决策树、GBDT与Xgboost详解
写在前面
GBDT是一个系列算法,具有很好的性能,可以用于回归、分类、排序的机器学习任务,也是机器学习面试时常考的一个知识点,在这写下个人的一些理解,也当做个笔记。
GBDT分为两部分,GB: Gradient Boosting和DT: Decision tree。
GBDT算法是属于Boosting算法族的一部分,可将弱学习器提升为强学习器的算法,属于集成学习的范畴。
决策树
由于GBDT中的弱学习器采用的是决策树,在这儿我们先介绍下决策树。
顾名思义,决策树对应于数据结构中的树结构,可以认为是if-then规则的集合,具有可解释性、分类速度快等优点。
决策树的学习通常包含3个步骤:特征选择、决策树的生成和决策树的修剪。
决策树由结点和有向边组成,结点有两种类型:内部结点和叶子结点,内部结点表示一个特征或属性,叶子结点表示一个类。
分类时,根据内部结点的特征对样本进行测试,根据测试结果,分配到相应的子节点,递归直到到达叶子结点,则分类为叶子结点所在的类。
互斥且完备:每一个样本都被树的一条路径(一条规则)所覆盖,而且只被一条路径所覆盖。
决策树学习的本质是从训练数据中归纳出一组分类规则,由训练数据集估计条件概率模型。
决策树学习的算法通常是一个递归地选择最优特征,并根据该特征对训练数据进行分割。
决策树常用的算法有ID3、C4.5和CART。
特征选择
特征选择在于选取对训练数据具有分类能力的特征。通常的准则是信息增益或信息增益比。
信息增益
表示得知特征X的信息而使得类Y的信息的不确定性减少的程度。
特征A对训练数据集D的信息增益 g ( D , A ) g(D,A) g(D,A),定义为集合D的经验熵与特征A给定条件下D的经验条件熵$H(D|A)
$之差,即:
g ( D , A ) = H ( D ) − H ( D ∣ A ) g(D, A) = H(D) - H(D|A) g(D,A)=H(D)−H(D∣A)
信息增益大的特征具有更强的分类能力。
信息增益比
以信息增益作为划分训练数据集的特征,存在偏向于选择取值较多的特征的问题。使用信息增益比可以对这一问题进行校正。
特征A对训练数据集D的信息增益比 g R ( D , A ) g_{R}(D,A) gR(D,A)定义为其信息增益 g ( D , A ) g(D, A) g(D,A)与训练数据集D关于特征A的值的熵 H A ( D ) H_{A}(D) HA(D)之比,即:
g R ( D , A ) = g ( D , A ) H A ( D ) g_{R}(D, A) = \frac{g(D, A)}{H_{A}(D)} gR(D,A)=HA(D)g(D,A)
基尼指数
对于给定的样本集合D,其基尼指数为:
G i n i ( D ) = 1 − ∑ k = 1 K ( ∣ C k ∣ ∣ D ∣ ) 2 Gini(D) = 1 - \sum_{k=1}^K(\frac{|C_{k}|}{|D|})^2 Gini(D)=1−k=1∑K(∣D∣∣Ck∣)2
C k C_{k} Ck是D中属于第k类的样本子集,K是类的个数。
如果样本集合D根据某特征被分隔成 D 1 D_{1} D1和 D 2 D_{2} D2两部分:则在特征A条件下,集合D的基尼指数定义为:
G i n i ( D , A ) = ∣ D 1 ∣ ∣ D ∣ G i n i ( D 1 ) + ∣ D 2 ∣ ∣ D ∣ G i n i ( D 2 ) Gini(D, A) = \frac{|D_{1}|}{|D|}Gini(D_{1}) + \frac{|D_{2}|}{|D|}Gini(D_{2}) Gini(D,A)=∣D∣∣D1∣Gini(D1)+∣D∣∣D2∣Gini(D2)
基尼指数值越大,样本集合的不确定性也就越大。
平方误差最小化
这是针对回归任务来说的,在构建回归树时进行特征选取的准则。
ID3算法是使用信息增益准则来进行特征选择。
C4.5算法是使用信息增益比准则来进行特征选择。
CART算法是使用基尼指数和平方误差最小化来进行特征选择。
决策树的剪枝
决策树生成算法递归地产生决策树,直到不能继续下去为止。这样容易出现过拟合现象。
在决策树学习中将已生成的树进行简化的过程称为剪枝。
决策树的剪枝往往通过极小化决策树整体的损失函数或代价函数来实现。
CART算法
分类回归树(classification and regression tree, CART)是应用广泛的决策树学习算法。
CART假设决策树是二叉树,内部结点特征的取值为“是”和“否”,左边分支是取值为“是”的分支,右分支是取值为“否”的分支。
CART算法由以下两步组成:
(1)决策树生成:基于训练数据生成决策树,生成的决策树要尽量大;
(2)决策树剪枝:用验证数据集对已生成的树进行剪枝并选择最优子树,这时用损失函数最小作为剪枝的标准。
分类树的构建
