHE_DIR 来开启缓存。
HTTPCACHE_EXPIRATION_SECS
默认: 0
缓存的request的超时时间,单位秒。
超过这个时间的缓存request将会被重新下载。如果为0,则缓存的request将永远不会超时。
在 0.11 版更改: 在0.11版本前,0的意义是缓存的request永远超时。
HTTPCACHE_DIR
默认: 'httpcache'
存储(底层的)HTTP缓存的目录。如果为空,则HTTP缓存将会被关闭。 如果为相对目录,则相对于项目数据目录(project data dir)。更多内容请参考 默认的Scrapy项目结构 。
HTTPCACHE_IGNORE_HTTP_CODES
0.10 新版功能.
默认: []
不缓存设置中的HTTP返回值(code)的request。
HTTPCACHE_IGNORE_MISSING
默认: False
如果启用,在缓存中没找到的request将会被忽略,不下载。
HTTPCACHE_IGNORE_SCHEMES
0.10 新版功能.
默认: ['file']
不缓存这些URI标准(scheme)的response。
HTTPCACHE_STORAGE
默认: 'scrapy.extensions.httpcache.FilesystemCacheStorage'
实现缓存存储后端的类。
HTTPCACHE_DBM_MODULE
0.13 新版功能.
默认: 'anydbm'
在 DBM存储后端 的数据库模块。 该设定针对DBM后端。
HTTPCACHE_POLICY
0.18 新版功能.
默认: 'scrapy.extensions.httpcache.DummyPolicy'
实现缓存策略的类。
HTTPCACHE_GZIP
0.25 新版功能.
默认: False
如果启用,scrapy将会使用gzip压缩所有缓存的数据. 该设定只针对文件系统后端(Filesystem backend)有效。
HttpCompressionMiddleware
class scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware
该中间件提供了对压缩(gzip, deflate)数据的支持。
HttpCompressionMiddleware Settings
COMPRESSION_ENABLED
默认: True
Compression Middleware(压缩中间件)是否开启。
ChunkedTransferMiddleware
class scrapy.downloadermiddlewares.chunked.ChunkedTransferMiddleware
该中间件添加了对 chunked transfer encoding 的支持。
HttpProxyMiddleware
0.8 新版功能.
class scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware
该中间件提供了对request设置HTTP代理的支持。您可以通过在 Request 对象中设置 proxy 元数据来开启代理。
类似于Python标准库模块 urllib 及 urllib2 ,其使用了下列环境变量:
http_proxyhttps_proxyno_proxy
您也可以针对每个请求设置 proxy 元数据, 其形式类似于 http://some_proxy_server:port.
RedirectMiddleware
class scrapy.downloadermiddlewares.redirect.RedirectMiddleware
该中间件根据 response 的状态处理重定向的request。
通过该中间件的(被重定向的)request的url可以通过 Request.meta 的 redirect_urls 键找到。
RedirectMiddleware 可以通过下列设置进行配置(更多内容请参考设置文档):
REDIRECT_ENABLEDREDIRECT_MAX_TIMES
如果 Request.meta 包含 dont_redirect 键,则该 request 将会被此中间件忽略。
如果想要处理一些 重定向状态码 在你的 spider 中,你可以 spider 的属性 handle_httpstatus_list 列出。
例如,如果想要 重定向中间件 忽略 301 和 302 的 response(通过其他的状态码)你可以这样写:
class MySpider(CrawlSpider):
handle_httpstatus_list = [301, 302]Request.meta 的键 handle_httpstatus_list 能被用来指定 每个 request 的 response 的状态码应该被允许通过。
也可以设置 meta 的 key 为 handle_httpstatus_all 值为 True 来允许 一个 请求的所有 response 通过
RedirectMiddleware settings
REDIRECT_ENABLED
0.13 新版功能.
