与“学习”相关的技巧
1、参数更新:最优化即解决寻找最优参数的问题,神经网络进行最优化比较困难是因为参数空间非常复杂,无法轻易找到最优解。为了寻找最优参数,将参数梯度作为线索,使用参数梯度沿着梯度方向更新,并不断重复直至逐渐靠近最优参数的过程称为随机梯度下降法SGD,除此之外还有其他最优化方法。
2、随机梯度下降法SGD:把需要更新的参数记为W,把损失函数关于W的梯度记为偏导,η表示学习率,用右边的值来更新左边的值朝着梯度方向前进一定距离。
![]()
class SGD:
def __init__(self,lr=0.01):
self.lr = lr
def update(self,params,grads):
for key in params.keys():
params[key] -= self.lr * grads[key]
缺点——如果函数的形状非均向,比如呈延伸状,搜索路径会十分低效,梯度的方向并没有指向最小值方向,可以使用Momentum、AdaGrad、Adam进行取代。
3、Momentum:即动量的意思,与物理有关,出现的新变量v对应物理上的速度,公式表示的是物体在梯度方向上受力,导致物体的速度在力的作用下开始增加,在物体不受任何力时,αv表示物体受到地面摩擦或者空气阻力而逐渐减速。
![]()
class Momentum:
def __init__(self,lr=0.01,momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None
def update(self,params,grads):
if self.v is None:
self.v = {}
for key,val in params.items():
self.v[key] = np.zeros_like(val)
for key in params.keys():
self.v[key] = self.momentum*self.v[key] - self.lr*grads[key]
params[key] += self.v[key]
4、AdaGrad:在神经网络的学习中学习率的值很重要,过小会导致学习花费过多时间,过大会导致学习发散而不能正确进行。所参考的学习率衰减即随着学习的进行,使学习率逐渐减小,相当于将全体参数的学习率值一起降低,而AdaGrad进一步发展了这个想法,针对每一个参数赋予特定的值,为参数的每个元素适当地调整学习率,与此同时进行学习。
新变量h保存所有梯度值的平方和,更新参数时乘以(1/sqrt(h))可以调整学习尺度,按照参数元素进行学习率衰减,使变动大的参数的学习率逐渐减小。
![]()
class AdaGrad:
def __init__(self,lr=0.01):
self.lr = lr
self.h = None
def update(self,params,grads):
if self.h is None:
self.h = {}
for key,val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] += grads[key] * grads[key]
params[key] -= self.lr * grads[key] /(np.sqrt(self.h[key])+1e-7) #防止0做除数
AdaGrad记录的是过去所有梯度的平方和,学习越深入,更新幅度越小,无止境的学习会导致更新量变为0,完全不再更新。使用RMSProp方法可以改善这个问题,在计算时会逐渐遗忘过去的梯度,做加法运算时会注重反映新梯度的信息,这种操作称为“指数平均移动(呈指数函数式地减小过去梯度的尺度)”。