分类树构建与上面的ID3算法和C4.5算法类似,这里就不再叙述。
回归树的构建
一个回归树对应着输入空间的一个划分以及在划分单元上的输出值,假设已将输入空间划分为M个单元 R 1 , R 2 , … , R M R_{1},R_{2},…,R_{M} R1,R2,…,RM,并且在每个单元 R m R_{m} Rm上有一个固定的输出值 c m c_{m} cm,则回归树模型可表示为:
f ( x ) = ∑ m = 1 M c m I ( x ∈ R m ) f(x) = \sum_{m=1}^{M}c_{m}I(x\in R_{m}) f(x)=m=1∑McmI(x∈Rm)
单元 R m R_m Rm上的 c m c_m cm的最优值 m ^ c \hat m_{c} m^c是 R m R_m Rm上所有输入样本 x i x_i xi对应的输出 y i y_i yi的均值。
如何进行划分,采用启发式的方法,选择第 j j j个变量 x ( j ) x^{(j)} x(j)和它取的值,作为切分变量和切分点,并定义两个区域:
R 1 ( j , s ) = x ∣ x ( j ) ≤ s R_{1}(j, s) = {x|x^{(j)} \leq s} R1(j,s)=x∣x(j)≤s
R 1 ( j , s ) = x ∣ x ( j ) > s R_{1}(j, s) = {x|x^{(j)} > s} R1(j,s)=x∣x(j)>s
然后寻找最优切分变量 j j j和最优切分点s,具体地,求解:
m i n j , s [ m i n c 1 ∑ x i ∈ R 1 ( j , s ) ( y i − c 1 ) 2 + m i n c 2 ∑ x i ∈ R 2 ( j , s ) ( y i − c 2 ) 2 ] min_{j, s} [min_{c_{1}}\sum_{x_{i}\in R_{1}(j,s)}(y_{i}-c_{1})^2 + min_{c_{2}}\sum_{x_{i}\in R_{2}(j,s)}(y_{i}-c_{2})^2] minj,s[minc1xi∈R1(j,s)∑(yi−c1)2+minc2xi∈R2(j,s)∑(yi−c2)2]
每次在选择切分变量 j j j和切分点s时,遍历变量 j j j,对固定的切分变量 j j j扫描切分点 s s s,选择使上式达到最小值的对 ( j , s ) (j, s) (j,s)。
树构建代码
import operator
from math import log
# 计算熵
def calcEntry(dataSet):
numEntries = len(dataSet)
labelCounts = {}
for featVec in dataSet:
currentLabel = featVec[-1]
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
entry = 0.0
for key in labelCounts:
prob = float(labelCounts[key]) / numEntries
entry -= prob * log(prob, 2)
return entry
# 切分数据集
def splitDataSet(dataSet, axis, value):
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(featVec[axis:])
retDataSet.append(reducedFeatVec)
return retDataSet
# 选择最好的数据划分特征
def chooseBestFeatureToSplit(dataset):
num_features = len(dataset[0]) - 1
base_entropy = calc_entropy(dataset)
best_info_gain = 0.0
best_feature = -1
for i in range(num_features):
feat_list = [e[i] for e in dataset]
unique_val = set(feat_list)
entropy = 0.0
for value in unique_val:
subdata_set = splitDataSet(dataset, i, value)
prob = len(subdata_set) / float(len(dataset))
entropy += prob * calc_entropy(subdata_set)
info_gain = base_entropy - entropy
if info_gain > best_info_gain:
best_info_gain = info_gain