默认: True
是否启用Redirect中间件。
REDIRECT_MAX_TIMES
默认: 20
单个request被重定向的最大次数。
MetaRefreshMiddleware
class scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware
该中间件根据meta-refresh html标签处理request重定向。
MetaRefreshMiddleware 可以通过以下设定进行配置 (更多内容请参考设置文档)。
METAREFRESH_ENABLEDMETAREFRESH_MAXDELAY
该中间件遵循 RedirectMiddleware 描述的 REDIRECT_MAX_TIMES 设定,dont_redirect 及 redirect_urls meta key。
MetaRefreshMiddleware settings
METAREFRESH_ENABLED
0.17 新版功能.
默认: True
Meta Refresh中间件是否启用。
REDIRECT_MAX_METAREFRESH_DELAY
默认: 100
跟进重定向的最大 meta-refresh 延迟(单位:秒)。
RetryMiddleware
class scrapy.downloadermiddlewares.retry.RetryMiddleware
该中间件将重试可能由于临时的问题,例如连接超时或者HTTP 500错误导致失败的页面。
爬取进程会收集失败的页面并在最后,spider爬取完所有正常(不失败)的页面后重新调度。 一旦没有更多需要重试的失败页面,该中间件将会发送一个信号(retry_complete), 其他插件可以监听该信号。
RetryMiddleware 可以通过下列设定进行配置 (更多内容请参考设置文档):
RETRY_ENABLEDRETRY_TIMESRETRY_HTTP_CODES
关于HTTP错误的考虑:
如果根据HTTP协议,您可能想要在设定 RETRY_HTTP_CODES 中移除400错误。 该错误被默认包括是由于这个代码经常被用来指示服务器过载(overload)了。而在这种情况下,我们想进行重试。
如果 Request.meta 包含 dont_retry 键, 该request将会被本中间件忽略。
RetryMiddleware Settings
RETRY_ENABLED
0.13 新版功能.
默认: True
Retry Middleware是否启用。
RETRY_TIMES
默认: 2
包括第一次下载,最多的重试次数
RETRY_HTTP_CODES
默认: [500, 502, 503, 504, 400, 408]
重试的response 返回值(code)。其他错误(DNS查找问题、连接失败及其他)则一定会进行重试。
RobotsTxtMiddleware
class scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware
该中间件过滤所有robots.txt eclusion standard中禁止的request。
确认该中间件及 ROBOTSTXT_OBEY 设置被启用以确保Scrapy尊重robots.txt。
警告
记住, 如果您在一个网站中使用了多个并发请求, Scrapy仍然可能下载一些被禁止的页面。这是由于这些页面是在robots.txt被下载前被请求的。 这是当前robots.txt中间件已知的限制,并将在未来进行修复。
DownloaderStats
class scrapy.downloadermiddlewares.stats.DownloaderStats
保存所有通过的request、response及exception的中间件。
您必须启用 DOWNLOADER_STATS 来启用该中间件。
UserAgentMiddleware
class scrapy.downloadermiddlewares.useragent.UserAgentMiddleware
用于覆盖spider的默认user agent的中间件。
要使得spider能覆盖默认的user agent,其 user_agent 属性必须被设置。
AjaxCrawlMiddleware
class scrapy.downloadermiddlewares.ajaxcrawl.AjaxCrawlMiddleware
根据meta-fragment html标签查找 ‘AJAX可爬取’ 页面的中间件。查看 https://developers.google.com/webmasters/ajax-crawling/docs/getting-started 来获得更多内容。
注解
即使没有启用该中间件,Scrapy仍能查找类似于 'http://example.com/!#foo=bar' 这样的’AJAX可爬取’页面。 AjaxCrawlMiddleware是针对不具有 '!#' 的URL,通常发生在’index’或者’main’页面中。
AjaxCrawlMiddleware 设置
AJAXCRAWL_ENABLED
0.21 新版功能.
默认: False
AjaxCrawlMiddleware是否启用。您可能需要针对 通用爬虫 启用该中间件。
HttpProxyMiddleware settings
HTTPPROXY_ENABLED
Default: True
Whether or not to enable the HttpProxyMiddleware.
HTTPPROXY_AUTH_ENCODING
Default: "latin-1"
The default encoding for proxy authentication on HttpProxyMiddleware.