5、Adam:将Momentum与AdaGrad融合在一起,通过组合两个方法的优点,有望实现参数空间的高效搜索,此外还可以进行超参数的“偏置校正”,可以根据损失函数对每个参数的梯度的一阶矩估计和二阶矩估计动态调整针对于每个参数的学习速率。
四种最优化方法的对比:
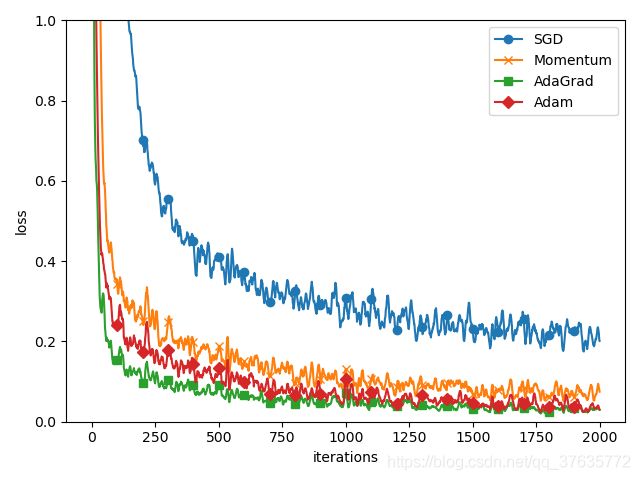
6、权值衰减:是一种抑制过拟合、提高泛化能力的技巧,以减小权重参数值为目的进行学习。为了防止“权重均一化”必须随机生成初始值,不能在一开始设置为0。
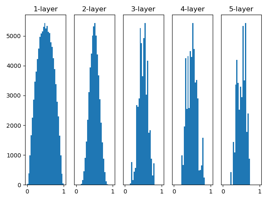
7、隐藏层激活值的分布:观察隐藏层的激活值(激活函数的输出数据)的分布,可以获得很多启发,参考实验采用的是向一个5层神经网络传入随机生成的输入数据,用直方图绘制各层激活值的数据分布。假设神经网络有5层,每层100个神经元,用高斯分布随机生成1000个数据作为输入数据并传给5层神经网络,激活函数使用sigmoid函数,各层的激活值结果保存在activations变量中,然后将保存在activations中的各层数据画成直方图。

由图显示,各层的激活值呈偏0和1分布,所使用的sigmoid函数是S型函数,随着输出不断靠近0/1,导数值会逐渐接近0/1,因此偏向0和1的数据分布会造成反向传播中梯度的值逐渐变小,最后消失,这个问题称为梯度消失。使用标准差为0.01的高斯分布时各层的激活值分布呈集中在0.5附近的分布,但是激活值会有所偏向。
Xavier的论文中,为了使各层的激活值呈现具有相同广度的分布,推导了合适的权重尺度,如果前一层的节点数为n,则初始值使用标准差为(1/sqrt(n))的分布。使用Xavier初始值后,前一层的节点数越多,要设定为目标节点的初始值权重尺度就越小,图像显示,越是后面的层,图像越歪斜,但是会呈现比之前更有广度的分布(可采用tanh函数)。
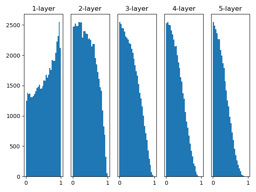
当激活函数使用ReLU时,一般使用ReLU专用初始值,也称为“He初始值”,通常使用标准差为sqrt(2/n)的高斯分布,直观解释为:因为ReLU负值区域为0,为了增加广度所以乘以2倍的系数。当激活函数使用sigmoid或者tanh等S型曲线函数(用作激活函数的函数最好具有关于原点对称性质)时,初始值使用Xavier初始值是最佳实践。
总结:在神经网络的学习中,权重初始值非常重要,很多时候直接关系到神经网络学习的成功与否。
8、Batch Normalization算法:算法思路是调整各层的激活值分布使其拥有适当的广度,为此要向神经网络中插入对数据分布进行正规化的层,即Batch Norm层,该层以进行学习时的mini-batch为单位进行正规化(使数据分布的均值为0、方差为1)。
优点:
- 可以使学习快速进行(增大学习率);
- 不过度依赖初始值;
- 抑制过拟合(降低Dropout的必要性);
数学式:
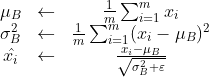
对有m个输入数据的集合B={x1,x2,…,xm}求均值μ(B)和方差σ(B)²,而ε是一个微小值,防止除数为0的情况。将这个正规化处理插入到激活函数的前面/后面,可以减小数据分布的偏向,之后Batch Norm层会对正规化后的数据进行缩放和平移变换,其中γ和β是参数(初始时γ=1,β=0,然后再通过学习进行调整)。
![]()
在使用Batch Norm后,学习进行速度加快,给予不同的初始值尺度,几乎所有情况下都会加快学习速度,表明对初始值没有依赖性;而在不使用Batch Norm的情况下,没有赋予一个好的初始值会使得学习完全无法进行。
