对拉勾网职位信息的爬取(python)
通过发送post请求,对拉勾网的职位信息进行提取,很好的一个联系项目
知识要求:request库发送post请求,csv库的使用,常用的反爬虫,对网页数据的解析等
目地: 爬取拉勾网上python相关职位的信息
随便放一张图,输入python后,会跳出来职位,每页十五个职位,一共有三十页,那我们爬取的就是这三十页的所有职位信息。
首先,我们打开fiddler,找出职位信息在哪个文件,每个文件都找一下,https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=这个首页网站包含的响应html中并没有职位信息,那么我们接着找,在一个json文件中我们找到了这些职位的信息,如图:
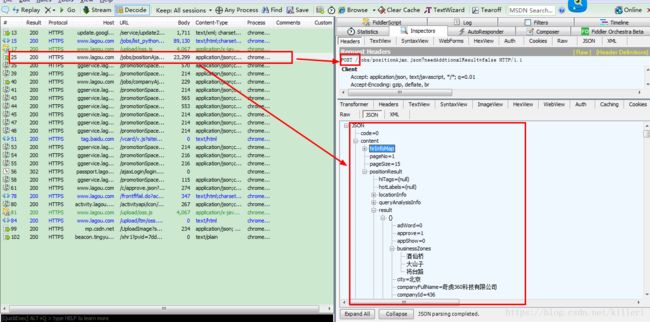
我们可以看到,这个json文件中包含了所有职位的信息,而且这个json文件是一个post请求,并不是我们常见get请求,如图,我们来看看这个post请求的请求体是什么?
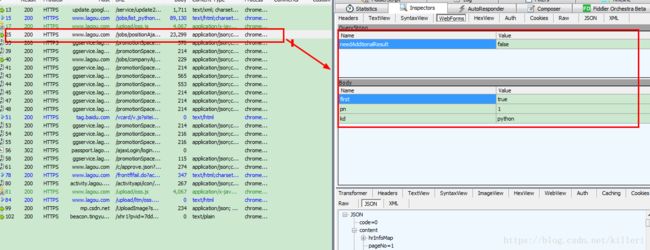
明显这个post请求的请求体有三个字段:first,pn,kd。还有一个查询字符串:needAddtionalReasult。那么我们构请求的时候就要注意加入请求体和请求的查询字符串了。
用requests库很方便
首先我们定义请求的参数:
data = {
'first' : 'false',
'pn' : pn,
'kd' : kd,
# kd参数可以改变,那么就可以提取其他关键字的信息了!
# 这是个post请求,用post的实体的pn参数当是页数
}
params = {
'needAddtionalReasult' : 'false',
# 查询字符串
}这样发送请求的话,会报错,因为我们还没有加入请求头,经检查,需要三个请求头才不会报错:
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.162 Safari/537.36',
'Host': 'www.lagou.com',
'Referer': 'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=',
# 三个首部都是必须的,不然会出现错误
}接下来就可以构造请求了,我们已经知道了职位文件的地址:
https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false
构造的请求如下:
html = requests.post(url='https://www.lagou.com/jobs/positionAjax.json',headers=HEADERS,data=data,verify=False,params=params)
# 将证书认证改为False
print('正在下载第{page}页的html'.format(page=page))
return html.json()
# requests的响应的json方法直接返回一个python字典类型上面构造了一个post请求,因为知道响应的内容是json的,所以直接调用requests响应的json方法。
好了,这样提取到了文件,那接下来就是解析json文件了,这个很简单,直接贴代码吧!