best_feature = i
return best_feature
# 选择标签最多的作为返回值
def majority_cnt(class_list):
class_count = {}
for vote in class_list:
if vote not in class_count.keys():
class_count[vote] = 0
class_count[vote] += 1
sorted_class_count = sorted(class_count.items())
key = operator.itemgetter(1, reverse = True)
return sorted_class_count[0][0]
# 创建树
def createTree(dataset, labels):
class_list = [e[-1] for e in dataset]
# 类别完全相同则停止继续划分
if class_list.count(class_list[0]) == len(class_list):
return class_list[0]
if len(dataset[0]) == 1:
return majority_cnt(class_list)
best_feat = chooseBestFeatureToSplit(dataset)
best_feat_label = labels[best_feat] # 特征名字
tree = {best_feat_label: {}}
del(labels[best_feat])
feat_val = [e[best_feat] for e in dataset]
unique_val = set(feat_val)
for val in unique_val:
sub_labels = labels[:]
tree[best_feat_label][val] = createTree(splitDataSet(dataset, best_feat, val), sub_labels)
return tree
提升树模型
采用加法模型(即基函数的线性组合)与前向分布算法,以决策树为基函数的提升方法称为提升树。
加法模型-积硅步以至千里
加法模型的基本思想是“积硅步以至千里”,就是每次学习一点,然后一步步的接近最终要预测的值(完全是gradient的思想~)。
提升树模型可以表示为决策树的加法模型:
f M ( x ) = ∑ m = 1 M T ( x ; θ m ) f_{M}(x) = \sum_{m=1}^M T(x;\theta_{m}) fM(x)=m=1∑MT(x;θm)
其中, T ( x ; θ m ) T(x;\theta_{m}) T(x;θm)表示决策树, θ m \theta_{m} θm为决策树的参数;M为树的个数
在给定训练数据及损失函数 L ( y , f ( y ) ) L(y, f(y)) L(y,f(y))的条件下,学习加法模型 f M ( x ) f_{M}(x) fM(x)称为经验风险极小化即损失函数极小化问题:
m i n θ m = ∑ i = 1 N L ( y i , ∑ m = 1 M T ( x ; θ m ) ) \underset{\theta_{m}}{min} = \sum_{i = 1}^{N}L(y_{i}, \sum_{m=1}^M T(x;\theta_{m})) θmmin=i=1∑NL(yi,m=1∑MT(x;θm))
这是一个复杂的优化问题。可以使用前向分步算法来求解这一优化问题。
前向分布算法
首先确定初始提升树 f 0 ( x ) = 0 f_{0}(x) = 0 f0(x)=0,第m步模型是:
f m ( x ) = f m − 1 ( x ) + T ( x ; θ m ) f_{m}(x) = f_{m-1}(x)+ T(x;\theta_{m}) fm(x)=fm−1(x)+T(x;θm)
树的线性组合可以很好的拟合训练数据,即使数据中的输入和输出之间的关系很复杂也是如此,所以提升树是一个高功能的学习算法。
针对不同问题的提升树学习算法,其主要区别在于使用的损失函数不同,包括用平方误差损失函数的回归问题,用指数损失函数的分类问题,以及用一般损失函数的一般决策问题。
回归问题提升树
采用平方误差损失函数时,
L ( y , f ( x ) ) = ( y − f ( x ) ) 2 L(y, f(x)) = (y-f(x))^2 L(y,f(x))=(y−f(x))2
其损失变为:
L ( y , f m − 1 ( x ) + T ( x ; θ m ) ) = [ y − f m − 1 ( x ) − T ( x ; θ m ) ] 2 = [ r − T ( x ; θ m ) ] 2 L(y, f_{m-1}(x) + T(x;\theta_{m})) = [y-f_{m-1}(x)-T(x;\theta_{m})]^2 = [r-T(x;\theta_{m})]^2 L(y,fm−1(x)+T(x;θm))=[y−fm−1(x)−T(x;θm)]2=[r−T(x;θm)]2
这里, r = y − f m − 1 ( x ) r = y - f_{m-1}(x) r=y−fm−1(x)
是当前模型拟合数据的残差,对回归问题的提升树来说,只需要简单地拟合当前模型的残差。
GBDT
当损失函数是平方损失和指数损失函数时,每一步优化是很简单的。但对一般损失函数而言,往往每一步优化并不那么容易。这时就需要用到梯度提升(gradient boosting)算法。
这是利用最速下降法的近似方法,其关键是利用损失函数的负梯度方向在当前模型的值,
− [ ∂ L ( y i , f ( x ) ) ∂ f ( x ) ] f ( x ) = f m − 1 ( x ) -[\frac{\partial L(y_{i}, f(x))}{\partial f(x)}]_{f(x) = f_{m-1}(x)} −[∂f(x)∂L(yi,f(x))]f(x)=fm−1(x)
作为回归提升树算法的残差近似值,拟合一个回归树。
梯度近似
贪心法再每次选择最优基函数时仍然困难。
将样本带入当前模型,得到 f m − 1 ( x i ) f_{m-1}(x_{i}) fm−1(xi),从而损失值为 L ( y i , f m − 1 ( x i ) L(y_{i}, f_{m-1}(x_{i}) L(yi,fm−1(xi)
此时我们可以求出梯度,然后进行更新:
f m ( x ) = f m − 1 ( x ) − r m ∑ i = 1 N δ L ( y i , f m − 1 ( x ) ) f_{m}(x) = f_{m-1}(x) - r_{m}\sum_{i=1}{N}\delta L(y_{i}, f_{m-1}(x)) fm(x)=fm−1(x)−rmi=1∑NδL(yi,fm−1(x))
上式中权值为 r r r为梯度下降的步长,使用线性搜索求最优步长。
r m = a r g m i n r ∑ i = 1 N L ( y i , f m − 1 ( x ) − r m δ L ( y i , f m − 1 ( x ) ) ) r_{m} = arg \underset{r}{min}\sum_{i=1}^N L(y_{i}, f_{m-1}(x) - r_{m}\delta L(y_{i}, f_{m-1}(x))) rm=argrmini=1∑NL(yi,fm−1(x)−rmδL(yi,fm−1(x)))
GBDT采用的是数值优化的思维,用的最速下降法去求解Loss Function的最优解,其中用CART决策树去拟合负梯度,用牛顿法求步长。
衰减(Shrinkage)
这个是把学习的大步变小步,即“真实值-预测值”*shrinkage
衰减因子:v
v = 1即为原始模型,推荐选择v<0.1的小学习率。过小的学习率会造成计算次数增多。
XGBOOST(eXtreme Gradient Boosting)
xgboost模型:和上面的GBDT模型是一致的,假设有K棵树
y ^ i = ∑ k = 1 K f k ( x i ) , f k ∈ F \hat y_{i} = \sum_{k=1}^K f_{k}(x_{i}), f_{k}\in F y^i=k=1∑Kfk(xi),fk∈F
目标函数也基本一致,不过添加了正则项:
L ( ϕ ) = ∑ i l ( y ^ i , y i ) + ∑ k Ω ( f k ) L(\phi ) = \sum_{i} l(\hat y_{i}, y_{i}) + \sum_{k}\Omega (f_{k}) L(ϕ)=i∑l(y^i,yi)+k∑Ω(fk)
同样使用前向分步算法进行学习。
所以在t轮我们可以得到:
O b j ( t ) = ∑ i = 1 n l ( y i , y ^ i ( t − 1 ) + f t ( x i ) ) + Ω ( f t ) + c o n s t a n t Obj^{(t)} = \sum_{i=1}^nl(y_{i}, \hat y_{i}^{(t-1)}+f_{t}(x_{i})) + \Omega(f_{t}) + constant Obj(t)=i=1∑nl(yi,y^i(t−1)+ft(xi))+Ω(ft)+constant
对误差函数进行二阶泰勒展开:

为什么这里要这样展开,这就是xgboost的特点了,通过这种近似,你可以自定义一些损失函数(只要保证二阶可导)。树分裂的打分函数是基于 g i , h i g_{i},h_{i} gi,hi计算的。
这样我们就得到了新的目标函数:
∑ i = 1 n [ g i f t ( x i ) + 1 2 h i f t 2 ( x i ) ] + Ω ( f t ) \sum_{i=1}^n[g_{i}f_{t}(x_{i}) + \frac{1}{2}h_{i}f_{t}^2(x_{i})] + \Omega(f_{t}) i=1∑n[gift(xi)+21hift2(xi)]+Ω(ft)
使用二阶导数的好处:
- 理论上我们知道在学什么,收敛
- 工程上: g i , h i g_{i},h_{i} gi,hi来自于损失函数且目标函数仅依赖于这两个,不用去考虑如何实现不同的损失函数(比如平方损失函数和逻辑损失函数)
重新定义树结构:
用叶子节点集合以及叶子节点得分表示。
每个样本都落在一个叶子节点上。
q ( x ) q(x) q(x)表示样本落在某个叶子节点上, w q ( x ) w_{q}(x) wq(x)表示该节点的打分,即该样本的模型预测值。
定义树的复杂度项
Ω ( f t ) = γ T + 1 2 λ ∑ j = 1 T w j 2 \Omega(f_{t}) = \gamma T + \frac{1}{2}\lambda \sum_{j=1}^Tw_{j}^2 Ω(ft)=γT+21λj=1∑Twj2
T表示树的叶子节点数。
更新目标函数:
求和下标由n变成了T。
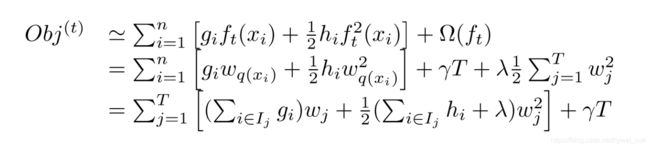
我们可以计算 w j w_{j} wj:
w j = − ∑ i ∈ I j g i ∑ i ∈ I j h i + λ w_{j} = -\frac{\sum_{i \in I_{j}}g_{i}}{\sum_{i \in I_{j}}h_{i} + \lambda} wj=−∑i∈Ijhi+λ∑i∈Ijgi
这样原目标函数就变为:
− 1 2 ∑ j = 1 T ( ∑ i ∈ I j g i ) 2 ∑ i ∈ I j h i + λ + γ T -\frac{1}{2}\sum_{j=1}^T\frac{(\sum_{i\in I_{j}}g_{i})^2}{\sum_{i\in I_{j}}h_{i} + \lambda} + \gamma T −21j=1∑T∑i∈Ijhi+λ(∑i∈Ijgi)2+γT
切分点算法
G a i n = 1 2 [ ( ∑ i ∈ I L g i ) 2 ∑ i ∈ I L h i + λ + ( ∑ i ∈ I R g i ) 2 ∑ i ∈ I R h i + λ − ( ∑ i ∈ I j g i ) 2 ∑ i ∈ I j h i + λ ] − γ Gain = \frac{1}{2}[\frac{(\sum_{i\in I_{L}}g_{i})^2}{\sum_{i\in I_{L}}h_{i} + \lambda} + \frac{(\sum_{i\in I_{R}}g_{i})^2}{\sum_{i\in I_{R}}h_{i} + \lambda} - \frac{(\sum_{i\in I_{j}}g_{i})^2}{\sum_{i\in I_{j}}h_{i} + \lambda}] - \gamma Gain=21[∑i∈ILhi+λ(∑i∈ILgi)2+∑i∈IRhi+λ(∑i∈IRgi)2−∑i∈Ijhi+λ(∑i∈Ijgi)2]−γ
这就是我们在决策树中的特征选择原则,有了这个我们就可以开始构建树。
在特征选择时,作者针对算法设计对特征进行了排序,分位点划分等,进行性能提升。
gbdt和xgboost对比
- 传统GBDT以CART作为基分类器,xgboost还支持线性分类器,这个时候xgboost相当于带L1和L2正则项的逻辑斯蒂回归(分类问题)或者线性回归(回归问题)。
- GBDT优化时只用到一阶导数信息,xgboost则对代价函数进行了二阶泰勒展开,同时用到了一阶和二阶导数。xgboost工具支持自定义代价函数,只要函数可一阶二阶求导。
- xgboost在代价函数中引入了正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、每个叶子节点上输出score的L2。使学习出来的模型更加简单,防止过拟合。
- 缩减和列采样:防止过拟合,列采样是从随机森林那边学习来的,防止过拟合的效果比传统的行采样效果还要好,并且有利于后面提到的并行化处理算法。
- 划分点查找算法
- 贪心算法获取最优切分点
- 近似算法,提出了候选分割点概念,先通过直方图算法获得候选分割点的分布情况
- 分布式加权直方图算法
- 对缺失值的处理。对于特征的值有缺失的样本,xgboost可以自动学习出它的分裂方向。稀疏感知算法。
- 内置交叉验证
- 并行化处理:各个特征的增益计算是可以并行进行的
参考文献
统计学习方法
Xgboost Slides
xgboost入门与实战(原理篇)
GBDT与Xgboost详解