9、过拟合——是机器学习问题中比较常见的问题,指的是只能拟合训练数据,不能很好地拟合不包含在训练数据中其他数据的状态,产生的原因主要是:模型拥有大量参数、表现力强,训练数据少。机器学习的目标就是提高泛化能力,让模型正确识别没有包含在训练数据里的未观测数据。下面使用代码展示过拟合现象(训练数据的识别精度接近100%)。
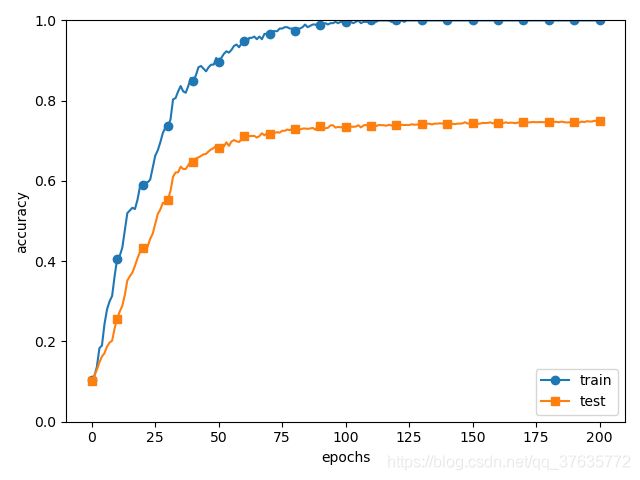
(x_train,t_train),(x_test,t_test) = load_mnist(normalize=True)
x_train = x_train[:300] #减少训练数据
t_train = t_train[:300]
network = MultiLayerNet(input_size=784,hidden_size_list=[100,100,100,100,100,100],output_size=10)
optimizer = SGD(lr=0.01)
max_epochs = 201
train_size = x_train.shape[0]
batch_size = 100
train_loss_list = []
train_acc_list = [] #以epoch为单位保存识别精度
test_acc_list = []
iter_per_epoch = max(train_size/batch_size,1)
epoch_cnt = 0
for i in range(1000000000):
batch_mask = np.random.choice(train_size,batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
grads = network.gradient(x_batch,t_batch)
optimizer.update(network.params,grads)
if i % iter_per_epoch == 0:
train_acc = network.accuracy(x_train,t_train)
test_acc = network.accuracy(x_test,t_test)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
epoch_cnt += 1
if epoch_cnt >= max_epochs:
break
10、应对过拟合的方法——权值衰减:通过在学习过程中对大的权重进行惩罚来抑制过拟合。为损失函数加上权重的平方范数(L2范数)就可以抑制权重变大,如果将权重记为W,L2范数的权值衰减就是(λ W²)/2,然后将该值加入损失函数中,λ是控制正则化强度的超参数(设置的越大对大权重施加的惩罚越严重)。
- L1范数:各个元素的绝对值之和;
- L2范数:各个元素的平方和然后开根号;
- L∞范数/Max范数:各个元素的绝对值中最大的一个。
应用权值衰减会起到抑制过拟合的作用,但是并不能起到完全抑制作用,训练数据和测试数据的识别精度还有一定差距。
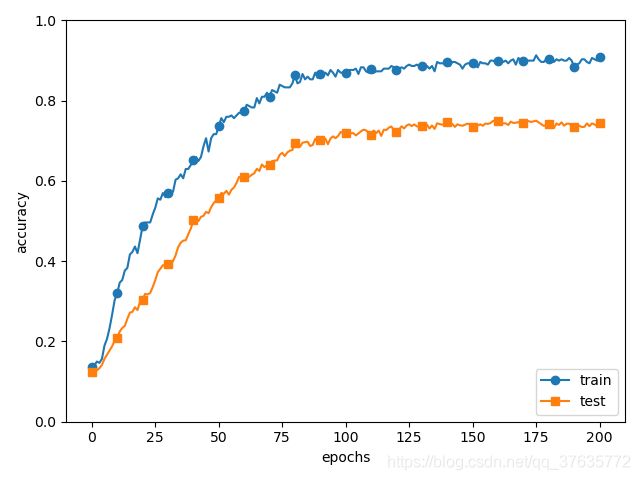
11、应对过拟合的方法——Dropout:可以更好地应对复杂网络模型,是一种在学习的过程中随机删除神经元的方法,训练时随机选出隐藏层的神经元然后将其删除,被删除的神经元不再进行信号传递。训练时每传递一次数据,就会随机选择要删除的神经元,在测试时虽然会传递所有的神经元信号,但是每个神经元输出时都会乘上训练时的删除比例再输出。