value = json_value.get('content').get('positionResult')
if 'result' in value:
result = value.get('result')
for company in result:
sleep(2)
# 适当的减慢程序的执行速度
if company.get('businessZones') != None:
businessZones =','.join(company.get('businessZones'))
else:
businessZones = None
city = company.get('city')
companyFullName = company.get('companyFullName')
companyLabelList = ','.join(company.get('companyLabelList'))
companySize = company.get('companySize')
education = company.get('education')
formatCreateTime = company.get('formatCreateTime')
positionName = company.get('positionName')
positionAdvantage = company.get('positionAdvantage')
salary = company.get('salary')
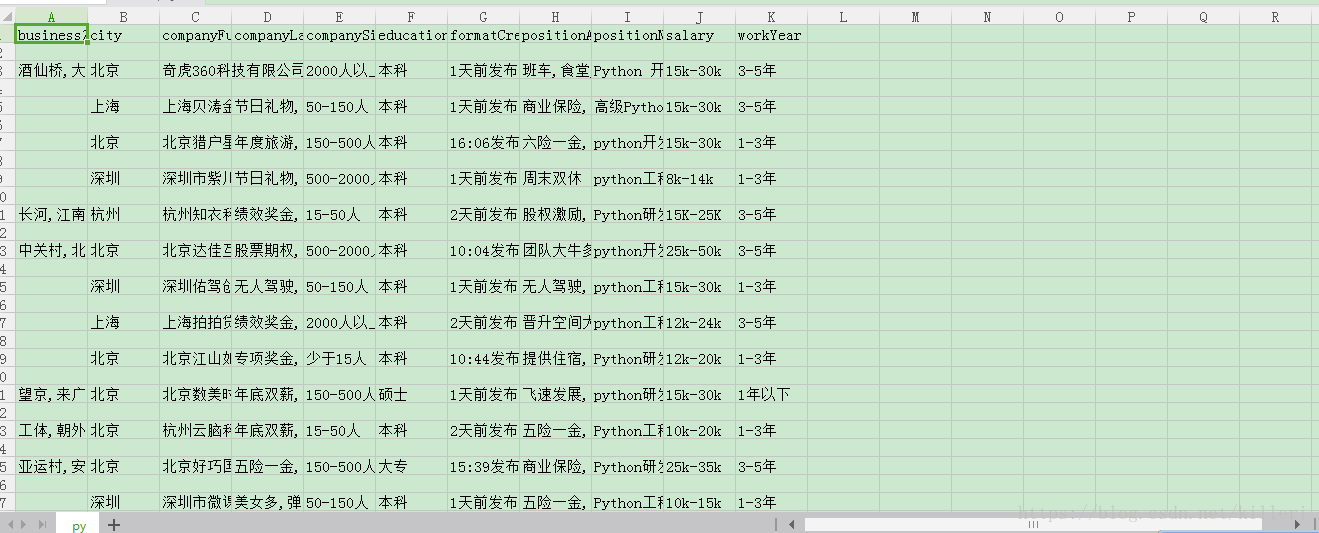
workYear = company.get('workYear')如上,我们已经解析了所有需要提取的信息,如果有耐心,你可以仔细看看我的解析过程,我详细你会有收获!!!!!
接下来一步就是将数据储存进csv文件了!
item_list = [businessZones,city,companyFullName,companyLabelList,companySize,education,formatCreateTime,positionAdvantage,positionName,salary,workYear]
print(item_list)
with open('D:/拉钩信息/lagou/lagou_file.csv','a',encoding='utf-8') as f:
writer = csv.writer(f)
# 创建一个csv的writer对象
writer.writerow(item_list)
# 逐行写入数据。这里我没有用dictwriter类,可能我觉得两者差不符哦,你可以用dictwriter类写一下,代码可能要美观一点!!
差不多,我们已经提取并存储了数据,接下来就是进行翻页就可以了。在第一行我们已经找到了post请求的实体中对于页数控制的关键字,和对查询关键字控制的关键字。实际上我们只要对这两个关键字进行改变就好了!
直接搬上我的代码:
if not os.path.exists('D:/拉钩信息/{file}'.format(file='lagou')):
os.makedirs('D:/拉钩信息/{file}'.format(file='lagou'))
# 创建文件夹
header_list = ['businessZones', 'city', 'companyFullName', 'companyLabelList', 'companySize', 'education', 'formatCreateTime','positionAdvantage', 'positionName', 'salary', 'workYear']
with open('D:/拉钩信息/lagou/python.csv', 'a', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(header_list)
f.flush()
for page in range(1,31):
try:
json = get_json('python',page)
print(len(json))
sleep(2)
parse_json(json)
except AttributeError:
print('提取第{page}页有错误'.format(page=page))这样其实我们可以查询任意关键字的职位信息,我试了一下也确实可以。比如,我可以将‘python’改为‘java’就可以查询java有关的职位信息了。
最后,附上我的结果
运行结果:
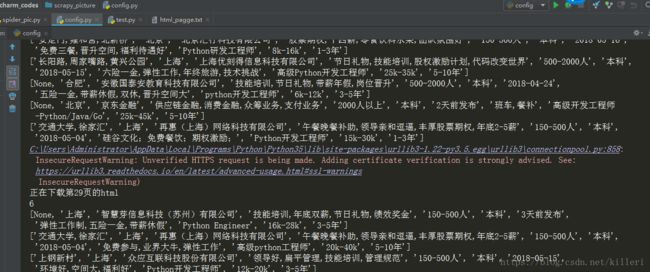
文件:
最后,欢迎各位和我交流学习~~~~~