Pix2pix:基于条件对抗网络图对图翻译
Pix2pix:基于条件对抗网络图对图翻译
我现在正在研究GAN,GAN也正是我的兴趣方向之一。
本篇要讲的是pix2pix,讲道理,那个网页版我可以玩一年
Pix2pix官网
pix2pix论文
Pix2pix的github
(注:原代码是用torch写的,但是作者也在官网提供了tensorflow版和pytorch版。起码不用面对lua这个语言)

图像翻译
“翻译”常用于语言之间的翻译,就比如中文和英文的之间的翻译。但是图像翻译的意思是以不同形式在图与图之间转换。比如,一张场景可以转换为RGB全彩图,也可以转化成素描,也可以转化为灰度图。一张夜景图也可以转化为这个地方的日景图。
传统的来说,每一种转换,比如从灰度图到素描,或者从素描到灰度图,都是需要一种特定的算法。而Pix2pix的目标就是建立一个通用的架构去解决所有的这些问题。
自编码器与CNN,为了使loss function更小而不得不使生成出来的图片模糊。这些对loss function有益的行为最终导致的是生成很假的图片(讲个道理,模糊的原因与很多自编码器采取sigmoid有没有关系?笔者觉得使用leaky relu可能会减少模糊,但是笔者试过,效果不算好)GAN提供了一种生成精准图片的方法,原因是识别网络完全能判断出模糊的图像是假图。
这在里,作者使用了条件GAN(cGAN)去学习一个条件生成模型。
方法
损失函数
cGAN的损失可以表达为:
LcGAN(G,D)=Ex,y[logD(x,y)]+Ex,z[log(1−D(x,G(x,z)))] L c G A N ( G , D ) = E x , y [ l o g D ( x , y ) ] + E x , z [ l o g ( 1 − D ( x , G ( x , z ) ) ) ]
可以看出,较普通的GAN来说,cGAN的生成网络监听了输入x。
普通的GAN的形式是
LGAN(G,D)=Ey[logD(x,y)]+Ex,z[log(1−D(x,G(x,z)))] L G A N ( G , D ) = E y [ l o g D ( x , y ) ] + E x , z [ l o g ( 1 − D ( x , G ( x , z ) ) ) ]
可以明显看出,这个形式的生成网络不需要输入x
研究表明如果给GAN加上一个传统距离(regularization?),比如L2,GAN的表现更好。而Pix2pix使用的是L1架构,可以减少模糊程度
LL1(G)=Ex,y,z[∥y−G(x,z)∥1] L L 1 ( G ) = E x , y , z [ ‖ y − G ( x , z ) ‖ 1 ]
所以最终的loss function是
G∗=argminGmaxDLcGAN(G,D)+λLL1(G) G ∗ = a r g m i n G m a x D L c G A N ( G , D ) + λ L L 1 ( G )
原版GAN中的噪音noise,在这里变成了dropout形似的
网络架构
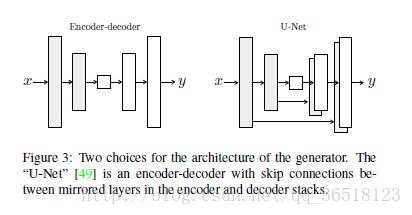
生成网络:U-net
由于是个conditional GAN,这个生成者是个自编码器(输入一张图片大小,输出一张图片大小)。但是较传统用自编码器的写法不同,作者使用了U-Net
U-Net的论文具体可以看
U-Net: Convolutional Networks for Biomedical Image Segmentation
这篇论文(虽然我没看(逃))
U-Net在Autoencoder的基础上,使用了skip-connection。这么做的原因在于很多网络需要讲input的低阶信息分享给output。
skip-connection的特点在于将decoder和encoder连接起来。貌似与ResNet的链接有一定相像,都是相加(不确定,如果有大佬矫正的话请评论)。从上图也可以看到U-net的架构。
识别网络: PatchGAN
L2 损失比L1损失更加容易产生模糊效益。所以在网络架构上我们会采取L1去解决问题。
因为我们已经可以通过L1获取低频的结构,我们想要获取高频出现的架构。于是我们采取了PatchGAN的架构。PatchGAN只会去判定每一个每一个小的 N∗N N ∗ N 的Patch中的结构是真或假并且惩罚它。并且计算平均数作为最终的结果。
这是个马尔科夫过程,也可以理解为风格损失(局部的)
优化和推断
优化没啥可说的,mini batch SGD
推断注意使用了dropout和batch normalization。training batch 被设为1,这个操作被叫做“instance normalization”
实验
一般为了效率我不喜欢看Experiment部分……很多Experiment都是作者自己吹比……但是这个Experiment不知道有多劲爆……
评价标准
两种手法
Amazon Mechanical Turk(AMT)
这个……感觉事50个Turker去评价算法生成……
感觉这个是真人评价……有点屌……
FCN-score
是采用的语言分段的算法做的评价
一些实验的结论:
生成网络:U-Net的效果是最好的
识别网络:L1+cGAN的效果比L1/L1+GAN/cGAN/GAN都好
PatchGAN的N:在70的时候表现是最好的

可以看出在 1∗1 1 ∗ 1 –> 16∗16 16 ∗ 16 的趋势下图像越来越清晰,并且FCN-score逐渐增高,颜色以越来越相近,到 70∗70 70 ∗ 70 打到顶峰。但是较 70∗70 70 ∗ 70 , 286∗286 286 ∗ 286 的画质非常差而且FCN-score非常低。可能是由于 286∗286 286 ∗ 286 需要太多参数,训练复杂
顺便提一点,这个网络的目的不是与输入图相同,而是做出一个以假乱真的假图,所以不会与原图经行任何比对。可以说生成图和原图是独立的。
在颜色上,L1会使图像便暗(我的理解是L1的稀疏性会使图像朝变暗的趋势靠拢),而cGAN完全没有这个问题。所以L1+cGAN可以保持生成图片颜色的鲜艳。
最后就是这个网络的结果,非常有意思

还有我自己画的“猫”(我知道有点吓人……)