class Dropout:
def __init__(self,dropout_ratio=0.5):
self.dropout_ratio = dropout_ratio
self.mask = None
def forward(self,x,train_flag=True):
if train_flag:
self.mask = np.random.rand(*x.shape) > self.dropout_ratio
return x * self.mask
else:
x * (1.0 - self.dropout_ratio)
def backward(self,dout):
return dout * self.mask
每次正向传播时,self.mask中都以False的形式保存要删除的神经元,self.mask会随机生成和x形状相同的数组,并将值比dropout_ratio大的元素设为True,正向传播时传递了信号的神经元,反向传播时按原样传递回去,正向传播时没有传递信号的神经元,反向传播时暂停传播。

12、集成学习:让多个模型单独进行学习,推理时再取多个模型的输出平均值,通过集成学习可以让神经网络的识别精度提高好几个百分点。而Dropout与集成学习关系密切,Dropout通过在学习过程中随机删除神经元,从而每一次都让不同的模型进行学习,推理时通过对神经元的输出乘以删除比例取得模型的平均值。
13、超参数的验证:除了权重、偏置等参数,超参数(比如各层的神经元数量、batch大小、参数更新时的学习率和权值衰减等值)的取值也很重要,如果没有设定合适的值,模型的性能就会很差。
评估超参数的性能不能使用测试数据,因为如果使用测试数据进行调整,超参数的值会对测试数据发生过拟合,可能造成模型无法拟合其他数据、泛化能力较低。用于调整超参数的数据一般称为验证数据,用来评估超参数的好坏。
MNIST数据集中获取验证数据的简单方法方法是从训练数据中事先分割20%作为验证数据,在分割之前先打乱输入数据和监督标签,因为数据集中的数据可能存在偏向。
(x_train,t_train),(x_test,t_test) = load_mnist()
#打乱训练数据
x_train,t_train = shuffle_dataset(x_train,t_train)
#分割验证数据
validation_rate = 0.20
validation_num = int(x_train.shape[0] * validation_rate)
x_val = x_train[:validation_num]
t_val = t_train[:validation_num]
x_train = x_train[validation_num:]
t_train = t_train[validation_num:]
14、超参数的最优化:进行超参数的最优化时,逐渐缩小超参数“好值”的存在范围十分重要,一开始先大致设定一个范围,从这个范围中随机选择一个超参数(采样),用该值进行识别精度的评估,然后重复该操作,观察识别精度的结果,再根据该结果缩小超参数的“好值”范围,通过上述操作可以逐渐确定超参数的合适范围。
- 步骤:
①设定超参数的范围;
②从设定的超参数范围中随机采样;
③使用采样得到的超参数值进行学习,通过验证数据评估识别精度(减小学习的epoch值);
④重复上述步骤2、3,根据它们的识别精度结果缩小超参数范围。 - 实现:将学习率和控制权值衰减强度的系数作为超参数搜索对象,通过从0.001到1000这样的对数尺度范围中随机采样进行超参数的验证,进行随机采样后再使用那些值进行重复学习,观察合乎逻辑的超参数的设定值为多少。
